M02.05|資料清理與前處理:AI 專案最花時間的步驟
資料科學家 80% 的時間不是在建模型,而是在洗資料
本講學習重點
真實資料永遠是髒的,清理是模型能學到正確模式的前提
刪除、填補(平均/中位數/眾數)、用模型預測、標記為特殊類別
不一定,要先判斷是錯誤還是真實的極端值
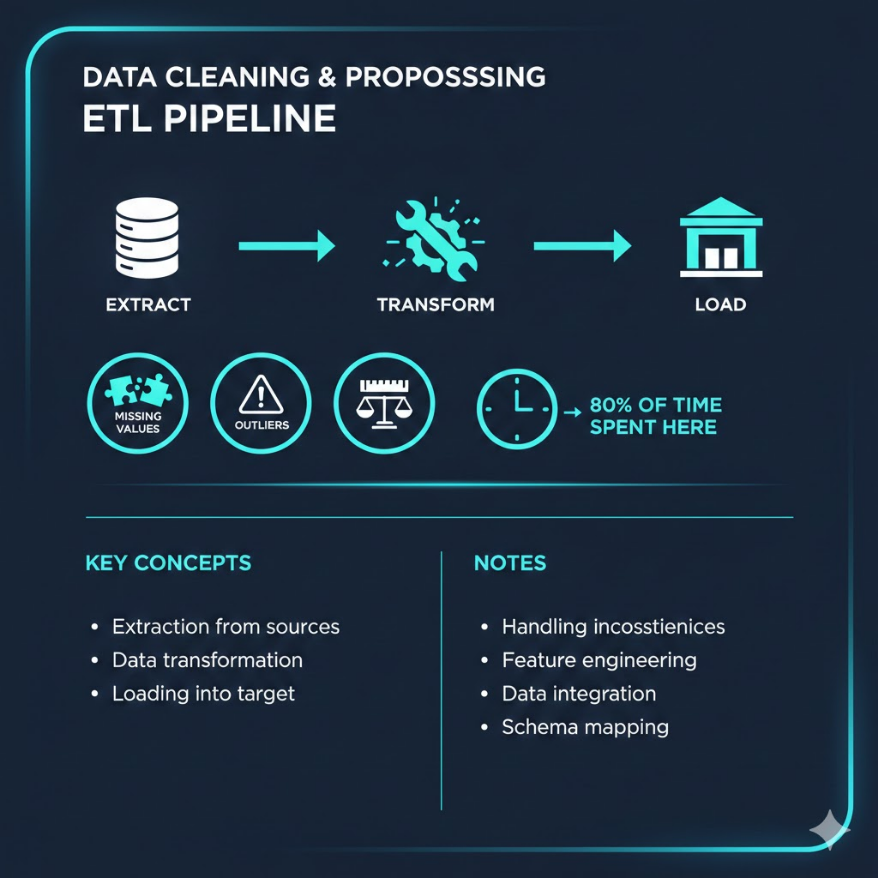
Extract擷取→Transform轉換→Load載入,資料管線三步驟
🎙️ Podcast(中文)
一句話搞懂
資料清理就是把「真實世界的髒資料」轉換成「AI 模型可以學習的乾淨資料」的過程,這通常佔了整個 AI 專案 60-80% 的時間。
白話解說
想像你買了一袋市場的蔬菜回家要煮飯。你不會直接丟進鍋裡對吧?你要先洗菜(去掉泥巴和農藥)、挑掉爛掉的葉子、把根莖切掉、大小切均勻。資料清理就是這個過程 — 真實世界的資料永遠是「帶著泥巴的蔬菜」,你必須處理乾淨才能給 AI 「煮」。
資料清理有三大核心問題要處理:
缺失值(Missing Values):你的客戶資料表裡,有些人沒有填電話、有些人沒有填地址。怎麼辦?常見做法有四種:(1) 直接刪除那一列資料(最簡單但會損失資料);(2) 用該欄位的平均值或中位數填補(適合數值型資料);(3) 用最常出現的值填補(適合類別型資料);(4) 用其他欄位的關係來預測缺失值(最精確但最複雜)。沒有一種方法是萬能的,要根據缺失比例和資料性質來選。
異常值(Outliers):銷售資料裡突然出現一筆 999,999,999 元的訂單。是系統輸入錯誤?還是真的有大客戶下了超大單?這就是異常值 — 跟其他資料差距極大的值。關鍵是:不能一看到異常值就刪掉。你要先調查它是「錯誤」還是「真實的極端情況」。如果是真實的,刪掉反而讓模型學不到重要的極端模式。
正規化(Normalization):你的資料有「年齡」(範圍 0-100)和「年收入」(範圍 0-10,000,000)。如果直接丟進模型,年收入的數值會主導一切,年齡幾乎被忽略 — 因為數值差距太大。正規化就是把不同尺度的資料縮放到同一個範圍(例如 0 到 1),讓每個特徵有公平的影響力。
這整個流程在工程實務中叫做 ETL:Extract(從各系統擷取原始資料)→ Transform(清理、轉換、整合)→ Load(載入到資料倉儲或模型訓練環境)。大型企業的 ETL 管線(Pipeline)可以非常複雜,涉及幾十個資料來源和上百個轉換步驟。
應用場景
場景:一家電商平台的訂單資料清理
一家台灣電商平台要用 AI 預測「哪些客戶下個月可能不再回購」。他們從資料庫撈出 100 萬筆訂單資料,開始清理:
| 問題類型 | 具體問題 | 處理方式 |
|---|---|---|
| 缺失值 | 5% 的訂單缺少「付款方式」 | 用「未知」填補(可能有分析價值) |
| 缺失值 | 0.3% 的訂單缺少「金額」 | 直接刪除(無法補救) |
| 異常值 | 12 筆訂單金額超過 100 萬 | 查證後確認是企業採購,保留 |
| 異常值 | 3 筆訂單日期是 1970-01-01 | 確認是系統錯誤(Unix 時間戳初始值),刪除 |
| 格式不一 | 手機號碼有「0912-345-678」和「0912345678」 | 統一移除橫線 |
| 重複紀錄 | 2% 訂單因退款重推產生重複 | 依訂單號去重,保留最新狀態 |
| 正規化 | 金額範圍 $1 ~ $500,000 | Min-Max 正規化到 0-1 |
清理前後的資料量:100 萬 → 96.5 萬筆(刪除了 3.5%)。但剩下的 96.5 萬筆乾淨資料,比原本 100 萬筆髒資料訓練出的模型好得多。
常見誤區
-
「資料清理是一次性工作」 — 如果你的模型持續接收新資料,清理就是持續性的工作。你需要建立自動化的資料管線(ETL Pipeline),讓新進來的資料自動經過清理流程。手動清理只適合 PoC 階段。
-
「缺失值太多的欄位直接刪掉」 — 如果一個欄位有 50% 的缺失值,你的直覺是「這個欄位沒用,刪」。但有時候「缺失」本身就是資訊。例如客戶問卷中「年收入」欄位的高缺失率,可能暗示「不願透露年收入的客戶」有特定的消費模式。把缺失當作一個類別來處理,可能比刪掉更好。
-
「所有資料都要正規化」 — 不是所有模型都需要正規化。決策樹和隨機森林不受特徵尺度影響,不需要正規化;但 SVM、KNN、神經網路則需要。選擇正規化方法也很重要 — Min-Max 適合分布均勻的資料,Z-Score 適合常態分布的資料。
小練習
- 缺失值策略選擇:以下三種情境,你會用哪種缺失值處理策略?說明理由。
- (a) 客戶資料表中,10% 的「生日」欄位為空
- (b) 感測器資料中,0.1% 的溫度讀數為空(每秒一筆)
- (c) 問卷調查中,60% 的「月收入」欄位為空
- 異常值判斷:你的電商資料中出現以下異常值,哪些應該刪除、哪些應該保留?
- (a) 訂單金額 = -500 元
- (b) 訂單金額 = 3,000,000 元
- (c) 購買數量 = 10,000 個(某日用品)
- (d) 訂單時間 = 2099-12-31