M03.06|模型訓練流程:從資料切割到模型驗證
訓練集、驗證集、測試集 — 三刀切下去,模型才不會自欺欺人
本講學習重點
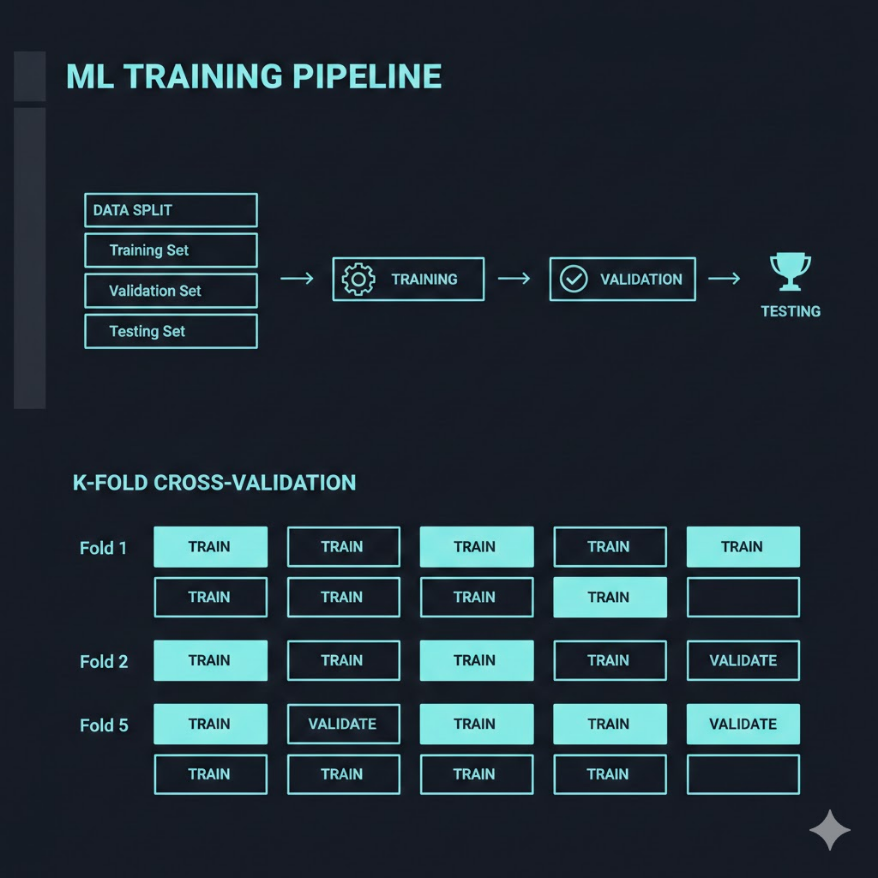
機器學習的完整訓練流程需要將資料切分為三份: (1) 訓練集(Training Set)— 約 60-70%,用來讓模型學習規律; (2) 驗證集(Validation Set)— 約 10-20%,用來調整超參數、選模型; (3) 測試集(Test Set)— 約 10-20%,最終一次性評估,模擬真實世界表現。 交叉驗證(K-Fold Cross-Validation)是更穩健的驗證方式: 把訓練資料切成 K 份,輪流用其中一份做驗證、其餘做訓練,重複 K 次取平均, 解決資料量不足時的驗證不穩定問題。 超參數(Hyperparameter)是模型訓練前需要人工設定的參數(如決策樹深度、 學習率、K-means 的 K 值),與模型從資料中學到的一般參數不同。 超參數調整必須在驗證集上進行,不能動用測試集。 完整 ML Pipeline 八個步驟: 1. 定義問題 → 2. 收集資料 → 3. 資料前處理 → 4. 切割資料集 → 5. 選擇演算法 → 6. 訓練模型 → 7. 調整超參數 → 8. 測試集最終評估 → 部署上線
🎙️ Podcast(中文)
一句話搞懂
模型訓練就像準備考試:訓練集是平時練習題,驗證集是模擬考,測試集是真正的考試——三者必須嚴格分開,才能知道你學到的是真功夫,而不是把答案背起來。
白話解說
為什麼不能把資料全部拿去訓練?
想像有一個學生在準備考試。如果他把所有考古題全部背起來,模擬考當然得滿分。但一旦考試出現稍微變化的題目,他就不知道怎麼回答了——因為他「背」的是答案,而不是「理解」了解題方法。
機器學習中,這個現象叫做過擬合(Overfitting):模型把訓練資料記得太熟,對訓練資料的預測幾乎完美,但碰到沒見過的新資料卻一塌糊塗。
解決辦法很直覺:留一部分資料不給模型看,用來測試它對「沒見過的資料」的表現。這就是資料切割的根本動機。
三份資料集的分工
標準的機器學習做法,是把原始資料集切成三份,各司其職:
訓練集(Training Set)— 約 60–70%
這是模型「上課」用的材料。所有的學習、所有參數的調整,都發生在訓練集上。資料越多,模型通常學得越好,所以訓練集通常佔最大比例。
比喻:平時的課本練習題和作業
驗證集(Validation Set)— 約 10–20%
訓練完一版模型後,用驗證集來評估它目前的表現。更重要的是,驗證集是調整超參數、選擇最佳模型架構的依據。
工程師會反覆嘗試不同的設定——比如決策樹的最大深度要設 5 層還是 10 層、學習率要設 0.01 還是 0.001——每次都在驗證集上量測結果,選出表現最好的設定。
比喻:課前測驗或模擬考,考完可以繼續調整讀書策略
關鍵規則:調整超參數的過程必須只看驗證集,不能碰測試集。一旦你「看了」測試集的結果,測試集就被「污染」了,它的分數就不再代表模型對真實世界的表現。
測試集(Test Set)— 約 10–20%
模型完全訓練好、超參數也調整完畢之後,才能動用測試集。測試集只用一次,用來模擬模型上線後面對陌生資料的真實表現。
比喻:學測或指考——只有一次機會,分數代表真實實力
測試集的黃金原則:在整個開發過程中,絕對不能用測試集來指導任何決策。只能在最後評估時打開,而且只打開一次。
切割比例的選擇
常見的切割比例有兩種設定:
| 資料規模 | 訓練集 | 驗證集 | 測試集 | 適用情境 |
|---|---|---|---|---|
| 中型資料集(萬筆以下) | 70% | 15% | 15% | 電商客服分類、房價預測 |
| 大型資料集(百萬筆以上) | 98% | 1% | 1% | 圖片辨識、語音辨識 |
| 小型資料集(千筆以下) | 改用交叉驗證 | — | — | 醫療研究、罕見疾病資料 |
為什麼大型資料集可以只留 1% 給測試集?因為百萬筆資料的 1% 就有一萬筆,已經足夠代表性。重要的是測試集的絕對數量,而非比例。
交叉驗證(K-Fold Cross-Validation)
當資料量不夠大時,隨機切出的驗證集可能「剛好」特別難或特別簡單,導致評估結果不穩定。這時需要更穩健的方法:K 折交叉驗證。
做法如下(以 5-Fold 為例):
- 把訓練資料等分成 5 份(稱為 Fold)
- 第一輪:用 Fold 2、3、4、5 訓練,Fold 1 做驗證,記錄分數
- 第二輪:用 Fold 1、3、4、5 訓練,Fold 2 做驗證,記錄分數
- 以此類推,共做 5 輪,每一份都輪流當過驗證集
- 取 5 輪分數的平均值,作為模型的最終驗證分數
原始訓練資料
┌────┬────┬────┬────┬────┐
│ F1 │ F2 │ F3 │ F4 │ F5 │
└────┴────┴────┴────┴────┘
第1輪:[驗] [訓] [訓] [訓] [訓] → 分數 81%
第2輪:[訓] [驗] [訓] [訓] [訓] → 分數 79%
第3輪:[訓] [訓] [驗] [訓] [訓] → 分數 83%
第4輪:[訓] [訓] [訓] [驗] [訓] → 分數 80%
第5輪:[訓] [訓] [訓] [訓] [驗] → 分數 82%
平均驗證分數:81%(標準差:±1.4%)
交叉驗證的優點:
- 每一筆資料都曾做過驗證,評估更全面
- 可以同時得知模型表現的「穩定性」(標準差越小越穩定)
- 特別適合小資料集,最大化每一筆資料的利用率
注意:交叉驗證用於訓練階段的超參數選擇。最終測試集依然是分開的,不進入交叉驗證的輪換。
超參數是什麼?
機器學習中有兩種「參數」,常被混淆:
| 類型 | 定義 | 由誰決定 | 範例 |
|---|---|---|---|
| 一般參數(Parameters) | 模型從訓練資料中自動學習到的數值 | 機器在訓練過程中自動調整 | 神經網路的權重、線性回歸的係數 |
| 超參數(Hyperparameters) | 訓練之前由人工設定的「學習規則」 | 工程師人工設定或自動搜尋 | 學習率、決策樹深度、K-means 的 K 值 |
白話比喻:超參數就像老師設計考試時決定「每題幾分、考幾題、時限多久」——這些規則是在考試開始前設定好的。考試過程中學生寫下的答案,才是「一般參數」。
常見超參數範例:
- 決策樹:最大深度(max_depth)、分裂所需最少樣本數(min_samples_split)
- 神經網路:學習率(learning rate)、批次大小(batch size)、隱藏層數量
- K-means:群數 K
- SVM:正則化參數 C、核函數類型(kernel)
超參數調整的方法:
- 網格搜尋(Grid Search):列出所有想試的超參數組合,逐一試完,選最好的。窮舉但保證找到格子內最優解
- 隨機搜尋(Random Search):從超參數範圍中隨機取樣組合。比網格搜尋更有效率,適合超參數空間很大的情況
- 貝葉斯最佳化(Bayesian Optimization):根據前幾次的結果,智慧地選擇下一個要試的超參數組合,效率最高
完整的機器學習流程
從資料到部署,一個嚴謹的 ML 專案包含以下八個步驟:
步驟 1:定義問題
└── 這是分類問題還是回歸問題?
成功指標是什麼?(準確率?F1?RMSE?)
步驟 2:收集與了解資料
└── 資料來源、資料量、類別平衡、時間範圍
步驟 3:資料前處理
└── 處理缺失值、異常值
類別變數編碼(One-Hot Encoding 等)
數值標準化(StandardScaler 等)
特徵工程(新增有意義的特徵欄位)
步驟 4:切割資料集
└── 先切出測試集,封存不動
剩餘部分切出訓練集和驗證集(或設定交叉驗證)
⚠️ 資料前處理的參數(如平均值)必須只從訓練集計算
步驟 5:選擇候選演算法
└── 根據問題類型、資料規模、可解釋性需求
通常選 2-3 個候選演算法比較
步驟 6:訓練模型
└── 在訓練集上訓練,記錄訓練損失曲線
監控是否有過擬合(訓練分數遠高於驗證分數)
步驟 7:超參數調整與模型選擇
└── 在驗證集(或交叉驗證)上比較不同超參數設定
選出最佳模型與最佳超參數組合
步驟 8:測試集最終評估
└── 只做一次,報告最終效能指標
這個數字代表模型在真實世界的預期表現
→ 部署上線
└── 監控線上表現,定期用新資料重新訓練
步驟 4 的重要細節——資料洩漏(Data Leakage)防護:
資料前處理時,標準化(Standardization)需要計算訓練資料的平均值和標準差。這個計算必須只用訓練集的資料,然後用同樣的平均值/標準差去轉換驗證集和測試集。
如果你用「全部資料」的平均值來標準化,驗證集和測試集的資訊就「洩漏」到了訓練過程中,評估結果會過於樂觀,上線後表現會比預期差。
應用場景
台灣電商的客戶流失預測:完整 Pipeline 實戰
一家台灣中型電商平台(年 GMV 約 15 億元)發現,每季約有 12% 的會員停止消費。行銷團隊希望提前一個月預測「哪些客戶有流失風險」,以便主動發送挽留優惠。
以下是這個 Pipeline 從頭到尾的執行過程:
問題定義
- 任務類型:二元分類(流失 / 不流失)
- 預測目標:下個月是否有消費(有 = 0,沒有 = 1)
- 成功指標:Recall(召回率)優先——寧可多發優惠券,也不能漏掉真正要走的客戶
資料概況
| 欄位類別 | 欄位範例 | 欄位數 |
|---|---|---|
| 消費行為 | 過去 30/60/90 天消費金額、次數、品項數 | 12 個 |
| 會員屬性 | 會員年資、等級、性別、居住縣市 | 6 個 |
| 互動行為 | 過去 30 天 App 開啟次數、點擊率、客服聯繫次數 | 8 個 |
| 促銷反應 | 過去 6 次促銷是否有回購、優惠券使用率 | 4 個 |
- 總資料筆數:180,000 筆(18 個月的歷史資料)
- 流失比例:12%(類別不平衡,需特殊處理)
資料切割策略
由於是時間序列性質的資料,不能用隨機切割——若隨機切割,模型可能用「未來的資料」預測「過去」,造成資料洩漏。
採用時間順序切割:
| 資料集 | 時間範圍 | 筆數 | 用途 |
|---|---|---|---|
| 訓練集 | 月1 ~ 月12 | 126,000 筆 | 模型學習 |
| 驗證集 | 月13 ~ 月15 | 27,000 筆 | 超參數調整 |
| 測試集 | 月16 ~ 月18 | 27,000 筆 | 最終評估,封存不動 |
模型訓練與超參數調整
工程師選擇三個候選演算法,在驗證集上比較:
| 演算法 | 調整的超參數 | 驗證集 Recall | 驗證集 Precision | 選用? |
|---|---|---|---|---|
| 邏輯回歸 | 正則化強度 C | 0.71 | 0.58 | 否 |
| 隨機森林 | max_depth=8, n_estimators=200 | 0.81 | 0.64 | 是 |
| XGBoost | learning_rate=0.05, max_depth=6 | 0.79 | 0.67 | 備選 |
隨機森林在 Recall(召回率)上表現最好,被選為最終模型。
測試集最終評估
封存的測試集只打開一次,得到以下結果:
- Recall(召回率):0.79(預測到的真實流失客戶比例)
- Precision(精確率):0.63(被預測為流失的客戶中真正流失的比例)
- AUC-ROC:0.87
部署效益
上線後三個月,針對模型預測的「高風險流失客戶」發送個人化挽留優惠券:
- 高風險族群挽留成功率:從原本的 23% 提升至 41%
- 每季流失率:從 12% 下降至 9.2%
- 行銷成本節省:優惠券精準投放,總優惠發放量減少 38%,效果卻更好
這個案例說明,嚴謹的 Pipeline——特別是時間順序切割和封存測試集——保證了模型上線後的表現能接近驗證階段的預測,而不是讓工程師和老闆白高興一場。
常見誤區
誤區一:用測試集調整模型,以為這樣評估最嚴格
有些初學者認為「既然測試集最難,那就直接在測試集上調整超參數,找到最好的設定就是最終答案」。這是嚴重的錯誤。每次你用測試集的結果來指導下一步決策,測試集就不再是「未知的真實世界」了——它已經被納入你的決策迴路。最後得到的測試集分數,是你針對那個特定測試集過度優化的結果,對真實世界沒有代表性。黃金原則:測試集只用一次,且只在最後。
誤區二:前處理時用全部資料的統計數字
這是最常見、最隱蔽的資料洩漏形式。假設你要做特徵標準化,用了「全部 180,000 筆資料」的平均值和標準差,包含了驗證集和測試集的資訊。這樣一來,模型在訓練時就已間接「見過」驗證集和測試集,評估分數會比真實情況樂觀 2–5 個百分點。正確做法:切割資料集之後,所有的前處理參數(平均值、標準差、編碼映射表等)都只從訓練集計算,然後套用到其他資料集。
誤區三:認為 5 折交叉驗證就不需要測試集
交叉驗證讓模型在訓練資料上的評估更穩定,但它無法取代獨立的測試集。交叉驗證的五輪結果你都看了、都用來調整超參數了——換句話說,整個訓練資料集都已經參與了決策過程。你仍然需要一個「完全沒有參與任何決策」的測試集,才能知道模型對陌生資料的真實表現。交叉驗證和測試集是互補關係,不是替代關係。
小練習
練習一:資料切割判斷
一家台灣醫院想用 AI 預測「患者出院後 30 天內是否再度住院」,收集了過去兩年共 8,000 筆住院紀錄(其中 15% 在 30 天內再住院)。資料科學家小明規劃了以下三種方案,請判斷哪一種最適合,並說明原因:
- 方案 A:隨機將資料切成 80% 訓練 / 20% 測試,直接訓練並評估
- 方案 B:隨機切成 70% 訓練 / 15% 驗證 / 15% 測試,在驗證集上調整超參數
- 方案 C:先切出最後 6 個月的資料作為測試集,剩餘 18 個月的資料用 5 折交叉驗證做訓練和驗證
看解答
**最適合的是方案 C**,理由如下: **方案 A 的問題**: - 沒有驗證集,無法調整超參數,只有一種設定直接上場,等於沒有「模擬考」 - 直接評估容易選到運氣好的單次切割結果,不夠穩健 **方案 B 的問題**: - 隨機切割忽略了時間順序。醫療資料有時間性——2024 年的用藥習慣、診斷標準可能和 2022 年不同。用「未來」的資料預測「過去」會造成資料洩漏,實際上線後表現往往比評估差 - 8,000 筆資料中,再住院的正樣本只有 1,200 筆(15%)。隨機切割 15% 做測試集,測試集中只剩約 180 個正樣本,統計代表性不足 **方案 C 的優點**: - 時間順序切割:用過去 18 個月的資料預測最近 6 個月,貼近真實部署情境 - 5 折交叉驗證充分利用了有限的訓練資料(8,000 筆不多),評估更穩健 - 測試集完全封存,不參與任何超參數調整決策 **額外注意**:由於正樣本只佔 15%,訓練時應使用類別權重(class_weight='balanced')或過採樣(SMOTE)來處理類別不平衡問題。練習二:找出 Pipeline 中的錯誤
下面是一個工程師小華的機器學習流程描述,其中藏有兩個嚴重錯誤,請找出來並說明如何修正:
小華收集了 50,000 筆電商訂單資料,想預測客戶是否會退貨。 他首先對全部 50,000 筆資料進行標準化(計算全體的平均值和標準差), 然後將標準化後的資料隨機切成訓練集 70%、驗證集 15%、測試集 15%。 訓練了三個模型後,他在驗證集上選出最好的模型。 接著他發現測試集分數比驗證集低了 5 個百分點, 覺得不夠好,於是調整了一些超參數後在測試集上重新評估, 得到更好的分數後滿意地向老闆報告。