M03.01|機器學習是什麼:讓機器自己從資料中學規則
不用寫規則,讓資料說話 — 這就是機器學習的核心精神
本講學習重點
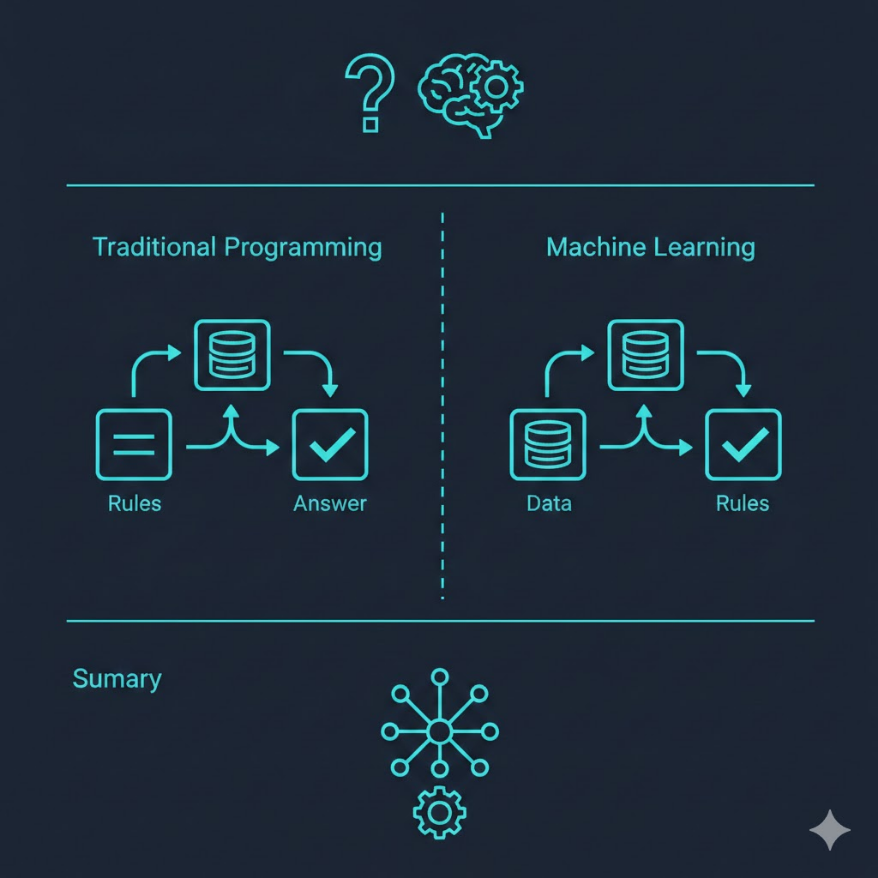
機器學習(Machine Learning, ML)是 AI 的核心子領域,讓電腦從資料中自動找出規律, 而非由人工明確撰寫規則。與傳統程式設計相反:傳統是「規則 + 資料 → 答案」, 機器學習是「資料 + 答案 → 規則」。 三大核心要素:資料(Data)、演算法(Algorithm)、模型(Model)。 主要學習類型: - 監督式學習:有標記資料,做分類或預測(垃圾郵件過濾、房價預測) - 非監督式學習:無標記資料,找群集或結構(顧客分群、異常偵測) - 強化學習:透過獎懲回饋學習最佳策略(遊戲 AI、自動駕駛) 適合 ML 的情境:規則複雜難以手寫、資料量大、需要個人化、問題會隨時間演變。
🎙️ Podcast(中文)
一句話搞懂
機器學習就是:給電腦看大量例子,讓它自己歸納出判斷規則,而不是由人來寫規則。
白話解說
傳統程式設計 vs. 機器學習:思維的根本翻轉
在傳統程式設計中,工程師必須明確告訴電腦「怎麼做」。例如要寫一個判斷垃圾郵件的程式,工程師需要手動列出規則:「如果主旨包含『免費領獎』就是垃圾郵件」、「如果寄件人不在聯絡人清單且包含連結就是垃圾郵件」……這樣的規則可能需要寫幾千條,而且隨著垃圾郵件手法不斷演變,規則就要不斷更新,永遠追不完。
機器學習的思維完全顛倒過來。我們不寫規則,而是給電腦看幾十萬封已被標記為「垃圾」或「正常」的郵件,讓演算法自己從這些例子中找出規律。電腦可能自己發現:「出現某些詞彙組合、寄件伺服器位於特定地區、且連結數量超過某個閾值的郵件,有 98% 機率是垃圾」。人類根本不需要預先知道這個規則,電腦從資料中學到了。
機器學習的學習過程:類比人類學習
想像一個剛入職的新員工學習判斷水果品質。老員工不會給他一本「品質判斷手冊」列出所有規則,而是帶著他看幾千顆水果,邊看邊說「這顆好、這顆不好」,再讓他自己試著判斷,不對了就糾正。慢慢地,新員工腦中就形成了一套判斷邏輯——雖然他自己也說不清楚這套邏輯是什麼,但他能準確判斷。機器學習做的事情本質上相同:訓練資料就是那幾千顆水果,標記(Label)就是老員工的「好/不好」,模型就是新員工腦中那套隱形的判斷邏輯。
機器學習的核心流程可以拆解為三步:第一,收集並準備資料(這往往是最耗時的部分);第二,選擇演算法並訓練模型(讓演算法在資料中找規律);第三,評估並部署模型(用沒見過的新資料測試準確度,然後上線使用)。
三種主要的學習方式
機器學習依照「資料是否有標記答案」分為三大類型。監督式學習(Supervised Learning)是最常見的:資料有明確的「正確答案」,例如房價預測(輸入房屋坪數、地點、屋齡,輸出價格)、疾病診斷(輸入症狀,輸出病名)。非監督式學習(Unsupervised Learning)則是在沒有標記的資料中自動找出群集或結構,例如把數千名顧客依消費行為分成幾個群體,讓行銷人員針對不同群體制定策略。強化學習(Reinforcement Learning)則是讓 AI 在環境中透過「嘗試—獲得獎懲—調整策略」的循環不斷優化,AlphaGo 下棋、自動駕駛車輛都屬於此類。
機器學習最閃亮的地方
機器學習特別適合以下情境:一、規則太複雜難以手寫(例如人臉辨識——你能寫出辨識人臉的所有數學規則嗎?);二、資料量龐大且持續增長(電商推薦系統每天有數億筆點擊資料);三、需要個人化(每個用戶的喜好都不同,規則無法一體適用);四、問題本身會隨時間演變(詐騙手法月月更新,模型可持續再訓練)。但機器學習不是萬靈丹——當資料量太少、問題規則本來就很清楚、或需要完全可解釋的決策(如法律裁判),傳統方法可能更合適。
應用場景
台灣零售業的客戶流失預測
某台灣連鎖超市擁有 300 萬名會員卡用戶,每個月都有一批會員「悄悄消失」——從高頻購物突然停止消費。過去門市人員只能憑直覺判斷,或者等到會員真的流失了才發現。
導入機器學習後,資料團隊蒐集了過去三年的消費記錄(每位會員的購物頻率、金額、品項類別、使用折扣券情況),訓練一個「流失風險預測模型」。模型每週自動產出高風險名單,行銷團隊提前發送個人化優惠,挽回率提升了 35%。
| 項目 | 傳統做法 | 機器學習做法 |
|---|---|---|
| 規則制定 | 人工訂定(如:連續 60 天未消費) | 模型從歷史資料自動學習 |
| 考量因素 | 有限(1-3 個指標) | 可同時分析數十個特徵 |
| 更新頻率 | 每季人工檢討 | 每月自動再訓練 |
| 準確率 | 約 55%(直覺判斷) | 約 82%(模型預測) |
| 人力需求 | 需要資深分析師 | 初期設定後自動運作 |
| 個人化程度 | 統一發送優惠 | 依個人消費習慣客製化 |
這個案例展示了機器學習的典型價值:把人類難以系統化的「直覺判斷」,轉化為可規模化、可量化的自動預測能力。
常見誤區
誤區一:「機器學習就是讓電腦變聰明,什麼都能做」
很多人聽到機器學習就以為它是無所不能的魔法。事實上,機器學習只能做它「被訓練過的任務」。一個訓練來辨識貓狗圖片的模型,遇到汽車圖片可能完全失準;一個預測股價的模型,遇到 COVID-19 這種前所未有的黑天鵝事件,表現可能一塌糊塗。機器學習的能力範圍完全受限於訓練資料的品質和範疇。沒有資料,就沒有學習;資料有偏差,學習就有偏差。
更實際的理解是:機器學習很擅長「在大量類似例子中找模式」,但它無法「理解」、「推理」或「舉一反三」(至少傳統 ML 做不到,現代大型語言模型有所不同)。把它定位為「高效的模式辨識工具」更為準確。
誤區二:「有了機器學習,資料越多越好,不需要整理」
「大資料等於好模型」是一個危險的迷思。業界有句話:「Garbage in, garbage out(垃圾進,垃圾出)」。如果訓練資料本身有問題——例如醫療紀錄的標記錯誤、顧客資料有大量重複筆數、或者資料只反映某個特定族群——那麼即使有再多資料,模型也會學到錯誤的規律,甚至放大偏見。
在實際的機器學習專案中,資料清理和特徵工程(把原始資料轉換成適合模型使用的形式)往往佔據整個專案 60-80% 的時間。資料的品質永遠比數量更重要,這也是為什麼「資料工程師」在 AI 團隊中不可或缺。
誤區三:「機器學習模型一旦訓練好就永遠有效」
許多組織在導入 AI 模型後,以為就此「一勞永逸」。事實上,機器學習模型會「過期」。這個現象叫做模型漂移(Model Drift):現實世界的資料分布隨時間改變,導致訓練時的規律在新環境中不再成立。
以台灣的疫情為例:2019 年訓練的餐廳預訂需求預測模型,在 2020 年疫情爆發後立刻失效,因為人們的消費行為發生了根本性改變,模型見過的歷史資料根本無法反映新現實。好的 ML 系統必須設計持續監控機制,定期評估模型表現,並在必要時用新資料重新訓練。機器學習不是終點,而是一個持續迭代的過程。
小練習
練習一:分辨學習類型
以下是三個台灣常見的 AI 應用場景,請判斷各屬於哪種機器學習類型(監督式、非監督式、強化學習),並說明你的理由:
- 健保署用 AI 分析全國 2,300 萬人的就醫紀錄,自動把民眾分成「健康管理需求相似」的群體,以利公衛政策制定——但這些群體是事先未定義的。
- 某電商平台收集了 100 萬筆「有詐騙」和「無詐騙」的交易紀錄,訓練 AI 對每筆新交易進行風險評分。
- 台灣某遊戲公司開發的 AI 麻將機器人,透過與自己對戰數百萬局,從每局的輸贏結果不斷調整出牌策略。
查看解答
練習二:傳統程式 vs. 機器學習,哪個更適合?
以下兩個情境,請分析各自更適合用「傳統規則程式」還是「機器學習」來解決,並說明理由:
情境 A:某公司的請假系統需要自動核算員工的剩餘假期天數。規則是:到職滿一年給 7 天,每多一年加一天,最高 30 天,育嬰假另計。
情境 B:某 HR 軟體想自動判斷履歷是否符合職缺需求,需要考量求職者的學歷、工作經驗、技能描述、過去任職公司聲譽等數十個因素,且不同職缺的重視程度各異。