本講學習重點
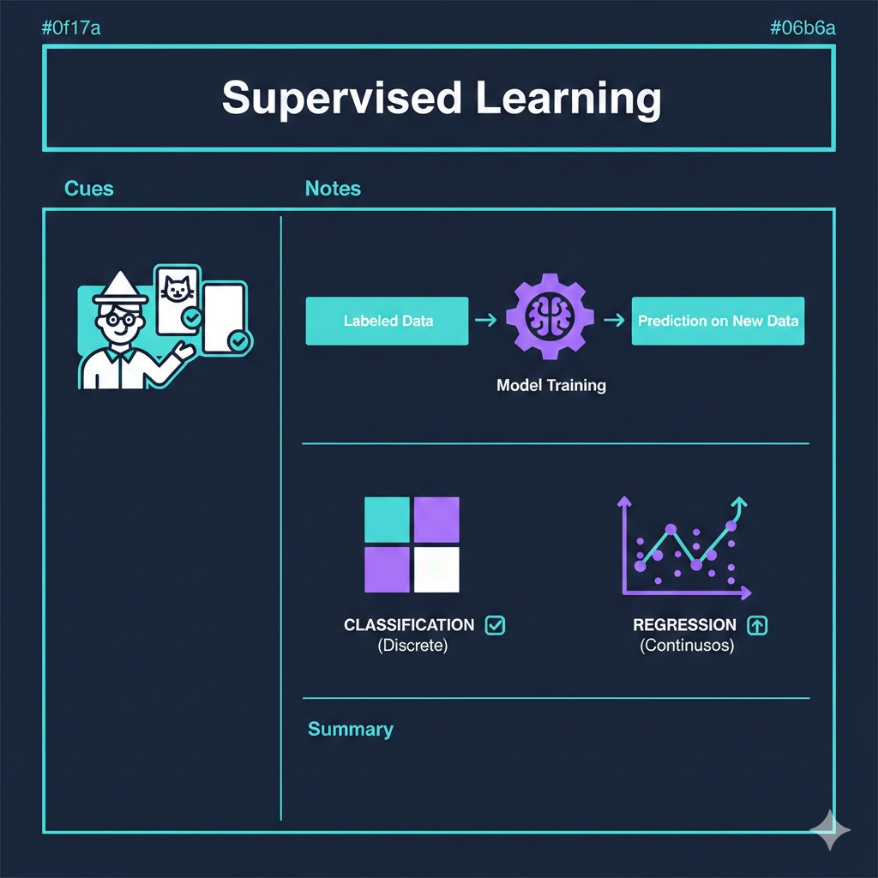
用有正確答案的歷史資料訓練模型,讓模型學會預測新資料的答案
標籤就是每筆資料附上的正確答案,例如這封郵件是垃圾信(是/否)
分類預測類別(是/否/哪一種),迴歸預測連續數值(多少錢/多少度)
訓練集用來學習,測試集模擬新資料,確認模型在沒看過的資料上也表現好
決策樹、隨機森林、邏輯迴歸、SVM、KNN — 各有適用場景
🎙️ Podcast(中文)
一句話搞懂
監督式學習就是「給 AI 一大堆附有正確答案的例題練習,讓它從中歸納規律,然後再拿沒見過的新題目來測驗它有沒有真正學會」。
白話解說
什麼是監督式學習?
你小時候學識字,媽媽指著圖卡說「這是貓」、「那是狗」,重複幾百次之後,你看到從沒見過的貓咪圖片,也能認出來。監督式學習(Supervised Learning)就是同樣的道理:給 AI 大量附有「正確答案」的例子,讓它從中找出規律,之後遇到新例子時就能自己預測答案。
這裡的「老師」就是那些標籤資料(Labeled Data)。每一筆訓練資料都包含兩個部分:
- 輸入特徵(Features):描述這筆資料的各種屬性。例如一封電子郵件的寄件者、主旨、內文關鍵字、連結數量。
- 標籤(Label):這筆資料的正確答案。例如「垃圾信」或「非垃圾信」。
有了大量這樣的資料對,AI 模型就能學到「哪些特徵組合通常對應哪個標籤」。這個學習過程,就稱為訓練(Training)。
分類 vs 迴歸:兩大任務類型
監督式學習可以解決的問題主要分兩大類:
分類(Classification):預測一個類別。答案是有限的幾個選項之一。
- 這封郵件是「垃圾信」還是「正常信」?(二元分類)
- 這張 X 光片顯示的是「正常」、「肺炎」、還是「新冠肺炎」?(多元分類)
- 這筆信用卡交易是「詐欺」還是「正常」?(二元分類)
迴歸(Regression):預測一個連續數值。答案是某個數字範圍內的值。
- 根據房屋坪數、地點、屋齡,預測成交價格是多少元?
- 根據歷史資料,預測下個月這個產品的銷售數量?
- 根據病患檢驗數值,預測血糖值?
判斷方法很簡單:答案是「選哪個」就是分類,答案是「多少」就是迴歸。
常見的監督式學習演算法
機器學習有很多種「學習規律的方法」,稱為演算法。以下是幾個最常見的:
決策樹(Decision Tree):像是一個流程圖,每個節點是一個判斷條件。例如「年收入 > 50 萬?是 → 繼續問;否 → 預測不會還款」。優點是人看得懂,可以解釋 AI 為什麼這樣預測。缺點是容易「背題」。
隨機森林(Random Forest):同時訓練數百棵決策樹,讓它們投票決定最終答案。比單棵決策樹穩定很多,是業界很常用的方法。
邏輯迴歸(Logistic Regression):名字有「迴歸」但實際上用於分類。它計算每個類別的機率,例如「這封信有 92% 機率是垃圾信」,很適合需要知道信心程度的場景。
支持向量機(SVM, Support Vector Machine):在資料點之間找一條「最大間隔的分界線」,在資料量不大但維度高時(例如文字分類)表現特別好。
K 最近鄰(KNN, K-Nearest Neighbors):預測時找資料庫裡最相似的 K 筆資料,用多數決定答案。概念最直觀:你的答案跟你最像的人一樣。
訓練集與測試集:為何要分開?
這是監督式學習最關鍵的概念之一,也是最多人忽略的。
想像一個學生把考古題全部背起來,考試時試卷剛好全是考古題,他當然得滿分。但如果出一道新題型,他就完全不會了。這叫做過擬合(Overfitting)— 模型把訓練資料「背」起來了,而不是真正學到規律。
為了避免這個問題,標準做法是把資料分成兩份:
- 訓練集(Training Set):通常佔 70-80%。模型用這部分資料學習。
- 測試集(Test Set):通常佔 20-30%。訓練完成後,用這部分資料模擬「全新資料」來檢驗模型的真實表現。
訓練集相當於「課本和練習題」,測試集相當於「期末考題」— 期末考題在訓練期間完全保密,這樣測出來的成績才能反映學生真正的程度。
進階做法會再切出一份驗證集(Validation Set),用來在訓練過程中調整模型的超參數,防止在測試集上「過度優化」。這三份資料的功能各不同,確保模型評估的公正性。
應用場景
場景:台灣中型保險公司導入理賠自動審核系統
傳統上,保險理賠申請需要理賠人員人工審核,每件平均花 3-5 個工作天。一家有三十年歷史的壽險公司,擁有二十年份的歷史理賠案件資料,決定導入監督式學習來加速審核。
資料準備:每筆歷史案件包含三十多個特徵(保戶年齡、投保金額、理賠金額、醫療診斷碼、就醫機構、投保年資、是否有附約等),以及最終審核結果(核准 / 拒絕 / 需要人工複審)。這就是訓練所需的「標籤資料」。
分兩個模型分別處理:
| 模型 | 任務類型 | 輸入 | 輸出 | 效果 |
|---|---|---|---|---|
| 理賠合理性分類 | 分類(三元) | 醫療診斷、申請金額、投保條款 | 核准 / 拒絕 / 人工複審 | 75% 案件自動決定,準確率 93% |
| 理賠金額合理性 | 迴歸 | 診斷碼、治療天數、醫院等級 | 預期合理金額範圍(元) | 偏差超過 30% 自動標記異常 |
導入後的改變:
| 指標 | 導入前 | 導入後 |
|---|---|---|
| 平均審核時間 | 3-5 工作天 | 簡單案件 < 2 小時,複雜案件 1-2 天 |
| 人工審核量 | 100% | 25%(剩餘需人工的案件) |
| 疑似詐欺偵測率 | 靠個人經驗,不穩定 | 較原本提升 2.3 倍 |
| 客戶滿意度 | 6.2 / 10 | 8.1 / 10 |
關鍵學習:有二十年標籤資料是最大的優勢,但資料工程師花了三個月清理資料(統一診斷碼格式、補齊缺漏欄位),才讓模型訓練出有意義的結果。「資料品質」遠比「演算法選擇」重要。
常見誤區
-
「訓練準確率很高就代表模型很好」 — 訓練準確率高只能說明模型「記住了訓練資料」,完全不能代表它在真實情況下的表現。正確的衡量指標是測試集準確率。更嚴格的做法是在完全隔離的「正式上線後收集到的新資料」上驗證表現。若訓練準確率 99%、測試準確率 72%,這就是嚴重的過擬合,模型根本沒有學到真正的規律,需要重頭檢查資料和模型設定。
-
「監督式學習需要的標籤資料隨便找找就有」 — 標籤資料往往是監督式學習最難取得的部分。標籤必須是可靠的正確答案,許多場景需要領域專家手動標注。例如要訓練一個辨識X光片的AI,需要放射科醫師逐一標注每張圖片,成本極高。有些公司誤以為「只要把歷史資料餵進去就能訓練」,卻忽略了歷史資料裡的標籤本身可能是錯的或不一致的。
-
「選最複雜的演算法效果一定最好」 — 許多人以為神經網路、深度學習就一定比決策樹好。實際上,演算法選擇要看資料量、特徵型態和問題複雜度。資料量只有幾千筆、特徵都是結構化表格資料時,隨機森林或 XGBoost 的表現往往和深度學習不相上下,甚至更穩定、更容易解釋、更容易維護。業界實際上 80% 以上的監督式學習應用,用的都是這類「傳統」演算法,而非深度學習。
小練習
-
分類 vs 迴歸判斷練習:判斷以下每個業務需求屬於「分類」還是「迴歸」問題,並說明理由。
(a)根據客戶過去的購買紀錄,預測他下個月是否會流失(不再購買)? (b)根據過去三年的電費帳單和氣象資料,預測下個月的辦公室電費金額? (c)根據求職者的履歷,預測他屬於哪個職級(初級 / 中級 / 資深)? (d)根據工廠感測器數據,預測設備在幾天後會需要維護?
-
訓練集 / 測試集切割練習:你的公司有一份客戶資料,包含 10,000 筆歷史貸款申請紀錄,每筆都有申請資料和最終審核結果(通過 / 拒絕)。請回答:
(a)你打算用 80% 訓練、20% 測試來切割資料。請計算訓練集和測試集各有幾筆? (b)切割時,為什麼「隨機」切割很重要?如果直接用前 8,000 筆當訓練集、後 2,000 筆當測試集,可能發生什麼問題? (c)如果訓練完成後,你的模型在訓練集上準確率 95%,在測試集上準確率只有 61%,這代表什麼?你會怎麼處理?