M02.06|特徵工程:把原始資料變成模型看得懂的語言
原始資料是生肉,特徵工程是料理 — 同樣的食材,手藝不同差很多
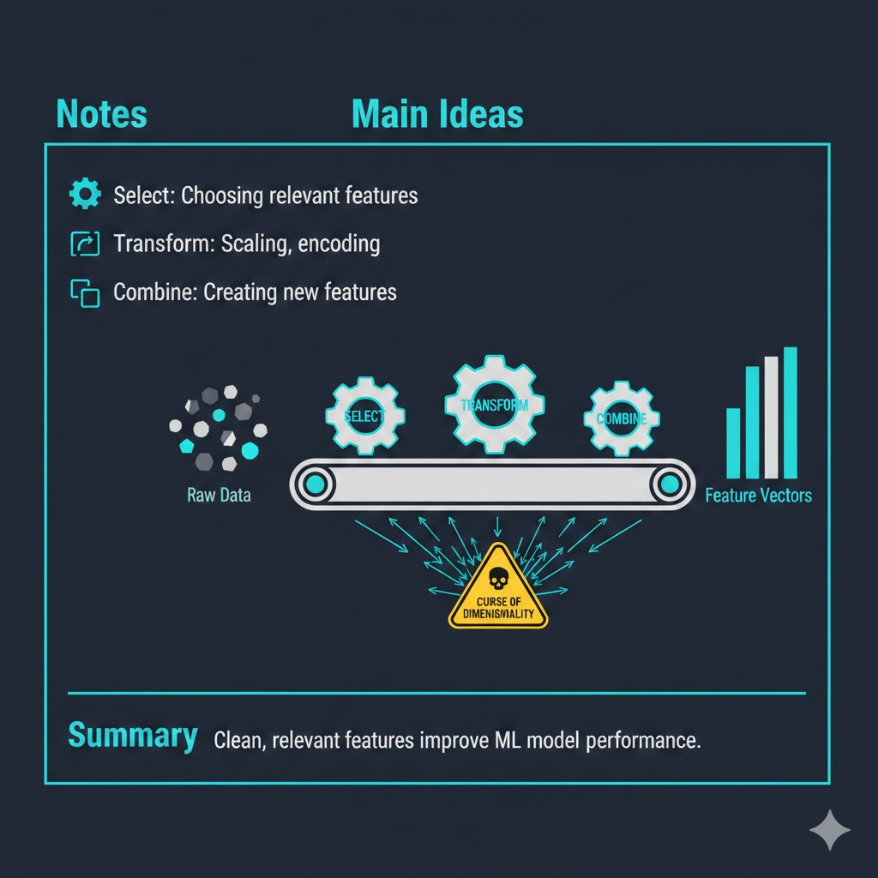
本講學習重點
模型用來做預測的輸入變數,例如年齡、收入、購買次數
選擇、萃取、轉換、組合特徵,讓模型更容易學到規律
特徵太多反而讓模型混亂,效果更差,需要降維
DL自動學特徵,但領域知識引導仍能大幅提升效果
🎙️ Podcast(中文)
一句話搞懂
特徵工程就是把原始資料加工成「模型容易學習的格式」— 好的特徵能讓簡單的模型表現得比複雜模型還好。
白話解說
你去看房子,房仲給你一堆資料:地址、坪數、屋齡、樓層、格局、社區名稱、經緯度座標。你的大腦不會直接用「經緯度」來判斷房價,而是會轉換成「這是信義區」— 這個「轉換」的過程,就是特徵工程。
特徵(Feature) 就是模型用來做判斷的輸入欄位。原始資料裡的每一欄都可能是特徵,但不是每一欄都對預測有幫助。特徵工程的核心工作就是:從原始資料中萃取出最有用的資訊,並且轉換成模型能消化的格式。
特徵工程有幾個常見的操作:
特徵選擇(Feature Selection):100 個特徵裡面可能只有 20 個真的跟預測目標有關,其他 80 個都是噪音。特徵選擇就是找出哪些特徵最重要。常用的方法有相關性分析(跟目標的相關係數)、重要性排序(用決策樹看哪個特徵分裂效果最好)。
特徵轉換(Feature Transformation):把原始資料轉換成模型更容易消化的格式。例如把「日期」轉換成「星期幾」和「是否假日」;把「地址」轉換成「行政區」;把「出生日期」轉換成「年齡」。最經典的轉換是 One-Hot Encoding — 把類別型資料(紅、藍、綠)變成三個 0/1 欄位(是否紅=1、是否藍=1、是否綠=1),因為大多數模型只認數字不認文字。
特徵組合(Feature Crossing):把兩個特徵結合成一個新特徵。例如「身高」和「體重」單獨看都不能判斷健康狀態,但組合成「BMI = 體重/身高²」就很有意義。這需要領域知識 — 你要知道 BMI 這個公式才會想到這樣組合。
維度災難(Curse of Dimensionality) 是特徵工程的天花板:特徵越多不一定越好。當特徵數量太多(比如 10,000 個),而資料量沒有等比例增加,模型反而會被太多不相關的資訊淹沒,開始「記住噪音」而不是「學會規律」。所以適當地減少特徵數量(降維)反而能提升模型效果。
應用場景
場景:用房價預測模型理解特徵工程
一個台灣房價預測 AI,原始資料和特徵工程後的特徵對比:
| 原始資料 | 特徵工程後 | 方法 |
|---|---|---|
| 地址:台北市信義區松仁路 100 號 | 行政區=信義、距捷運=500m、學區=博愛國小 | 特徵萃取 |
| 建築完成日期:2015-03-15 | 屋齡=11 年 | 特徵轉換 |
| 總坪數:45.3 坪 | 每坪單價=88.3 萬 | 特徵組合(總價/坪數) |
| 格局:3 房 2 廳 2 衛 | 房數=3、廳數=2、衛數=2 | 結構化拆分 |
| 樓層:7 樓 / 共 15 樓 | 樓層比=0.47(中間偏低) | 特徵組合 |
| 朝向:西南 | is_南向=1, is_西向=1 | One-Hot Encoding |
透過特徵工程,原本 6 個原始欄位變成了 10+ 個有意義的特徵。其中「距捷運距離」和「每坪單價」這兩個工程化特徵,對模型預測準確度的貢獻最大 — 它們不在原始資料裡,是人類的領域知識創造出來的。
常見誤區
-
「深度學習不需要特徵工程」 — 半對半錯。深度學習(尤其是 CNN 和 Transformer)確實能自動從原始資料中學習特徵表示。但在表格型資料上,手工設計的特徵仍然能大幅提升效果。Kaggle 競賽中,即使使用深度學習,前幾名的方案通常也有大量的特徵工程。
-
「特徵越多越好」 — 維度災難的核心觀念是:如果資料量不夠大,增加特徵數量反而會讓模型變差。一個經驗法則是,每個特徵至少需要 50-100 筆資料來支撐。如果你有 1,000 筆資料,那特徵數量最好控制在 10-20 個以內。
-
「特徵工程只是技術活」 — 最有價值的特徵來自領域知識。一個懂房地產的人會知道「距離最近捷運站的步行時間」比「經緯度」更能預測房價。一個懂醫療的人會知道「BMI」比單獨的身高或體重更有診斷價值。領域專家和資料科學家的合作是特徵工程成功的關鍵。
小練習
-
特徵設計練習:假設你要預測「某員工是否會在半年內離職」,你有以下原始資料:入職日期、部門、職級、月薪、每月加班時數、年假使用天數、最近一次考績。請設計至少 5 個工程化特徵(不是直接使用原始欄位),並說明你認為它們為什麼有預測力。
-
One-Hot Encoding 練習:將以下類別型資料進行 One-Hot Encoding 轉換:
- 部門:行銷、研發、業務、人資
- 學歷:高中、大學、碩士、博士