M03.04|分類 vs 迴歸:預測類別還是預測數字
分類回答是非題,迴歸回答填空題 — 搞混了模型就白訓練了
本講學習重點
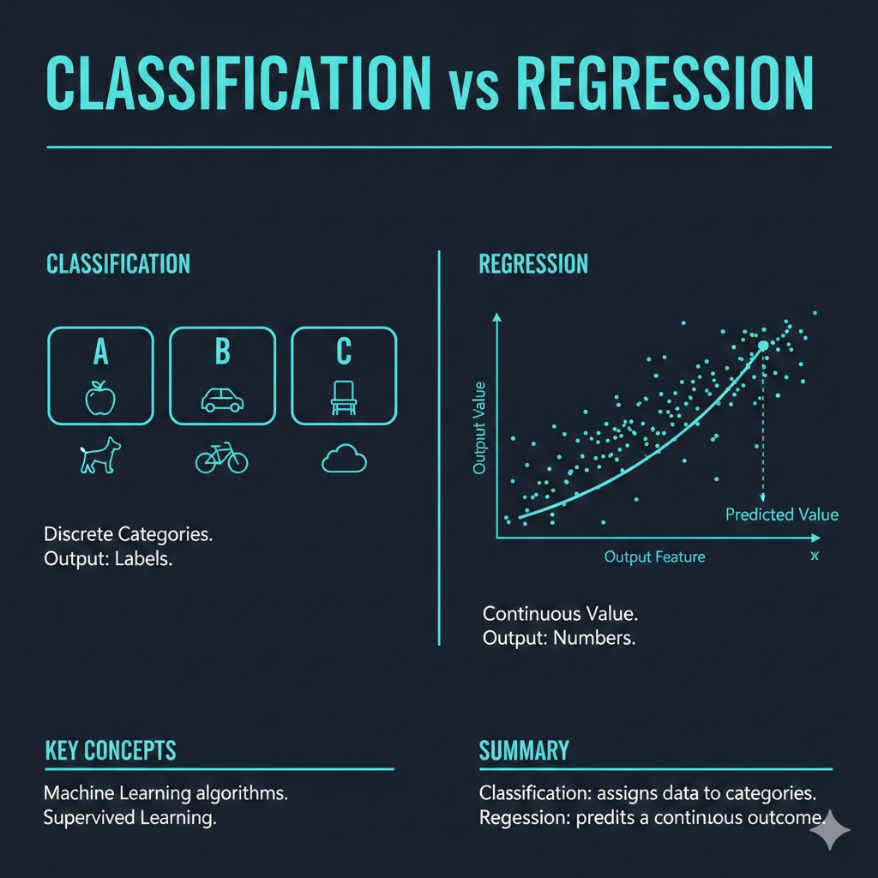
分類(Classification)和迴歸(Regression)是監督式學習的兩大任務類型, 差異在於輸出的形式: - 分類:輸出是離散標籤(類別),例如「垃圾/正常」、「貓/狗/鳥」 - 迴歸:輸出是連續數值,例如「房價 1,280 萬」、「明日氣溫 28.5°C」 判斷依據:問自己「答案是一個類別名稱,還是一個數字?」 - 是類別名稱 → 分類 - 是數字(且數字大小有實際意義)→ 迴歸 多分類(Multi-class Classification):輸出超過兩個類別, 常用策略是 Softmax,輸出每個類別的機率,取機率最高者。 閾值(Threshold):分類模型實際輸出的是機率(0~1), 預設 0.5 為分界,但依業務需求可調整: - 偵測癌症 → 降低閾值(寧可誤報,不可漏報) - 詐欺攔截 → 視誤報成本與漏報成本決定 選錯任務類型是最常見的初學者錯誤,會導致訓練出無意義的模型。
🎙️ Podcast(中文)
一句話搞懂
分類是讓 AI 貼標籤(「這封信是垃圾郵件」),迴歸是讓 AI 填數字(「這間房子值 1,280 萬」)——輸出是類別還是數值,決定了你該用哪種模型。
白話解說
最根本的差異:輸出長什麼樣子?
要區分分類和迴歸,只需要問自己一個問題:「我要預測的答案,是一個類別名稱,還是一個數字?」
如果答案是一個類別名稱——「垃圾郵件」、「良性腫瘤」、「客戶會不會流失」、「明天會不會下雨」——那就是分類(Classification)任務。分類模型輸出的是離散標籤,每個輸出都是有限選項中的其中一個,就像選擇題只能勾 A、B、C、D。
如果答案是一個有意義的數字——「這間房子值多少錢」、「明天的最高氣溫是幾度」、「這個用戶下個月會消費多少」——那就是迴歸(Regression)任務。迴歸模型輸出的是連續數值,理論上可以是任何數字,就像填空題可以填入任意合理的答案。
這個區別聽起來很簡單,但在實務中卻是最常被搞混的地方之一。搞錯了,模型就算訓練完成也毫無意義。
分類:讓模型回答是非題或選擇題
分類的核心邏輯是讓模型學習「哪些特徵組合對應到哪個類別」。訓練時,你提供大量已標記類別的資料;預測時,模型根據輸入特徵,判斷它最可能屬於哪個類別。
一個重要的細節是:分類模型實際上輸出的是「機率」,而不是直接輸出類別。以垃圾郵件偵測為例,模型可能輸出「這封信有 92% 的機率是垃圾郵件」。然後系統再根據一個閾值(Threshold)——通常預設為 0.5——來決定最終輸出的類別:機率超過 0.5 就歸類為「垃圾郵件」,低於 0.5 就歸類為「正常郵件」。
這個機率到類別的轉換步驟,在實務中非常關鍵,我們後面會詳細說明。
二元分類(Binary Classification)是最簡單的情況:只有兩個類別,非此即彼。例如:
- 信用卡交易:詐欺 / 正常
- 醫學檢驗:陽性 / 陰性
- 產品品管:合格 / 不合格
- 客戶流失預測:會流失 / 不會流失
迴歸:讓模型回答填空題
迴歸的目標是預測一個連續的數值輸出。模型學習的是「輸入特徵和輸出數值之間的數學關係」——某種程度上,就是在資料中找一條「最能描述規律的線(或曲線)」。
線性迴歸(Linear Regression)是最基礎的迴歸模型:假設輸入和輸出之間存在線性關係。以房價預測為例,模型可能學到:
房價 = 坪數 × 30萬 + 屋齡 × (-5萬) + 捷運距離 × (-2萬) + 常數項
這條公式就是模型從訓練資料中「學」出來的,每個係數(30萬、-5萬、-2萬)反映了各個特徵對房價的影響程度。當然,真實房價的預測遠比這複雜,實務上會用更複雜的非線性模型,但核心邏輯相同:輸出一個數字,且這個數字代表某種連續的量。
迴歸的評估方式和分類不同。分類看「有幾題答對」(準確率),迴歸看「答案和正確值差了多少」(誤差)。常見的迴歸評估指標包括:
- MAE(平均絕對誤差):預測值和真實值的絕對差距平均,單位和原始數據相同,例如「平均預測誤差是 50 萬元」
- RMSE(均方根誤差):對大誤差懲罰更重,如果你特別不能接受偶爾的大失誤,這個指標更合適
- R²(決定係數):表示模型能解釋多少「資料的變異性」,越接近 1 越好
如何選擇:分類還是迴歸?
判斷步驟如下:
第一步:問「答案是類別還是數字?」
如果是類別 → 分類。如果是數字 → 進入第二步。
第二步(數字的情況):數字的大小有沒有真實的「量」的意義?
有時候,問題的答案雖然是數字,但本質上是分類。例如:「病患的嚴重程度」可以用 1、2、3、4 來編碼,但這些數字代表的是類別(輕度/中度/重度/危急),1 和 2 的差距並不等同於 3 和 4 的差距——這種情況叫做「有序分類(Ordinal Classification)」,用分類模型比用迴歸模型更合適。
反之,如果數字代表真實的連續量——像氣溫、金額、距離——那就用迴歸。
第三步:思考錯誤的代價
- 分類錯誤的代價是「貼錯標籤」——把癌症患者判斷為健康
- 迴歸錯誤的代價是「偏差多少」——房價預測差了 100 萬
兩種任務的失敗模式不同,要根據業務場景選擇最能控制風險的任務類型。
多分類:選擇題不只兩個選項
當輸出類別超過兩個時,就是多分類(Multi-class Classification)問題。例如:
- 手寫數字辨識:0 到 9,共 10 個類別
- 新聞分類:政治、財經、體育、娛樂、科技……
- 語言識別:中文、英文、日文、韓文……
多分類的常見處理方式:
Softmax 函數:這是最主流的多分類輸出機制。模型最後一層對每個類別輸出一個分數,Softmax 把這些分數轉換成「加總為 1 的機率分佈」。例如辨識一張圖片,模型可能輸出:
| 類別 | 原始分數 | Softmax 機率 |
|---|---|---|
| 貓 | 3.2 | 67% |
| 狗 | 1.8 | 25% |
| 鳥 | 0.5 | 8% |
最終預測結果是機率最高的「貓」(67%)。Softmax 讓我們不只知道「模型認為是貓」,還能看出它有多確定——如果最高機率只有 35%,表示模型其實不太確定,這個資訊很有價值。
多標籤分類(Multi-label Classification)是另一種情況:一筆資料可以同時屬於多個類別。例如一篇新聞可以同時被標記為「財經」和「科技」,一張圖片可以同時包含「貓」和「狗」。這與多分類不同——多分類是「只選一個」,多標籤是「可以選多個」。多標籤分類通常拆解為多個獨立的二元分類問題來處理。
閾值調整:讓模型更符合業務需求
回到分類模型輸出機率這件事。預設閾值是 0.5,但 0.5 不一定是最好的選擇——這完全取決於你在乎什麼樣的錯誤。
先認識兩種錯誤:
- 假陽性(False Positive,FP):模型說「有」,但實際上「沒有」。例如:把正常郵件判斷為垃圾郵件。
- 假陰性(False Negative,FN):模型說「沒有」,但實際上「有」。例如:把癌症患者的檢驗結果判斷為正常。
這兩種錯誤的代價在不同場景下天差地遠:
| 場景 | 假陽性的代價 | 假陰性的代價 | 建議閾值調整方向 |
|---|---|---|---|
| 癌症篩檢 | 多做一次複查(麻煩但可接受) | 漏掉癌症患者(難以挽回) | 降低閾值,讓模型更「敏感」,寧可多誤報 |
| 垃圾郵件過濾 | 重要信件進垃圾桶(用戶抱怨) | 垃圾郵件進收件匣(小麻煩) | 提高閾值,減少假陽性 |
| 金融詐欺偵測 | 正常交易被擋下(客戶不滿) | 詐欺交易沒被攔截(損失金錢) | 視詐欺金額大小決定,高額交易可降低閾值 |
| 產品出廠品管 | 良品被退回(增加成本) | 瑕疵品流出(客訴、品牌損失) | 降低閾值,嚴格把關 |
實務操作:調閾值不需要重新訓練模型,只需要在預測結果出來後改變「機率轉類別」的那道門檻。通常工程師會畫出「ROC 曲線」或「Precision-Recall 曲線」,找出在業務需求下最佳的閾值點。
應用場景
台灣企業的分類與迴歸應用實例
| 產業 | 應用場景 | 任務類型 | 輸出範例 | 關鍵指標 |
|---|---|---|---|---|
| 金融保險 | 車險理賠審核:此次申請是否為詐欺? | 二元分類 | 詐欺(88%)/ 正常(12%) | 詐欺召回率(避免漏報) |
| 醫療 | 糖尿病視網膜病變分級:嚴重程度? | 多分類 | 無病變 / 輕度 / 中度 / 重度 / 增殖型 | 各級別的正確率 |
| 房地產 | 實價登錄估價:這間房子市值多少? | 迴歸 | 1,280 萬元(±50 萬) | RMSE(均方根誤差) |
| 製造業 | 晶圓廠良品率預測:這批晶圓良率幾%? | 迴歸 | 92.3% | MAE(平均絕對誤差) |
| 電商零售 | 顧客分級:這個顧客是哪個等級? | 多分類 | 一般 / 銀卡 / 金卡 / 鑽石 | 各級別 F1 分數 |
| 人力資源 | 員工離職預測:下季是否會離職? | 二元分類 | 高風險(73%)/ 低風險(27%) | 離職召回率(避免人才突然流失) |
| 農業 | 農產品收購量預測:下季番茄產量幾公噸? | 迴歸 | 預估 4,200 公噸(±300 公噸) | MAPE(平均絕對百分比誤差) |
| 媒體 | 新聞自動分類:這篇文章屬於哪個版面? | 多分類 | 財經(61%)/ 科技(28%)/ 其他(11%) | 準確率、F1 分數 |
關鍵觀察:同一個產業有時候既需要分類也需要迴歸。以醫療為例:「這個病人有沒有糖尿病」是分類,「這個病人的血糖值會是多少」是迴歸。兩種任務都有價值,選哪種取決於業務需求——「要做決策(打針/不打針)」→ 分類;「要做數值規劃(藥量調整)」→ 迴歸。
常見誤區
誤區一:「預測的數字就一定要用迴歸」
這是最典型的混淆。有些問題的答案雖然是數字,但本質是分類。
最常見的例子:評分系統。電影評分 1 到 5 星,如果你問的問題是「這個用戶會給幾星?」,直覺上用迴歸——因為輸出是數字。但如果你的業務問題其實是「這個用戶是否會給高分(4 星或 5 星)?」,那用二元分類更直接,模型也更容易訓練出好結果。
另一個例子:郵遞區號。如果你把台灣各縣市的行政區郵遞區號(100、200、300……)當作迴歸目標,模型會誤以為「200 和 300 的差距,等於 100 和 200 的差距」,但郵遞區號只是代碼,沒有這種數值意義。這種情況必須用分類,把每個郵遞區號當作獨立的類別。
判斷原則:數字的「大小順序和間距」是否有真實的量化意義?有 → 迴歸;只是代碼或等級 → 分類。
誤區二:「分類模型輸出 0.6 代表它很確定」
許多人看到分類模型輸出「正例機率 0.6」就認為模型已經很確定了。事實上,0.6 的確信度非常低——這表示模型其實拿不準,只比隨機猜測(0.5)好一點點。
在醫療、金融等高風險場景,模型信心度本身就是重要資訊。只輸出「分類結果」而不看機率值,會失去大量有用的資訊。好的系統應該:
- 當機率接近 0.5(例如 0.48 到 0.52)時,標記為「不確定,需要人工複審」
- 當機率極高(>0.95)或極低(<0.05)時,才允許系統自動決策
- 定期統計模型的機率校準度(Calibration)——輸出「70% 機率」的預測,是否真的有 70% 的時間是正確的?
誤區三:「用迴歸預測的數字直接當分類界線」
這個誤區常見於把迴歸輸出「硬切」成分類的情況。例如:用迴歸預測顧客的「流失傾向分數(0-100)」,然後定一個規則「分數超過 70 就聯絡挽回」。
問題在於:迴歸模型不知道你在 70 這裡做了切割,它在訓練時只優化「數值預測誤差」,不會特別讓 70 分附近的預測更準確。如果你最終目的是「要不要聯絡這個顧客」這個分類決策,直接訓練一個以「是否流失」為目標的分類模型,通常比「先迴歸再切閾值」更準確,因為分類模型的損失函數直接針對分類任務優化。
當然,迴歸分數在業務溝通上有優點(「顧客流失風險 83 分」比「高風險」更有說服力),兩種方法各有適用場景,但要清楚知道自己做的技術選擇的含義。
小練習
練習一:分類還是迴歸?
以下八個預測任務,請判斷各屬於「分類」或「迴歸」,並進一步說明是「二元分類」、「多分類」還是「迴歸」。
- 預測台灣大學生畢業後的起薪(新台幣)
- 根據 X 光片,判斷患者是否有肺炎
- 根據客服通話紀錄,自動將問題歸類到對應部門(客訴、技術支援、帳務、其他)
- 預測台北市明天的 PM2.5 濃度(微克/立方公尺)
- 判斷一則 Facebook 貼文是否為假新聞
- 根據使用者的聆聽歷史,預測他對某首歌的評分(1-5 星)
- 根據水果的糖度、重量、顏色,判斷它是荔枝、龍眼還是芒果
- 預測一個廣告活動結束後的新增會員人數
看解答
| 題號 | 任務描述 | 任務類型 | 判斷理由 | |------|---------|---------|---------| | 1 | 起薪(新台幣)| **迴歸** | 薪水是連續數值,金額大小有真實量化意義 | | 2 | 是否有肺炎 | **二元分類** | 輸出只有兩個類別:有肺炎 / 沒有肺炎 | | 3 | 客服問題分類 | **多分類** | 輸出有四個以上類別,且一次選一個 | | 4 | PM2.5 濃度 | **迴歸** | 濃度是連續數值,25.3 和 25.4 有真實差距 | | 5 | 假新聞判斷 | **二元分類** | 輸出只有兩個類別:假新聞 / 真實新聞 | | 6 | 音樂評分(1-5 星)| **有爭議,可以是迴歸或多分類** | 星數可視為連續分數(迴歸),也可視為五個等級(多分類);實務上兩種都有人用 | | 7 | 水果品種判斷 | **多分類** | 輸出是三個品種類別之一 | | 8 | 新增會員人數 | **迴歸** | 人數雖為整數,但代表連續的「量」,用迴歸預測更合適 | **音樂評分的補充說明**:1-5 星是典型的「有序分類」。如果更在意「預測誤差多少星」(例如預測 4 星但實際是 5 星,誤差 1 星),用迴歸更直觀;如果更在意「預測的類別對不對」,用多分類。實務上,Netflix 和 Spotify 的推薦系統都有用過兩種方法。練習二:閾值調整決策
某台灣保險公司開發了一個「理賠詐欺偵測模型」。目前模型設定閾值為 0.5,對 1,000 筆理賠案件的測試結果如下:
- 實際詐欺案件:100 件
- 實際正常案件:900 件
- 模型在閾值 0.5 時:
- 成功偵測詐欺(True Positive):70 件
- 漏掉的詐欺(False Negative):30 件(這 30 件被誤判為正常,照常理賠)
- 誤判為詐欺的正常案件(False Positive):45 件(這 45 件正常客戶被懷疑,需要額外調查)
- 正確通過的正常案件(True Negative):855 件
現在公司面臨兩個業務方向的考量:
方向 A:客服部門抱怨「被誤判的正常客戶很不滿,影響續保率」,希望減少假陽性。
方向 B:風控部門發現「漏掉的詐欺案件每件平均損失 50 萬元,30 件就是 1,500 萬元」,希望減少假陰性。
請問:針對方向 A 和方向 B,應該分別把閾值調高還是調低?調整後可能帶來的代價是什麼?