M03.10|模型選擇與調參:沒有最好的模型,只有最適合的
No Free Lunch — 沒有一個模型能贏所有比賽
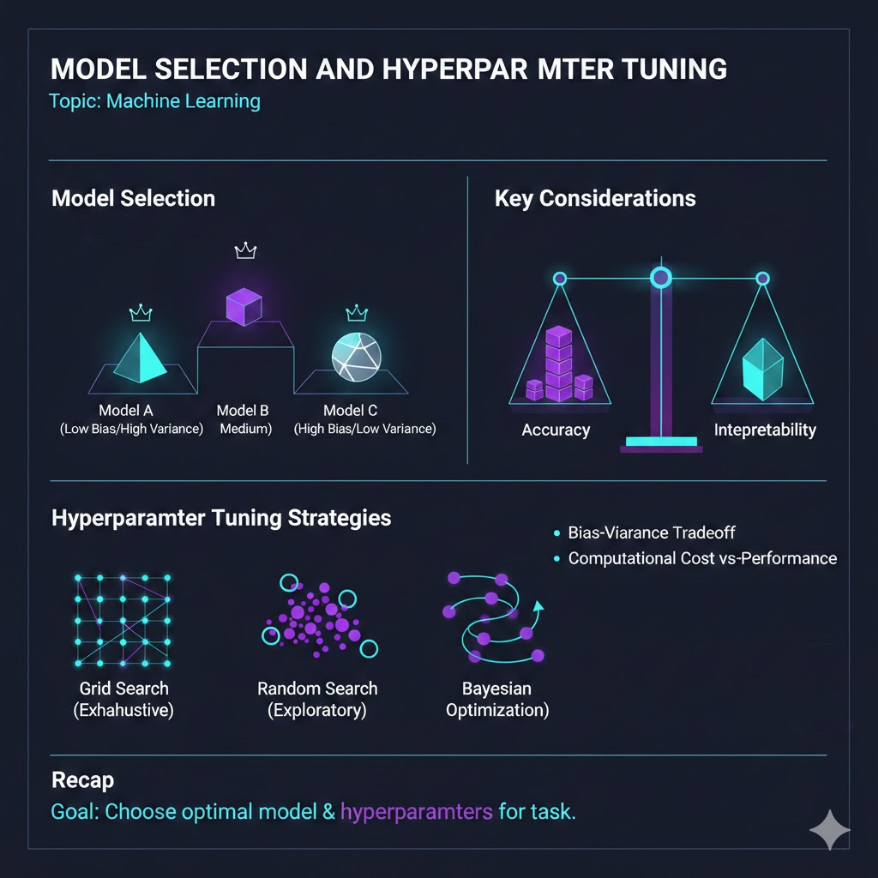
本講學習重點
No Free Lunch(NFL)定理:沒有任何一個機器學習演算法在所有問題上都表現最好。 選模型必須根據具體問題的特性,沒有放諸四海皆準的最佳演算法。 四個模型選擇標準(需根據業務需求加權): 1. 準確率(Accuracy)— 預測表現 2. 可解釋性(Interpretability)— 法規、溝通、信任 3. 速度(Speed)— 訓練速度 vs 推論速度 4. 資料規模(Data Size)— 小資料 vs 大資料各有適合的演算法 三種超參數調校方法: - 網格搜尋(Grid Search):窮舉所有組合,保證找到格子內最優,但慢 - 隨機搜尋(Random Search):隨機取樣,效率更高,適合高維超參數空間 - 貝葉斯最佳化(Bayesian Optimization):根據前幾次結果智慧選下一個,效率最高 集成方法(Ensemble Methods): - Bagging(如隨機森林):多個模型獨立訓練,投票/平均,降低變異數 - Boosting(如 XGBoost、LightGBM):模型串聯,後面的專門修前面的錯誤,降低偏差 - Stacking:用一個元模型學習如何組合各基礎模型的預測 AutoML:自動化特徵工程、模型選擇、超參數調校,適合快速原型,非萬能
🎙️ Podcast(中文)
一句話搞懂
沒有任何一個機器學習模型能在所有問題上都表現最好——這是數學上可以證明的定理,叫做 No Free Lunch。選擇模型不是找「最強的」,而是找「最適合你問題的」,再透過超參數調校讓它發揮最大潛力。
白話解說
No Free Lunch 定理:為什麼不存在萬能模型
1996 年,Wolpert 和 Macready 從數學上嚴格證明了一個反直覺的結論:
如果把所有可能的問題平均來看,任何兩個演算法的平均表現是一樣的。
換句話說,若你用演算法 A 和演算法 B 跑遍所有可能的資料集,它們的平均準確率是相等的。任何在某些問題上表現優秀的演算法,必然在其他問題上表現相對差。
用白話說:天下沒有免費的午餐——你在某些問題上得到的好處,是以在其他問題上表現更差為代價的。
No Free Lunch 定理的實際意涵不是「所有演算法一樣爛」,而是:
- 不存在能在所有問題上通吃的萬能演算法
- 每個演算法都對特定類型的問題有隱含假設(Inductive Bias)
- 選擇演算法必須根據你的具體問題特性,而非根據某個演算法「聽起來很厲害」
問題 A(線性可分): 邏輯回歸 > 神經網路 > 隨機森林
問題 B(高維稀疏文字):SVM > 隨機森林 > 邏輯回歸
問題 C(大量圖片分類):神經網路 > SVM > 邏輯回歸
問題 D(小資料集): 決策樹 > 神經網路 > XGBoost
這四個問題的「最佳演算法」完全不同。No Free Lunch 定理告訴你:選錯演算法,再怎麼調參也是徒勞。
四個模型選擇標準
實際工作中,選擇模型不只看「準確率」。以下四個維度缺一不可:
1. 準確率(Accuracy / Performance)
預測的品質指標,包含準確率、精確率、召回率、F1、AUC-ROC 等(參見 M03-09 混淆矩陣篇)。
但高準確率不等於好模型: 一個訓練準確率 99%、測試準確率 65% 的模型,不如訓練準確率 85%、測試準確率 83% 的模型穩健。泛化能力才是關鍵。
2. 可解釋性(Interpretability)
模型能否對使用者解釋「為什麼做出這個預測」。
| 場景 | 可解釋性要求 | 適合的模型 |
|---|---|---|
| 銀行信貸審核 | 極高(法規要求說明理由) | 邏輯回歸、決策樹 |
| 醫療輔助診斷 | 高(醫生需要理解依據) | 決策樹、規則系統 |
| 推薦系統 | 中(可解釋但不強制) | 隨機森林、XGBoost |
| 圖片辨識 | 低(結果比解釋重要) | 深度神經網路 |
台灣金管會對 AI 輔助信貸決策有明確規範:若 AI 拒絕申貸,必須提供具體理由。這直接限制了可選的模型類型。
3. 速度(Speed)
速度分為兩個不同的維度,常被混淆:
| 維度 | 意義 | 影響場景 |
|---|---|---|
| 訓練速度 | 建立模型需要多少時間 | 資料更新後多久能重新訓練?能否每日更新? |
| 推論速度 | 對新樣本做一次預測需要多少時間 | 即時決策(毫秒級)vs 批次處理(分鐘級) |
案例:信用卡詐騙偵測要求毫秒內給出答案(因為交易需要即時核准),因此推論速度極為關鍵,不適合需要複雜計算的模型;而每週重新訓練一次的房價預測模型,訓練速度幾乎不重要。
4. 資料規模(Data Size)
不同演算法對資料量有截然不同的要求:
| 資料量 | 適合的演算法 | 原因 |
|---|---|---|
| 極少(< 500 筆) | 邏輯回歸、SVM、決策樹 | 參數少,不容易過擬合 |
| 中型(500–10 萬筆) | 隨機森林、XGBoost、SVM | 集成方法開始發揮優勢 |
| 大型(10 萬–百萬筆) | XGBoost、LightGBM、淺層神經網路 | 需要能高效處理大量資料的框架 |
| 超大型(> 百萬筆) | 深度神經網路、分散式訓練 | 神經網路隨資料量增加持續改善 |
直覺理解:神經網路就像一個需要大量練習才能發揮潛力的學生;決策樹就像一個少量例子就能歸納規則的聰明人——但資料一多,學習能力強的神經網路就能超越它。
超參數調校三種方法
超參數(Hyperparameter)是訓練前由人工設定的「學習規則」,如學習率、決策樹深度、神經網路層數。正確的超參數能讓模型表現提升 10–30%,錯誤的設定則可能讓模型完全失效。
方法一:網格搜尋(Grid Search)
做法:列出每個超參數的所有候選值,窮舉所有組合,逐一評估。
假設要調整兩個超參數:
- 學習率(learning_rate):[0.01, 0.05, 0.1]
- 最大深度(max_depth):[3, 5, 7, 9]
網格搜尋會嘗試所有 3 × 4 = 12 個組合:
(0.01, 3), (0.01, 5), (0.01, 7), (0.01, 9),
(0.05, 3), (0.05, 5), (0.05, 7), (0.05, 9),
(0.10, 3), (0.10, 5), (0.10, 7), (0.10, 9)
每個組合配合 5 折交叉驗證 = 60 次訓練
優點:系統性,保證找到格子內的最優組合,結果可重現。 缺點:超參數維度增加時,計算量指數爆炸(10 個超參數各 5 個候選值 = 5¹⁰ 次)。
適合場景:超參數數量少(2–3 個)、每次訓練速度快(數秒到數分鐘)。
方法二:隨機搜尋(Random Search)
做法:從超參數的範圍中隨機取樣若干組合(例如取 50 組),評估這 50 組的表現,選出最佳。
學習率:從 [0.001, 0.5] 均勻隨機取樣
最大深度:從 {3, 4, 5, ..., 15} 隨機取樣
隱藏層數量:從 {1, 2, 3, 4, 5} 隨機取樣
L2 正則化強度:從 [0.0001, 1.0] 對數均勻取樣
→ 隨機抽取 50 組組合,各跑一次驗證
→ 選出 50 次中表現最好的那一組
為什麼隨機搜尋比網格搜尋更有效率?
Bergstra & Bengio(2012)在論文中證明:在大多數情況下,某些超參數對最終結果的影響遠大於其他超參數(重要超參數只佔少數)。
- 網格搜尋:在不重要的超參數上浪費大量試驗次數
- 隨機搜尋:每次試驗都在所有超參數上探索不同值,重要超參數被更密集地採樣
適合場景:超參數數量多(4 個以上)、超參數空間大(連續範圍),或計算資源有限時。
方法三:貝葉斯最佳化(Bayesian Optimization)
做法:不是盲目搜尋,而是用「代理模型」(Surrogate Model)根據前幾次試驗的結果,智慧地預測哪個超參數組合最可能好,優先嘗試最有希望的方向。
第 1 次試驗:隨機選一組 → 結果 F1 = 0.72
第 2 次試驗:隨機選一組 → 結果 F1 = 0.75
第 3 次試驗:隨機選一組 → 結果 F1 = 0.68
...
第 5 次試驗:代理模型預測最有機會的組合 → 結果 F1 = 0.81
第 6 次試驗:根據第 5 次結果更新代理模型,再預測 → 結果 F1 = 0.83
代理模型不斷更新對「超參數空間」的認識,聚焦在表現好的區域探索。
優點:每次試驗都比前一次更有針對性,達到同等效果所需的試驗次數遠少於隨機搜尋。 缺點:實作較複雜(需要 Optuna、Hyperopt 等工具);當試驗本身非常快時,貝葉斯最佳化的額外開銷反而不划算。
適合場景:每次訓練耗時很長(如深度學習,每次需要數小時),試驗次數珍貴,需要最有效率的搜尋策略。
三種方法的比較
| 比較項目 | 網格搜尋 | 隨機搜尋 | 貝葉斯最佳化 |
|---|---|---|---|
| 搜尋方式 | 窮舉所有組合 | 隨機取樣 | 智慧導向探索 |
| 找到最優的保證 | 格子內最優 | 機率性 | 機率性(但更高效) |
| 計算效率 | 低(維度詛咒) | 中 | 高 |
| 實作複雜度 | 低 | 低 | 中 |
| 適合超參數數量 | 少(1–3 個) | 多(4 個以上) | 多(尤其慢模型) |
| 常用工具 | sklearn GridSearchCV | sklearn RandomizedSearchCV | Optuna, Hyperopt |
集成方法入門
單一模型有其極限。集成學習(Ensemble Methods)透過組合多個模型,往往能突破單一模型的天花板。
Bagging(Bootstrap Aggregating)
代表演算法:隨機森林(Random Forest)
原理:訓練多個獨立的模型,每個模型用訓練資料的隨機子集訓練,最終結果由所有模型投票(分類)或取平均(迴歸)。
核心效果:降低變異數(Variance),減少過擬合。
原始資料 (1000 筆)
↓ 隨機有放回抽樣 (Bootstrap)
樹1 (800 筆子集) → 預測: 陽性
樹2 (800 筆子集) → 預測: 陰性
樹3 (800 筆子集) → 預測: 陽性
...
樹100 → 預測: 陽性
多數決 → 最終預測: 陽性
Boosting
代表演算法:XGBoost、LightGBM、AdaBoost
原理:模型串聯訓練。第一個模型訓練完後,標出它預測錯誤的樣本;第二個模型加強學習那些錯誤的樣本;第三個模型再針對前兩個模型的殘差學習……以此類推。
核心效果:降低偏差(Bias),讓弱分類器集合成強分類器。
模型1 → 預測值(有誤差)
↓
模型2 → 學習「模型1的預測誤差」
↓
模型3 → 學習「模型1+2的預測誤差」
↓
...
最終預測 = 所有模型預測值的加權總和
XGBoost 在 2014–2020 年間幾乎贏得了所有機器學習競賽,成為結構化(表格)資料的標準配備。
Stacking(堆疊集成)
原理:用第一層(基礎模型)做預測,再用第二層的「元模型」(Meta-Model)學習如何最優地組合第一層的預測。
原始特徵
↓
層一:邏輯回歸預測 → 0.73
隨機森林預測 → 0.81
SVM 預測 → 0.69
↓
層二:元模型(線性回歸)
輸入: [0.73, 0.81, 0.69]
輸出: 最終預測 0.78
Stacking 比 Bagging 和 Boosting 更靈活,但實作複雜,且需要仔細防止資料洩漏(第一層訓練時必須用交叉驗證生成預測,不能直接用訓練資料)。
AutoML:自動化機器學習
AutoML 是將模型選擇、特徵工程、超參數調校等流程自動化的工具,讓沒有深度 ML 知識的使用者也能建立可用的模型。
AutoML 自動化的內容:
- 特徵選擇與特徵工程
- 演算法選擇(從候選池中挑最適合的)
- 超參數調校(通常使用貝葉斯最佳化或進化演算法)
- 集成組合(有些 AutoML 自動建立 Stacking 集成)
主要工具:
| 工具 | 開發者 | 特點 | 適合使用者 |
|---|---|---|---|
| AutoKeras | 台灣 keras 團隊 | 深度學習 AutoML | 研究人員 |
| Auto-sklearn | Freiburg 大學 | sklearn 生態系 | 資料科學家 |
| H2O AutoML | H2O.ai | 企業級,GUI | 業務分析師 |
| Google AutoML | 雲端服務,無程式碼 | 非技術人員 | |
| FLAML | Microsoft | 快速、輕量 | 工程師 |
AutoML 的限制——它不能做的事:
- 定義問題(是分類還是迴歸?成功指標是什麼?)
- 判斷資料品質(資料是否有偏差?有無資料洩漏?)
- 解釋結果給業務方(為什麼這個預測對業務有意義?)
- 決定模型是否可以部署(準確率 80% 對這個業務夠嗎?)
AutoML 最適合的場景:快速建立基線模型(Baseline),了解「這個問題大概能做到多好」,然後再根據業務需求進行深度調整。把 AutoML 當起點,而非終點。
應用場景
台灣保險業的模型選擇比較
台灣某中型保險公司(年保費收入約 80 億元)希望建立一套理賠詐欺偵測系統,針對車險理賠申請預測是否為詐欺。
業務需求分析:
- 年申請量:約 20 萬件,詐欺率估計 0.8%(約 1,600 件)
- 法規要求:拒絕理賠或要求進一步調查時,必須提供理由(精確率優先)
- 即時性:理賠審核需在 72 小時內完成(無需毫秒級決策)
- 資料:5 年歷史資料,約 100 萬筆,30 個特徵(事故類型、地點、維修廠、過去申請紀錄等)
模型選擇評估表:
| 模型 | 準確率(驗證集) | 精確率 | 召回率 | 訓練時間 | 可解釋性 | 推論速度 | 綜合評分 |
|---|---|---|---|---|---|---|---|
| 邏輯回歸 | 91.3% | 0.42 | 0.68 | 2 分鐘 | 極高 | 極快 | ★★★☆☆ |
| 決策樹(深度 8) | 92.1% | 0.45 | 0.65 | 1 分鐘 | 高 | 極快 | ★★★☆☆ |
| 隨機森林 | 96.4% | 0.71 | 0.79 | 25 分鐘 | 中(特徵重要性) | 快 | ★★★★☆ |
| XGBoost | 97.1% | 0.74 | 0.82 | 18 分鐘 | 中 | 快 | ★★★★★ |
| 深度神經網路 | 96.8% | 0.70 | 0.81 | 4 小時 | 低(黑盒) | 快 | ★★★☆☆ |
最終決策:採用 XGBoost + 決策樹混合架構
- 主力模型:XGBoost(準確率和精確率最高)用於自動過濾明顯的詐欺案件
- 輔助解釋:決策樹(可解釋性高)用於生成「系統認為此案件可疑的具體理由」供審核員參考
- 超參數調校:對 XGBoost 使用隨機搜尋(5 個超參數,每個超參數 10 個候選值,抽樣 100 組,配合 5 折交叉驗證)
調校後的效益:
- 與調校前基線模型相比,精確率從 0.61 提升至 0.74(減少誤報 18%)
- 每年預計攔截詐欺理賠金額:約 1.2 億元
- 調查員工作量:系統自動標記 90% 的高風險案件,調查員只需人工複核 5%(系統判斷邊界案件),效率提升 60%
這個案例說明:模型選擇不是純粹的準確率比較,而是根據業務約束(法規、速度、可解釋性)做出有依據的工程判斷;超參數調校是從「能用」到「好用」的最後一里路。
常見誤區
誤區一:直接選準確率最高的模型,忽略其他條件
許多初學者在模型比較表中看到 XGBoost 或神經網路準確率最高,就直接選用。實際工作中,準確率只是決策因素之一。若應用場景需要向監管機構解釋決策依據(台灣金融業、醫療業普遍有此要求),選擇「準確率略低但完全可解釋」的邏輯回歸或決策樹,往往比選最高準確率但無法解釋的黑盒模型更符合業務需要。更何況,準確率 96% 和 97% 的模型在實際業務上的差距,往往比「能否解釋給稽核人員」的差距小得多。
誤區二:超參數調校在測試集上進行,或使用測試集結果決定超參數
這是超參數調校最常見的嚴重錯誤。超參數調校的每次評估都必須在驗證集(或交叉驗證)上進行,絕不能用測試集。一旦用測試集評估來選擇超參數,等於把測試集變成了「另一個驗證集」——最後報告的測試集分數是針對那組特定測試資料過度優化的結果,無法代表模型對未知真實世界資料的表現,但業務方會誤以為它是可靠的預期表現。這個錯誤在台灣常見於「競賽式思維」:為了讓 demo 結果好看而反覆用測試集調參,上線後表現卻遠不如預期。
誤區三:把 AutoML 當成萬能工具,跳過問題定義和資料理解
AutoML 讓建立模型變得容易,但它無法替你定義「好的模型是什麼意思」。若你把定義模糊的問題(如「預測客戶是否滿意」——但什麼算滿意?)丟給 AutoML,它會認真地優化你設定的指標,給出一個高分的答案——但這個答案很可能和你真正的業務目標完全脫節。更危險的是,AutoML 無法發現資料中隱藏的偏差(例如歷史資料中少數族群的系統性偏見),若不加驗證就部署,可能導致歧視性決策。AutoML 最大的價值是快速原型,而非取代對問題和資料的深入理解。
小練習
練習一:No Free Lunch 的情境應用
以下是某家台灣新創公司的兩個 AI 專案,請為每個專案推薦最適合的模型,並說明選擇理由(從準確率、可解釋性、速度、資料規模四個維度分析):
專案 A — 醫療院所的住院天數預測:
- 資料:台灣健保資料庫,300 萬筆住院紀錄,80 個特徵(診斷碼、手術項目、年齡、BMI 等)
- 目標:預測患者住院天數(連續數值),幫助醫院床位調配
- 限制:預測結果需要向主治醫師解釋,醫師信任感是導入關鍵
專案 B — 電商即時商品推薦:
- 資料:過去 2 年,1,000 萬筆購買紀錄,20 個使用者行為特徵
- 目標:在使用者瀏覽頁面時(< 100 毫秒)推薦最可能購買的商品(分類問題)
- 限制:無需解釋,以轉換率為唯一指標
看解答
**專案 A:建議採用 XGBoost + SHAP 解釋** 四維度分析: - **準確率**:300 萬筆資料、80 個特徵,XGBoost(Boosting 集成)在結構化大資料上的預測表現通常優於線性模型和單棵決策樹 - **可解釋性**:XGBoost 本身是「灰盒」,可搭配 SHAP(SHapley Additive exPlanations)值為每一次預測生成可解釋的特徵貢獻量(例如「因為糖尿病診斷碼 + 年齡 > 70,預測住院天數增加 3.2 天」),這對取得醫師信任至關重要 - **速度**:住院天數預測不需要毫秒級回應,72 小時前預測即可,訓練速度可接受 - **資料規模**:300 萬筆足以讓 XGBoost 充分發揮,但不到需要深度學習的程度 補充:邏輯回歸可解釋性更高,但在 80 個特徵的複雜非線性關係下,準確率可能不足以取得醫師信任。深度神經網路在此資料量下準確率可能相近,但可解釋性差,不符合「醫師信任」需求。 **專案 B:建議採用 LightGBM 或梯度提升樹(線上推論版本)** 四維度分析: - **準確率**:1,000 萬筆資料,LightGBM(基於直方圖的梯度提升樹)在大資料下準確率優秀且效率高於 XGBoost - **可解釋性**:此場景無需解釋,純粹追求轉換率,可解釋性不是考量因素 - **速度**:**這是最關鍵因素**。需要 < 100 毫秒推論,LightGBM 訓練的模型推論速度快(通常 1–10 毫秒),符合需求;深度神經網路推論延遲較高,且需要 GPU 加速 - **資料規模**:1,000 萬筆是 LightGBM 的甜蜜點,訓練效率高 補充:若轉換率瓶頸在於捕捉使用者行為的時序模式(如「瀏覽三件商品後通常買第四件」),可考慮加入 LSTM 或 Transformer 類的序列模型,但需要評估延遲是否仍符合 100 毫秒要求。 **核心結論**:同樣是「預測準確率」的任務,因為業務約束(可解釋性 vs 推論速度)選出了完全不同的演算法。這正是 No Free Lunch 定理在實務中的體現。練習二:超參數調校策略選擇
某工程師小明要對一個 LightGBM 模型進行超參數調校,候選超參數如下:
| 超參數 | 候選範圍 |
|---|---|
| learning_rate | [0.001, 0.5](連續) |
| num_leaves | 整數 [20, 300] |
| min_child_samples | 整數 [10, 200] |
| feature_fraction | [0.4, 1.0](連續) |
| bagging_fraction | [0.4, 1.0](連續) |
| lambda_l1 | [0.0, 10.0](連續) |
| lambda_l2 | [0.0, 10.0](連續) |
每次訓練(含 5 折交叉驗證)需要 8 分鐘,小明的時間預算是 24 小時。
請問:(1) 小明最多能嘗試幾組超參數組合?(2) 應選擇哪種調校方法?(3) 若要用網格搜尋,問題出在哪裡?