M03.07|過擬合與欠擬合:模型的兩大死因
背考古題的學生和完全沒讀書的學生 — 都考不好
🎙️ Podcast(中文)
一句話搞懂
過擬合是把訓練資料「背起來」卻不會舉一反三;欠擬合是模型太簡單、連訓練資料的規律都學不起來 — 兩者都會讓模型在真實世界中失敗。
白話解說
從考試說起
想像班上兩種極端的學生:
- 死背型:把去年所有考古題答案背得滾瓜爛熟,但換一道新題就傻眼。這就是過擬合(Overfitting)。
- 完全不讀型:什麼都沒準備,任何題目都答不出來。這就是欠擬合(Underfitting)。
真正能考好的學生,是那個理解原理、融會貫通的人。機器學習模型的目標也一樣。
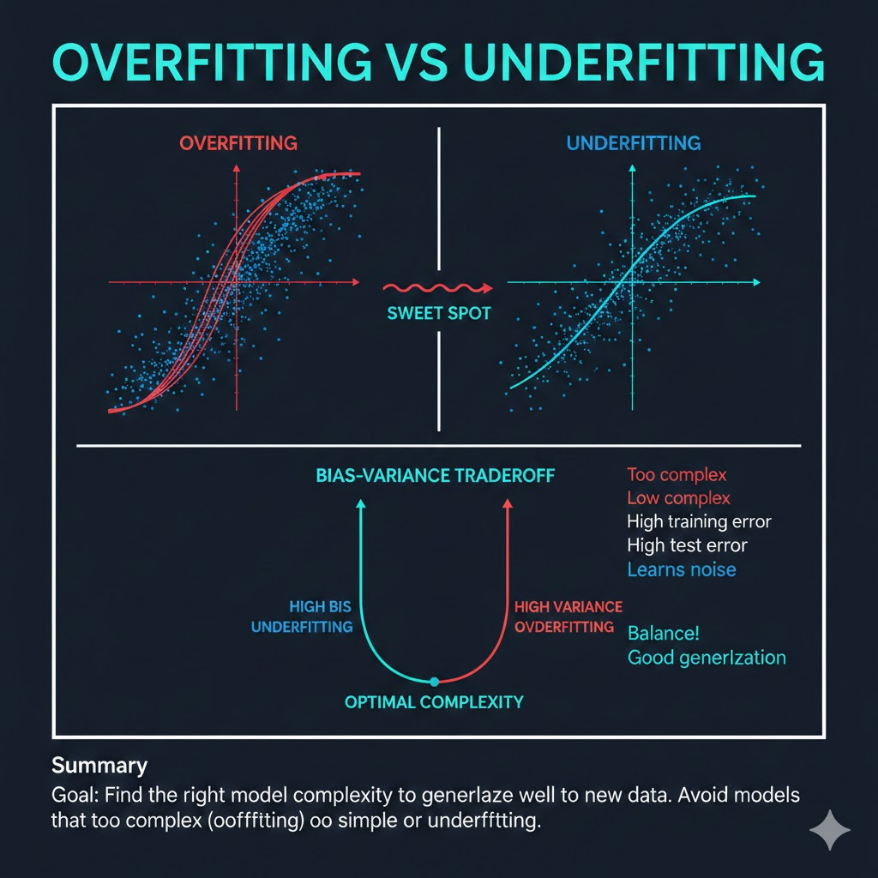
過擬合(Overfitting):記憶而非學習
過擬合發生時,模型把訓練資料中的每個細節 — 包括雜訊(noise)和例外情況 — 都當成真實規律記住了。
具體症狀:
- 訓練集準確率:98%
- 測試集準確率:62%
- 兩者差距極大(稱為「泛化差距」)
常見原因:
- 模型過於複雜(參數太多)
- 訓練資料太少
- 訓練時間過長(過度迭代)
誤差
高 |* ← 過擬合區域(訓練誤差低、測試誤差高)
| *
| * ___________ ← 測試集誤差曲線
| ___________
| ___________ ← 訓練集誤差曲線
低 |____________________________
簡單 → 模型複雜度 → 複雜
欠擬合(Underfitting):太懶、太簡單
欠擬合發生時,模型連訓練資料的基本規律都學不起來,就像用一條直線去描述一個拋物線形的資料。
具體症狀:
- 訓練集準確率:61%
- 測試集準確率:60%
- 兩者差距不大,但表現都很差
常見原因:
- 模型太簡單(特徵或層數不足)
- 訓練時間太短
- 特徵工程不足,重要資訊沒有輸入模型
偏差與變異數的取捨(Bias-Variance Tradeoff)
這是機器學習中最核心的概念之一:
| 概念 | 定義 | 對應問題 |
|---|---|---|
| 偏差(Bias) | 模型對真實答案的系統性偏移,模型假設太簡單 | 欠擬合 |
| 變異數(Variance) | 模型對訓練資料微小變動的敏感程度 | 過擬合 |
關鍵洞見:降低偏差往往會提高變異數,反之亦然。我們的目標是找到兩者的最佳平衡點。
總誤差 = 偏差² + 變異數 + 不可避免的雜訊
欠擬合:高偏差 + 低變異數
過擬合:低偏差 + 高變異數
理想: 低偏差 + 低變異數(需要好的模型與足夠的資料)
解決過擬合的方法
1. 增加訓練資料 最直接的方式。資料越多,模型越難「背答案」。
2. 資料增強(Data Augmentation) 對現有資料進行旋轉、翻轉、加入輕微雜訊等變換,人工擴充資料集。在影像辨識中常用。
3. 正規化(Regularization) 在損失函數中加入「懲罰項」,讓模型傾向於使用較小的參數值,避免過度擬合細節。(詳見下方)
4. Dropout 在神經網路訓練時,隨機「關掉」一部分神經元,強迫網路學習更穩健的特徵,不依賴特定路徑。
5. 早停法(Early Stopping) 監控驗證集誤差,當驗證集誤差開始上升時立刻停止訓練,避免繼續過擬合。
6. 減少模型複雜度 使用更少的層、更少的節點,或更少的特徵。
解決欠擬合的方法
1. 增加模型複雜度 增加神經網路的層數、節點數,或使用更強大的模型架構。
2. 更好的特徵工程 提供更多有意義的輸入特徵,讓模型有足夠的資訊可以學習。
3. 減少正規化強度 如果正規化過強,也會導致欠擬合,需要適度調整。
4. 延長訓練時間 給模型更多迭代次數,讓它有機會收斂到更好的解。
正規化基礎:L1 與 L2
正規化是對付過擬合的重要武器。核心思想是:讓模型「偏好」更簡單的解法。
L2 正規化(Ridge / 嶺回歸)
在損失函數加上所有參數的平方和:
新損失 = 原始損失 + λ × Σ(wᵢ²)
- 效果:讓所有參數都趨近於零,但不會完全變成零
- 特點:結果較平滑,適合多數情況
- λ(lambda)是控制正規化強度的超參數
L1 正規化(Lasso)
在損失函數加上所有參數的絕對值之和:
新損失 = 原始損失 + λ × Σ|wᵢ|
- 效果:會讓某些不重要的參數完全變成零
- 特點:自動進行特徵選擇,讓模型更稀疏
- 適合:特徵非常多、但只有少數真正重要的情況
Elastic Net:結合 L1 與 L2,兼顧兩者優點。
| 方法 | 懲罰方式 | 稀疏性 | 適用場景 |
|---|---|---|---|
| L1 (Lasso) | 絕對值 | 高(有些參數變0) | 高維稀疏特徵 |
| L2 (Ridge) | 平方 | 低(所有參數縮小) | 一般情況 |
| Elastic Net | L1 + L2 | 中 | 兼顧兩者需求 |
應用場景(台灣實例)
場景:台灣房價預測模型
某家房仲公司用台北市過去三年的成交資料訓練了一個房價預測模型。
欠擬合的例子: 只用「坪數」一個特徵來預測房價,模型太簡單,完全忽略了「捷運距離」、「樓層」、「學區」、「屋齡」等關鍵因素,預測誤差高達 30%。
過擬合的例子: 使用過去三年所有成交資料訓練一個超複雜的深度神經網路,在訓練資料上誤差只有 1%,但放到 2026 年的新房市資料時誤差飆升到 25% — 因為它把 2024 年某特定月份的市場異常波動也「背」進去了。
正確做法:
- 納入合理的特徵(坪數、屋齡、捷運距離、行政區、樓層等)
- 加入 L2 正規化,避免對特定月份資料過度依賴
- 使用交叉驗證選擇最佳的模型複雜度
- 在驗證集上監控性能,使用早停法
結果:訓練集誤差 5%,測試集誤差 7%,差距合理,模型具有良好的泛化能力。
常見誤區
誤區 1:「訓練準確率越高,模型越好」
許多初學者把訓練集上的高分當成成功的指標,忽略了測試集表現才是真正的衡量標準。
正確做法:永遠要比較訓練集與測試集的誤差差距。差距過大 = 過擬合警訊。
誤區 2:「資料越多就能解決所有過擬合問題」
增加資料確實有幫助,但資料品質比數量更重要。一萬筆充滿雜訊的資料,可能不如一千筆乾淨、具代表性的資料。
另外,如果模型結構本身有問題(如過於複雜),單純增加資料的效果也有限,還是需要搭配正規化或其他技術。
誤區 3:「正規化強度(λ)越大越好,可以防止過擬合」
λ 值過大會讓懲罰力道過強,反而把所有參數壓縮得太小,讓模型失去學習能力,導致欠擬合。
λ 是一個需要調整的超參數,通常透過交叉驗證(cross-validation)找到最佳值 — 既不過擬合、也不欠擬合。
小練習
練習一
某個機器學習模型的訓練集準確率為 99.5%,但測試集準確率只有 58%。這個模型遇到了什麼問題?最可能的解決方案是什麼?
查看答案
**問題:過擬合(Overfitting)** 訓練集與測試集的準確率差距高達 41.5 個百分點,這是嚴重過擬合的典型症狀。模型把訓練資料的細節(包括雜訊)都記住了,但完全無法泛化到新資料。 **最可能的解決方案**: 1. **加入正規化**(L1 或 L2),限制模型參數的大小 2. **增加訓練資料**,讓模型接觸更多樣的範例 3. **使用 Dropout**(若為神經網路),隨機關閉神經元 4. **降低模型複雜度**,減少層數或節點數 5. **使用早停法**,在驗證集誤差開始上升時停止訓練 評估時應使用**交叉驗證**而非單一訓練/測試分割,以更穩健地衡量模型的泛化能力。練習二
以下描述哪些屬於 L1 正規化的特性,哪些屬於 L2 正規化的特性?
A. 會讓某些特徵的權重完全變成零,自動進行特徵選擇 B. 讓所有參數均勻縮小,但不會完全歸零 C. 適合用在特徵數量龐大但只有少數特徵真正重要的情境 D. 懲罰項為參數的平方和 E. 又稱為 Ridge Regression
查看答案
**L1 正規化(Lasso)的特性**:A、C - A:L1 的數學特性會讓不重要的參數精確歸零,產生稀疏解 - C:當特徵眾多但只有少數有效時,L1 的自動特徵選擇非常實用 **L2 正規化(Ridge)的特性**:B、D、E - B:L2 讓所有參數均勻縮小趨近於零,但不會完全變成零 - D:L2 的懲罰項公式為 λ × Σ(wᵢ²),使用平方和 - E:Ridge Regression 是 L2 正規化在線性迴歸中的別稱 **記憶口訣**: - L**1** → 讓某些權重變成「**1**個都沒有」(歸零)→ 稀疏 - L**2** → 讓所有權重都「縮**小**」但不歸零 → 平滑iPAS 重點整理
| 考試要點 | 核心概念 |
|---|---|
| 過擬合定義 | 模型在訓練集表現好、測試集表現差;高變異數、低偏差 |
| 欠擬合定義 | 模型在訓練集與測試集均表現差;低變異數、高偏差 |
| 偏差-變異數取捨 | 模型複雜度與泛化能力的根本矛盾 |
| L1 vs L2 | L1 產生稀疏解(特徵選擇);L2 均勻縮小所有參數 |
| 解決過擬合 | 增資料、正規化、Dropout、早停法、降低複雜度 |
| 解決欠擬合 | 增複雜度、特徵工程、延長訓練、調整正規化 |
| 驗證方式 | 交叉驗證(Cross-Validation)是評估泛化能力的標準做法 |