M03.08|模型評估指標:準確率、精確率、召回率、F1、AUC
準確率 99% 的模型可能是垃圾 — 如果 99% 的資料本來就是同一類
本講學習重點
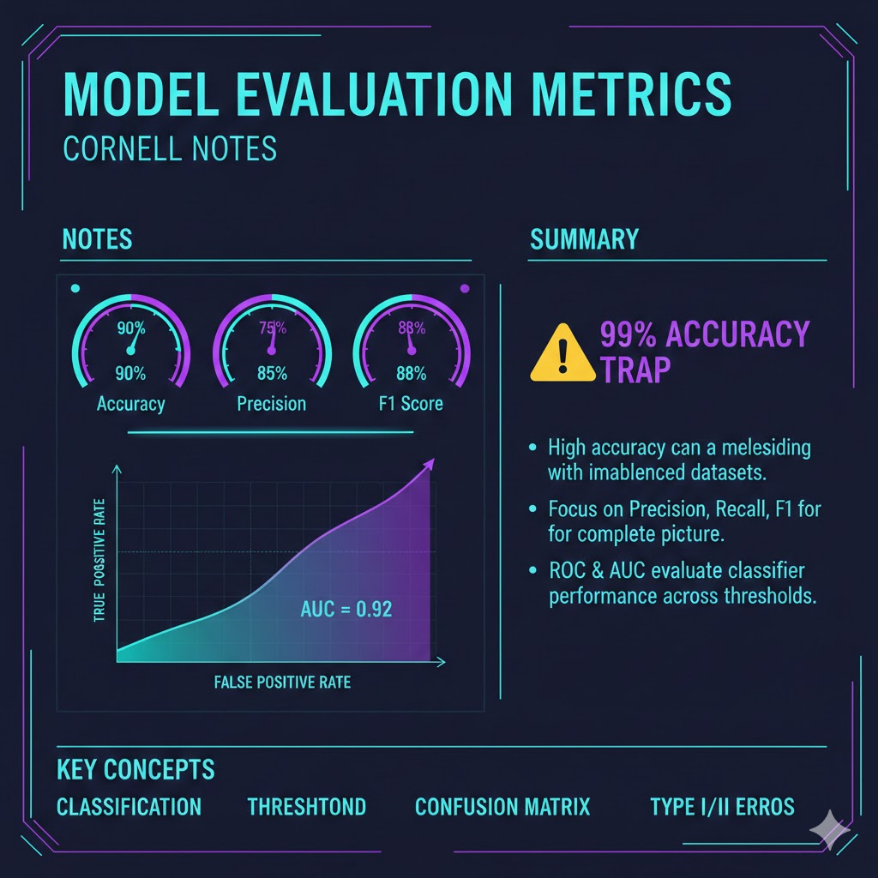
準確率(Accuracy)= 正確預測數 / 總預測數。看起來直觀,但在類別不平衡 的資料集(如癌症篩檢:99% 健康、1% 有病)中,把所有人都預測為「健康」 就能得到 99% 準確率,但這個模型完全沒有用。 精確率(Precision)= TP / (TP + FP):「被模型說是正例的,有多少真的是?」 召回率(Recall)= TP / (TP + FN):「所有真正的正例,模型找到了多少?」 精確率與召回率存在取捨(tradeoff):提高閾值 → 精確率上升、召回率下降; 降低閾值 → 召回率上升、精確率下降。選哪個,取決於「漏掉」和「誤報」 哪個代價更大。 F1 分數 = 2 × (Precision × Recall) / (Precision + Recall),是精確率和 召回率的調和平均數,兩者都重要時使用。 ROC 曲線描繪不同閾值下真陽性率 vs. 假陽性率的變化,AUC(曲線下面積) 衡量整體分類能力:AUC = 1 完美,AUC = 0.5 等同隨機猜測。
🎙️ Podcast(中文)
一句話搞懂
評估模型好不好,不是看「猜對幾題」,而是看「猜錯的那幾題,有多致命」——選對評估指標,才能看清模型的真實能力。
白話解說
準確率陷阱:99% 可能一文不值
想像有一家台灣醫院開發了一套 AI 系統,用來從病患的血液指數篩查一種罕見的早期癌症。測試結果出爐:準確率 99.1%,聽起來非常亮眼。
但等一下——這種癌症在人群中的盛行率只有 0.9%。換句話說,如果這個模型對所有 10,000 名受測者一律回答「沒有癌症」,它的準確率就自動達到 99.1%。這樣的模型完全沒有任何診斷價值,卻能拿到漂亮的數字。
這就是準確率陷阱(Accuracy Paradox),也稱為類別不平衡問題(Class Imbalance Problem)。
在現實世界中,類別不平衡幾乎無所不在:
- 詐騙交易偵測:正常交易佔 99.8%,詐騙佔 0.2%
- 製造業瑕疵品檢測:良品佔 98%,瑕疵品佔 2%
- 醫療診斷:健康者遠多於患者
- 信用違約預測:守信者遠多於違約者
這些場景中,準確率幾乎是毫無意義的指標。我們需要更精確的評估工具。
混淆矩陣:看清模型的四種錯誤
在進入各個指標之前,必須先認識混淆矩陣(Confusion Matrix)——它是所有分類評估指標的基礎。
以「癌症篩檢」為例(正例 = 有癌症,負例 = 沒有癌症):
模型預測
正例 負例
實際 正例 │ TP(真陽性)│ FN(假陰性)│
結果 負例 │ FP(假陽性)│ TN(真陰性)│
四個格子的含義:
| 縮寫 | 全名 | 含義 | 在癌症篩檢中代表 |
|---|---|---|---|
| TP | True Positive(真陽性) | 實際是正例,模型也預測是正例 | 有癌症,被正確診斷出來 |
| TN | True Negative(真陰性) | 實際是負例,模型也預測是負例 | 沒有癌症,被正確排除 |
| FP | False Positive(假陽性) | 實際是負例,但模型預測是正例 | 沒有癌症,卻被誤診為有 |
| FN | False Negative(假陰性) | 實際是正例,但模型預測是負例 | 有癌症,卻被漏掉了 |
記憶訣竅:前面的字母(T/F)代表預測對不對,後面的字母(P/N)代表模型說的是正例還是負例。
準確率(Accuracy)
\[\text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN}\]白話:所有預測中,答對的比例。
適用:類別分布平衡的問題(例如:圖片分類成 10 種動物,每種約佔 10%)。
不適用:類別嚴重不平衡的問題(如疾病篩檢、詐騙偵測)。
精確率(Precision):寧缺勿濫
\[\text{Precision} = \frac{TP}{TP + FP}\]白話:「模型說是正例的人裡面,真正是正例的比例。」
換句話說,精確率衡量的是誤報率有多低——模型說「你有問題」時,說對了幾成?
比喻:一個法官在定罪問題上的精確率。精確率高代表「被判有罪的人,真的幾乎都有罪」——寧可放走壞人,也不冤枉好人。
精確率高的代價:為了確保每個被標記為正例的都是真的,模型會傾向於非常保守,只有在非常確定時才說「是」,因此會漏掉很多真正的正例(FN 增加)。
高精確率適合的場景:
- 電子郵件垃圾信篩選(把重要郵件誤判為垃圾信代價很高)
- 新藥推薦(把沒效的藥推薦給患者代價高)
- 法律上的有罪認定
召回率(Recall):網盡天下魚
\[\text{Recall} = \frac{TP}{TP + FN}\]別名:敏感度(Sensitivity)、真陽性率(True Positive Rate, TPR)
白話:「所有真正的正例中,模型找到了多少?」
召回率衡量的是漏網率有多低——有多少真正有問題的案例被模型揪出來了?
比喻:一個刑警在追查嫌疑人的召回率。召回率高代表「所有真正的嫌犯,幾乎都被找出來了」——寧可多抓幾個無辜者,也不能讓真正的犯人逃跑。
召回率高的代價:為了不漏掉任何真正的正例,模型會傾向於鬆散,稍有嫌疑就標記為正例,因此會誤報很多假陽性(FP 增加)。
高召回率適合的場景:
- 癌症篩檢(漏掉真正的癌症患者代價遠高於多做幾次確認檢查)
- 地震預警系統(漏報比誤報危險得多)
- 食品安全檢測(讓問題食品流出的代價難以承受)
精確率與召回率的取捨
精確率和召回率之間存在根本性的取捨關係(Tradeoff),就像一把蹺蹺板:
閾值提高
高閾值 ─────────────────────▶
(只有非常確定才說「是」)
精確率上升 ↑
召回率下降 ↓
閾值降低
◀─────────────────────
(只要稍有可能就說「是」)
精確率下降 ↓
召回率上升 ↑
閾值(Threshold) 是模型輸出的機率值超過多少才算是正例的邊界。預設通常是 0.5,但可以根據業務需求調整。
決定使用精確率還是召回率的關鍵問題:
在你的場景中,「漏掉一個真正的問題」 和 「誤報一個沒有問題的」,哪個代價更大?
- 漏掉代價更大(如癌症、詐騙)→ 優先提升召回率
- 誤報代價更大(如垃圾信攔截、法庭定罪)→ 優先提升精確率
F1 分數:兩全其美的調和平均
當你同時重視精確率和召回率,不想犧牲任何一方時,使用 F1 分數(F1 Score)。
\[F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}\]F1 是精確率和召回率的調和平均數(Harmonic Mean),而非算術平均數。調和平均數的特性是:如果兩個數差距很大,結果會被拉向較小的那個。
為什麼用調和平均,不用算術平均?
假設某個模型:精確率 = 1.0,召回率 = 0.0(什麼都預測為負例)
- 算術平均 = (1.0 + 0.0) / 2 = 0.5(看起來還過得去)
- 調和平均(F1)= 0.0(正確反映這是個無用的模型)
F1 分數的範圍:0 到 1,越高越好。
F1 分數的延伸:Fβ 分數
當你想在精確率和召回率之間給予不同的權重時,可以使用:
\[F_\beta = (1 + \beta^2) \times \frac{\text{Precision} \times \text{Recall}}{\beta^2 \times \text{Precision} + \text{Recall}}\]- β = 1:F1(精確率和召回率同等重要)
- β = 2:F2(召回率的重要性是精確率的 2 倍,適合醫療診斷)
- β = 0.5:F0.5(精確率的重要性是召回率的 2 倍,適合垃圾信過濾)
ROC 曲線與 AUC:不依賴閾值的整體評估
前面提到的精確率、召回率、F1,都是在固定一個閾值之後計算的。但如果我們想比較兩個模型「整體上哪個更好」,而不被某個特定閾值影響呢?
這就是 ROC 曲線(Receiver Operating Characteristic Curve) 和 AUC(Area Under the Curve) 的用武之地。
ROC 曲線的畫法:
從閾值 = 1.0(最嚴格,所有人都判負例)開始,逐步降低閾值到 0.0(最寬鬆,所有人都判正例),在每個閾值下計算:
- X 軸:假陽性率(FPR) = FP / (FP + TN):有多少真負例被誤報為正例?
- Y 軸:真陽性率(TPR = Recall) = TP / (TP + FN):有多少真正例被正確找到?
把所有閾值的 (FPR, TPR) 點連起來,就是 ROC 曲線。
TPR
1.0 ┤ ●完美模型
│ ╱‾‾‾‾
0.8 ┤ ╱‾‾‾‾
│ ╱‾‾‾ ← 好的分類器(曲線越靠左上越好)
0.6 ┤ ╱‾‾
│ ╱
0.4 ┤ ╱ ← 隨機猜測(對角線,AUC = 0.5)
│╱
0.2 ┤
│
0.0 ┼────────────────────── FPR
0.0 0.2 0.4 0.6 0.8 1.0
AUC(ROC 曲線下的面積):
| AUC 值 | 解讀 |
|---|---|
| 1.0 | 完美分類器(現實中幾乎不存在) |
| 0.9 ~ 1.0 | 優秀 |
| 0.8 ~ 0.9 | 良好 |
| 0.7 ~ 0.8 | 尚可,需要改善 |
| 0.5 ~ 0.7 | 很差,幾乎沒有判斷力 |
| 0.5 | 等同隨機猜測 |
| < 0.5 | 比隨機猜測還差(通常代表正負例標記反了) |
AUC 的直覺解釋: 隨機從正例和負例各抽一個,模型給正例打的分數高於負例的機率。AUC = 0.87 代表有 87% 的機率,模型能正確地給真正的正例更高的分數。
AUC 的優點:
- 不受閾值影響,可以公平比較不同模型
- 不受類別不平衡影響(不像 Accuracy)
- 一個數字概括整條 ROC 曲線的資訊
AUC 的限制:
- 對高度類別不平衡的資料,有時 PR 曲線(Precision-Recall Curve)下的 AUC 比 ROC-AUC 更有參考價值
- AUC 只告訴你哪個模型「整體上更好」,不告訴你在你的業務閾值下的實際表現
哪個指標用在哪個情境:選擇指南
| 情境 | 核心問題 | 建議主要指標 | 原因 |
|---|---|---|---|
| 類別平衡的一般分類 | 整體預測對不對 | Accuracy | 簡單直觀,類別平衡時可靠 |
| 醫療篩檢(癌症、傳染病) | 不能漏掉任何病患 | Recall (+ AUC) | 漏報代價遠高於誤報 |
| 詐騙偵測(信用卡、電商) | 不能漏掉任何詐騙 | Recall + AUC | 每一筆詐騙都是損失 |
| 垃圾信過濾 | 不能把重要信擋掉 | Precision | 誤報代價高(遺漏重要信) |
| 推薦系統 | 推薦的東西要對胃口 | Precision@K | 用戶看到的幾個推薦要準 |
| 模型整體能力比較 | 哪個模型整體更好 | AUC | 不受閾值影響,公平比較 |
| 精確率和召回率都重要 | 兩者需要平衡 | F1 Score | 調和平均,兩者都差不了太多 |
| 醫療篩檢(召回率更重要) | 召回率比精確率重要兩倍 | F2 Score | 加重召回率的權重 |
應用場景
台灣醫療 AI:乳癌篩檢模型評估
台灣某大型醫學中心開發了兩套 AI 乳癌篩檢模型,分別在 50,000 筆乳房 X 光影像上測試(其中 2,500 張有乳癌,佔 5%)。
兩個模型的混淆矩陣
模型 A(激進型,傾向報出陽性):
| 預測有癌症 | 預測無癌症 | |
|---|---|---|
| 實際有癌症 (2,500) | 2,375 (TP) | 125 (FN) |
| 實際無癌症 (47,500) | 4,750 (FP) | 42,750 (TN) |
模型 B(保守型,傾向報出陰性):
| 預測有癌症 | 預測無癌症 | |
|---|---|---|
| 實際有癌症 (2,500) | 2,000 (TP) | 500 (FN) |
| 實際無癌症 (47,500) | 475 (FP) | 47,025 (TN) |
各項指標比較
| 指標 | 模型 A(激進型) | 模型 B(保守型) | 計算方式 |
|---|---|---|---|
| Accuracy | 90.25% | 98.05% | (TP+TN)/總數 |
| Precision | 33.3% | 80.8% | TP/(TP+FP) |
| Recall | 95.0% | 80.0% | TP/(TP+FN) |
| F1 Score | 49.5% | 80.4% | 調和平均 |
| AUC | 0.91 | 0.91 | 兩模型相同 |
如何選擇?
單看 Accuracy,模型 B 遙遙領先(98% vs. 90%)——但這只是因為兩個模型都把大部分的「無癌症」樣本判斷正確(因為這類樣本佔了 95%)。
關鍵問題:漏掉一個癌症患者(FN),代價是什麼?
在早期癌症篩檢中,漏報代價極高——患者可能因此錯過最佳治療時機。因此這個場景最重視 Recall(召回率)。
- 模型 A 的 Recall = 95%:2,500 名患者中,只漏掉 125 人
- 模型 B 的 Recall = 80%:2,500 名患者中,漏掉了 500 人
在醫療篩檢場景中,模型 A 才是更好的選擇,儘管它的 Accuracy 和 Precision 較低——多出的 4,750 個假陽性患者會進一步做確認檢查(超音波、切片),這是可接受的代價。而模型 B 讓 500 名真正有癌症的患者被漏掉,代價難以估量。
台灣金融科技:信用卡詐騙偵測
某台灣支付平台每天處理 200 萬筆交易,其中詐騙交易佔 0.05%(約 1,000 筆)。
三個候選模型的評估結果
| 模型 | Accuracy | Precision | Recall | F1 | AUC |
|---|---|---|---|---|---|
| 模型 X:傳統規則引擎 | 99.9% | 72% | 58% | 64% | 0.79 |
| 模型 Y:隨機森林 | 99.95% | 68% | 84% | 75% | 0.91 |
| 模型 Z:XGBoost | 99.94% | 61% | 91% | 73% | 0.93 |
業務決策分析:
三個模型的 Accuracy 都在 99.9% 以上,從 Accuracy 完全看不出差異。
| 指標重點 | 模型 X | 模型 Y | 模型 Z |
|---|---|---|---|
| 每天漏掉的詐騙筆數(1000×(1-Recall)) | 420 筆 | 160 筆 | 90 筆 |
| 每天誤報筆數(約估) | 較少 | 中等 | 較多 |
| AUC(整體判斷力) | 最低 | 良好 | 最高 |
對於信用卡詐騙,每一筆漏掉的詐騙都是直接的財務損失。模型 Z 每天只漏掉 90 筆,比傳統規則引擎少漏掉 330 筆——以平均詐騙金額 5,000 元估算,每天可多攔截約 165 萬元的詐騙損失。
雖然模型 Z 的 Precision 較低(61%),但多出的誤報會由人工複審團隊確認,成本遠低於直接損失。
結論:在詐騙偵測場景,選用 AUC 最高且 Recall 最強的模型 Z,同時用 Precision 來控制人工複審的工作量。
常見誤區
誤區一:只報告準確率,對老闆和客戶交差
很多初學者和非技術出身的決策者,習慣用 Accuracy 作為唯一的模型評估標準,因為它最直觀——「猜對 95%」比「Recall 0.82、AUC 0.91」聽起來好溝通。但在類別不平衡的場景(而現實中幾乎所有重要的 AI 應用都有類別不平衡),Accuracy 可以嚴重誤導。台灣的 iPAS AI 認證和企業 AI 導入評估,都要求從業者能根據業務場景選擇適當的評估指標,而非一律用 Accuracy 交差。負責任的 AI 實踐者,必須主動溝通「這個模型用什麼指標評估、為什麼選這個指標」。
誤區二:混淆精確率和準確率的中文翻譯
在台灣的技術文件和 iPAS 考題中,「準確率」(Accuracy)和「精確率」(Precision)是兩個完全不同的概念,但中文名稱相近,非常容易混淆。考試時特別注意:Accuracy 是「整體猜對的比例」,Precision 是「預測為正例中真正是正例的比例」。英文原文是最保險的辨別方式。另外,召回率(Recall)有時也被稱為「敏感性(Sensitivity)」(醫療文獻常用),或「查全率」,都是同一個指標。
誤區三:認為 AUC 越高,上線後表現就一定越好
AUC 衡量的是模型在所有可能閾值下的平均排序能力,但實際部署時你只會使用一個固定的閾值。AUC 0.93 的模型,在你業務最關心的閾值區間,可能表現並不比 AUC 0.89 的模型好。此外,AUC 完全不考慮誤判的成本差異——在醫療場景,一個 FN(漏掉癌症患者)的代價可能是一個 FP(不必要的追加檢查)的 100 倍,但 AUC 對這兩者一視同仁。評估模型時,AUC 是很好的「排序工具」,但最終的模型選擇和閾值設定,必須結合業務的成本-收益分析。
小練習
練習一:幫詐騙偵測模型選指標
某台灣電商平台的資料科學家訓練了一個「買家帳號異常偵測」模型,用來防止「薅羊毛」行為(利用新帳號大量領取首購優惠)。
資料背景:
- 每月新帳號約 10 萬個
- 其中約 3% 為異常薅羊毛帳號(3,000 個)
- 每個被誤判(正常用戶被標記為異常)的帳號,如果沒有及時申訴,會損失一位潛在的真實客戶
- 每個被漏掉的異常帳號,平均讓公司損失 300 元優惠金
模型測試結果(在 10,000 筆測試資料中,其中 300 筆為異常):
| 模型 | TP | FP | FN | TN |
|---|---|---|---|---|
| 模型甲 | 270 | 30 | 30 | 9,670 |
| 模型乙 | 285 | 285 | 15 | 9,415 |
請計算兩個模型的 Precision、Recall、F1,並根據業務情境,說明你會選擇哪個模型,以及是否需要調整閾值。
看解答
**計算各項指標:** | 指標 | 模型甲 | 模型乙 | |------|--------|--------| | Accuracy | (270+9670)/10000 = **99.4%** | (285+9415)/10000 = **97.0%** | | Precision | 270/(270+30) = **90%** | 285/(285+285) = **50%** | | Recall | 270/(270+30) = **90%** | 285/(285+15) = **95%** | | F1 | 2×(0.9×0.9)/(0.9+0.9) = **90%** | 2×(0.5×0.95)/(0.5+0.95) = **65.5%** | **業務損失分析:** - 模型甲:每月(按 10 萬帳號推算)漏掉 1,000 個異常帳號 × 300 元 = **損失 30 萬元**;誤報 1,000 個正常用戶(可申訴挽回) - 模型乙:每月漏掉 500 個異常帳號 × 300 元 = **損失 15 萬元**;誤報 9,500 個正常用戶(嚴重影響用戶體驗) **結論:** 這個問題沒有絕對的標準答案,需要根據公司的判斷: - 若公司最在意**用戶體驗**(不想誤殺正常用戶)→ 選**模型甲**(Precision 90%,誤報少) - 若公司最在意**直接財損**(不想讓薅羊毛得逞)→ 選**模型乙**(Recall 95%,漏報少),但需要強化申訴流程來處理大量誤報 **進階建議:** 可以考慮在模型乙的基礎上**提高閾值**(從預設的 0.5 調高到例如 0.7),讓 Precision 提升到 70-75% 的同時,Recall 仍維持在 85-90%,找到更好的平衡點。這正是 Precision-Recall 取捨的實際應用。練習二:解讀混淆矩陣
台灣某公立國中導入 AI 輔助系統,偵測「學習落後風險」學生(用來提前安排補救教學資源)。
系統在 500 名學生的資料上測試,以下是混淆矩陣(正例 = 學習落後風險高):
預測:高風險 預測:低風險
實際:高風險 42 18
實際:低風險 28 412
請回答以下問題:
- 計算 Accuracy、Precision、Recall、F1
- 這個場景中,FN(漏掉真正高風險的學生)和 FP(把低風險學生誤判為高風險)哪個代價更大?為什麼?
- 如果要改善這個模型,你建議優先提升 Precision 還是 Recall?