M03.03|非監督式學習:沒有老師,自己找規律
不告訴AI答案,讓它自己發現資料裡的隱藏結構
本講學習重點
非監督式學習(Unsupervised Learning)是讓機器在沒有標記答案的情況下, 自行從資料中發現隱藏的結構、模式與規律。三大核心技術為: (1) 分群(Clustering)— 將相似的資料點歸類到同一組; (2) 降維(Dimensionality Reduction)— 壓縮高維資料,保留關鍵特徵; (3) 異常偵測(Anomaly Detection)— 找出與大多數資料明顯不同的點。 應用場景包括顧客分群、推薦系統、詐欺偵測、主題模型等。 與監督式學習最大的差異:訓練資料沒有「正確標籤」,結果好壞需要 人類結合業務邏輯來詮釋與驗證。
🎙️ Podcast(中文)
一句話搞懂
非監督式學習就像把一堆沒有標籤的照片丟給AI,讓它自己把「長得像」的歸在一起——不告訴它答案,讓它自己找規律。
白話解說
什麼是非監督式學習?
在上一講的監督式學習中,我們給機器看了大量「有答案的例題」——例如標好了「是垃圾郵件」或「不是垃圾郵件」的信件。機器從這些例題中學習,才能判斷新的信件。
但現實世界的資料,大多數是沒有標籤的。
想像你是一家實體零售店的老闆,你有五萬筆交易紀錄,知道每個顧客買了什麼、消費多少、來了幾次,但你從來沒有給這些顧客貼過「忠誠顧客」、「一次性買家」、「折扣獵人」這樣的標籤——因為根本沒有人去做這件事。
這時候,非監督式學習(Unsupervised Learning)就派上用場了:讓機器自己去資料裡找出有哪些「自然形成的族群」,不需要人預先告訴它答案。
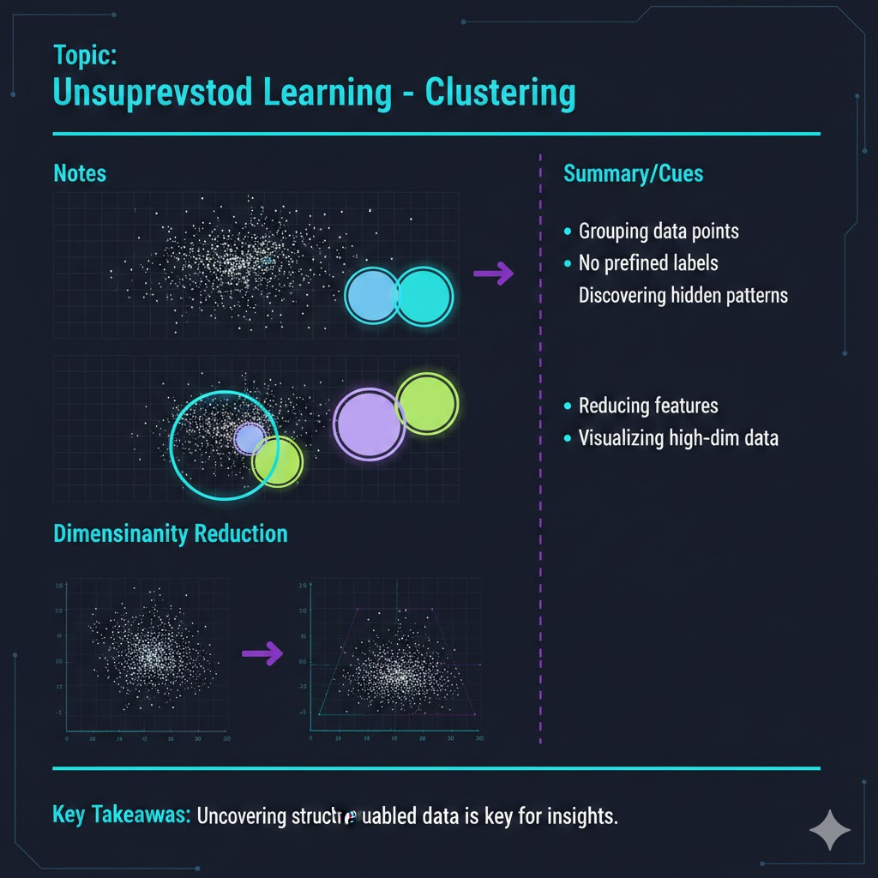
三大核心技術
1. 分群(Clustering)
分群是最常見的非監督式學習任務。目標很直覺:把「相似的東西」放在同一組,把「不同的東西」分開。
K-means 演算法是最經典的分群方法,步驟如下:
- 先決定要分幾群(K 值),例如分成 3 群
- 隨機在資料空間中放 3 個「中心點」(Centroid)
- 每一筆資料找到離自己最近的中心點,歸屬到那一群
- 重新計算每群的平均位置,更新中心點
- 重複步驟 3-4,直到中心點不再移動為止
這個過程就像是先隨便畫出幾個「集合圈」,然後不斷調整圓圈的位置,直到每個圓圈都剛好把真正相似的資料包進去。
重要觀念:K-means 需要你事先告訴它要分幾群,但「最適合的群數」本身也是一個需要探索的問題。實務上常用「手肘法」(Elbow Method)來判斷:畫出不同 K 值對應的群內誤差,找到誤差下降速度明顯趨緩的那個「手肘」位置。
2. 降維(Dimensionality Reduction)
現代資料動輒有幾十、幾百個欄位(維度)。高維度資料有幾個問題:
- 難以視覺化:人類只能直觀理解 2D 或 3D
- 計算成本高:維度越多,計算越慢
- 雜訊干擾多:很多欄位可能根本不重要
降維的目標是用更少的維度來代表資料,同時保留最重要的資訊。
主成分分析(PCA, Principal Component Analysis)是最常見的降維工具。它的核心概念是:找出資料「變化最大」的方向,沿著這些方向重新建立坐標軸。就像是把一片散落在三維空間的資料點,投影到一個最能保留這些點相對位置的二維平面上。
舉例:一份問卷有 50 道題,但其中很多題其實在問「類似的事情」。PCA 可以把這 50 個問題的資訊壓縮成 5 個「主成分」,例如第一個主成分可能代表「整體滿意度」,第二個代表「性價比感受」,讓資料更好分析。
3. 異常偵測(Anomaly Detection)
異常偵測的目標是找出「和大多數資料明顯不一樣」的點。
訓練過程中,機器先學習「正常的樣子」——大多數交易、大多數設備運作數據的模式。一旦有一筆資料和「正常模式」差距過大,就被標記為異常。
這個方法天然適合用非監督式學習,因為:
- 「正常的樣子」有很多資料可以學
- 「異常」往往很罕見,根本沒有足夠的標籤資料可以做監督式學習
應用場景:
- 信用卡詐欺偵測(某筆消費地點和時間都很異常)
- 工廠設備預防性維護(某個感測器的數值超出正常範圍)
- 資安入侵偵測(某個帳號的登入行為模式突然改變)
和監督式學習比較
| 比較面向 | 監督式學習 | 非監督式學習 |
|---|---|---|
| 訓練資料 | 需要有標籤的資料 | 不需要標籤 |
| 目標 | 預測已知類別或數值 | 發現資料的隱藏結構 |
| 評估方式 | 準確率、F1 等客觀指標 | 需結合業務判斷,無標準答案 |
| 資料準備成本 | 高(需人工標注) | 低(直接用原始資料) |
| 典型應用 | 垃圾郵件分類、房價預測 | 顧客分群、主題模型、異常偵測 |
最關鍵的差異:監督式學習的結果可以客觀衡量對不對,而非監督式學習的結果需要人類帶著業務知識去詮釋,「這樣分群有沒有意義」取決於你對問題的理解,沒有唯一正確答案。
應用場景
台灣零售業的顧客分群實戰
一家台灣連鎖便利商店累積了大量會員消費資料,決定用 K-means 分群來做「精準行銷」。以下是分析流程與結果:
使用的特徵欄位:
- 過去三個月消費總金額
- 消費頻率(每月平均幾次)
- 平均單筆消費金額
- 最常消費的時段(早/午/晚/深夜)
- 購買品項類別數量(多元程度)
K-means 分出四個族群:
| 族群名稱(人工命名) | 特徵描述 | 佔比 | 行銷策略 |
|---|---|---|---|
| 高頻忠誠族 | 消費頻率最高、單次金額中等、早午晚均有消費 | 18% | 推出點數加乘活動、優先試用新品 |
| 深夜單身族 | 深夜消費比例高、購買品項集中(泡麵、飲料) | 12% | 深夜時段推播優惠券、組合包折扣 |
| 週末大採購族 | 每月消費次數少但單次金額高、週末比例高 | 25% | 週末限定折扣、家庭組合包推薦 |
| 偶爾路過族 | 消費頻率低、金額低、品項單一 | 45% | 首購優惠、喚回活動、會員積點誘因 |
結果效益:
針對「偶爾路過族」推出「首月消費滿額送點數」活動後,這個族群的月均消費頻率提升了 34%,其中有 8% 的人轉移到「高頻忠誠族」。這份洞見完全來自資料,而非行銷人員的直覺猜測。
這個案例說明了非監督式學習的實際價值:不是機器告訴你該怎麼做,而是機器幫你「看見」原本隱藏在資料裡的族群結構,讓人類做出更有根據的決策。
其他台灣常見應用場景
- 製造業:台灣半導體廠用感測器資料做設備異常偵測,提早發現機台異常,減少非計畫性停機
- 金融業:銀行用交易資料做異常偵測,即時攔截不尋常的刷卡行為
- 電商:購物平台用購買行為分群,推薦「和你同類型的人也買了這些」
- 媒體:新聞平台用文章內容做主題分群(LDA 主題模型),自動歸類文章,提升推薦準確度
常見誤區
誤區一:以為非監督式學習不需要人工介入
許多人以為非監督式學習「全自動」,機器自己跑完就有答案。事實是,機器確實能自動找出資料的結構,但「這樣分群有沒有意義」需要人類去詮釋。K-means 把顧客分成 5 群後,這 5 群的名字、意義、對應的業務策略,都需要人類帶著業務知識去判斷。機器只是做計算,意義是人賦予的。
誤區二:分群數量(K 值)是機器自動決定的
K-means 最常見的誤解之一。K 值(要分幾群)需要人類預先指定,或透過手肘法等輔助方法來選擇,機器本身無法自動決定「最好的 K 值是幾」。選錯 K 值會導致分群結果沒有業務意義——分太少看不出差異,分太多則每群太小、難以解釋。
誤區三:非監督式學習的準確率沒辦法衡量
這個說法只對了一半。確實,非監督式學習沒有「分類正確率」這種直接指標,但有其他評估方式。例如分群質量可以用「輪廓係數」(Silhouette Score)來衡量——數值越高代表同群內的資料越相似、不同群的資料差異越大。此外,最終還是要用業務結果來驗證:分出來的族群,後續的行銷活動有沒有比不分群更有效?這才是最實際的衡量標準。
小練習
練習一:分辨學習類型
以下四個場景,哪些是非監督式學習?哪些是監督式學習?
- 銀行用歷史上已標記「詐欺/正常」的交易資料,訓練模型預測新交易是否詐欺
- 醫院將過去五年的病患資料(沒有預設分類)輸入模型,讓模型找出哪些病患有相似的病程特徵
- 電商平台根據用戶過去的點擊紀錄(沒有標籤),把用戶分成不同的興趣族群
- 用過去標注好「貓/狗/鳥」的照片,訓練一個圖片辨識模型
看解答
**非監督式學習**:場景 2 和場景 3 - 場景 2:病患資料沒有預設分類,機器自己發現相似族群 → 非監督式(分群) - 場景 3:用戶點擊紀錄沒有標籤,機器自己歸納興趣族群 → 非監督式(分群) **監督式學習**:場景 1 和場景 4 - 場景 1:有「詐欺/正常」標籤,訓練模型學習預測 → 監督式(分類) - 場景 4:照片已標注類別,訓練辨識模型 → 監督式(分類) **關鍵判斷點**:訓練資料有沒有「預先標注的正確答案」。有標籤 → 監督式;沒標籤、讓機器自己找結構 → 非監督式。練習二:分群結果的詮釋
某台灣網路書店用 K-means 對會員做分群,設定 K=3,得到以下結果:
| 族群 | 平均月消費額 | 平均月購書量 | 最常購買類別 | 會員平均年齡 |
|---|---|---|---|---|
| 族群 A | 2,800 元 | 8 本 | 文學小說 | 32 歲 |
| 族群 B | 5,200 元 | 3 本 | 商業財經 | 45 歲 |
| 族群 C | 800 元 | 1 本 | 輕小說/漫畫 | 19 歲 |
請回答:
- 你會給這三個族群取什麼名字?
- 針對族群 C,你建議什麼樣的行銷策略?
- 如果老闆說「分成 3 群感覺太少,要改成分 10 群」,你有什麼建議?