M05.03|Prompt Engineering:跟 AI 說話的藝術
同一個模型,問法不同,答案天差地別
本講學習重點
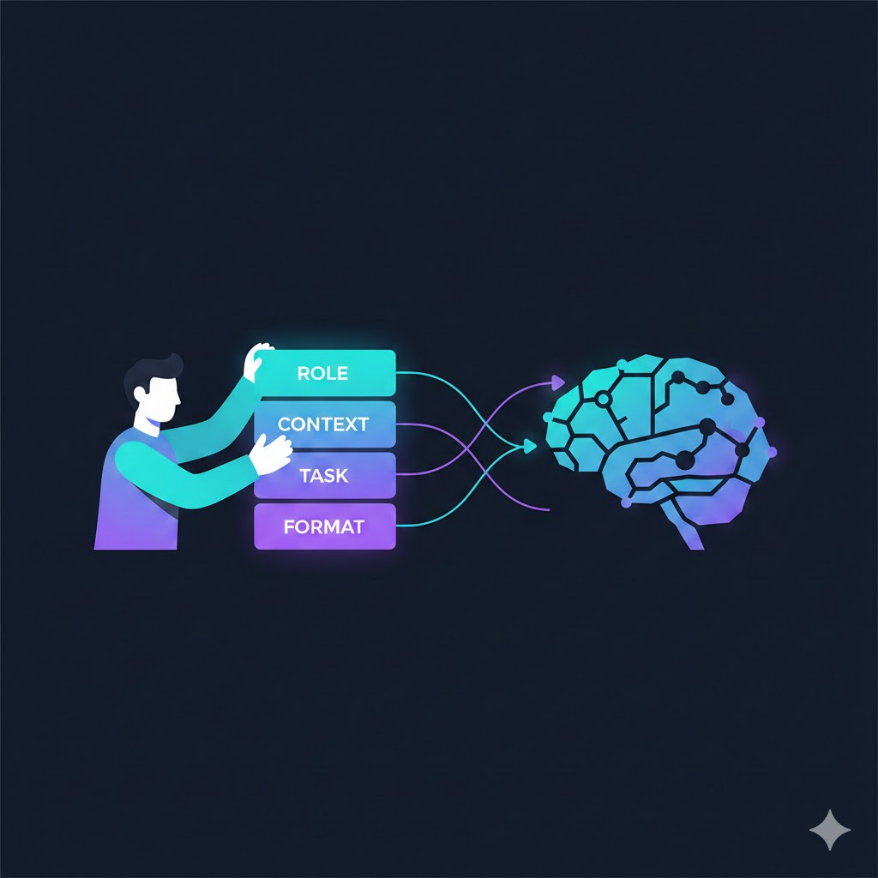
Zero-shot:直接問問題,不提供範例。簡單任務夠用,複雜任務品質不穩定。 Few-shot:在 prompt 中提供 2-5 個輸入/輸出範例,讓模型「理解格式和邏輯」再作答。 Chain-of-Thought(CoT):要求模型「逐步思考」,在輸出最終答案前先寫推理過程。 - 顯式 CoT:「請一步一步思考」 - 自動 CoT:在 few-shot 範例中包含推理步驟 - 效果:複雜數學/邏輯推理任務準確率大幅提升 角色提示:在 system prompt 中指定模型的身份和視角,例如「你是一位資深合約律師」。 作用:引導模型從不同角度和知識框架生成回覆,不是讓模型「假裝」而是「激活」相關知識。 System Prompt:對話開始前設定的固定指令,定義模型的角色、行為規範、輸出格式、限制。 User Prompt:每輪對話中用戶的輸入,是動態變化的部分。 結構化輸出:要求模型用 JSON、Markdown 表格、清單等格式輸出,便於後續程式處理。
🎙️ Podcast(中文)
一句話搞懂
Prompt Engineering(提示工程)就是「懂得怎麼跟 AI 說話的技能」——同一個模型,會問的人能得到精準的專業報告,不會問的人只能得到泛泛的廢話。
白話解說
為什麼「問法」這麼重要
LLM 是一個條件概率機器:給定輸入,它計算所有可能輸出的概率分布。你輸入的 Prompt 決定了它計算的「起點」——不同的起點,概率分布的峰值會落在完全不同的地方,輸出結果自然天差地別。
舉個最直白的例子:
- 問法一:「幫我寫一封信」→ 模型要猜:什麼信?給誰?什麼目的?語氣?格式?它只能給你一封最「統計上常見」的信,往往是一封空洞的範例信。
- 問法二:「你是一家 B2B 軟體公司的業務主管,現在要寫一封跟進信給三個月前開過會但沒有後續的潛在客戶 CFO。語氣要專業但不強迫,重點是提供一個免費試用的邀請,並說明試用後的具體成效案例。請控制在 200 字以內。」→ 這樣的輸入給了模型足夠的上下文,它的輸出空間被大幅縮小,幾乎必然會產出你真正需要的東西。
這就是 Prompt Engineering 的核心邏輯:不是讓 AI 讀心術,而是把你腦子裡的所有假設、限制、期望,都明確地說出來。
三種核心提示策略
Zero-shot 提示:直接問問題,完全不提供範例。適合模型已經充分掌握的任務,例如翻譯、文法修正、簡單摘要。缺點是輸出格式不可預測,複雜任務品質不穩定。
「請將以下文字翻譯成英文:『台灣是一個美麗的島嶼』」——這是典型的 zero-shot,因為翻譯是 LLM 最基礎的能力,不需要示範。
Few-shot 提示:在問題之前先提供 2-5 個「輸入→輸出」的範例對,讓模型從範例中「讀懂」你要的格式和邏輯,再套用到實際問題上。適合輸出格式特殊、語氣特定、或需要模仿特定風格的任務。
輸入:我昨天買的手機今天充不了電,客服電話打不通
情緒分類:憤怒
輸入:請問你們的貨幾天會到?
情緒分類:中性
輸入:謝謝你們快速處理,東西收到了很開心!
情緒分類:滿意
輸入:這個產品根本就是垃圾,我要退款
情緒分類:???
模型看了三個範例,會理解「你想要的格式是一個情緒標籤」,然後正確地輸出「憤怒」。
Chain-of-Thought(CoT,鏈式思考):要求模型在給出最終答案前,先把推理步驟寫出來。這個策略對數學推理、邏輯分析、多步驟決策類問題效果顯著。
一個讓 CoT 生效的最簡單咒語是在問題後加上:「請逐步思考,把每個步驟都寫出來,最後再給出答案。」
研究顯示,在 Google PaLM 540B 的數學推理基準測試中,加入 CoT 提示後,準確率從 17% 躍升至 58%。原因是:讓模型「說出中間步驟」,等於把複雜的一步跳躍拆成多個小預測,每個小預測都更容易做對,整體準確率自然大幅提升。
角色提示與系統提示詞
角色提示(Role Prompting) 的格式很簡單:「你是一位 [身份],具有 [專業背景],現在你需要 [任務]。」
角色提示有效的原因不是模型在「扮演角色」,而是身份描述激活了訓練語料中與這個身份相關的知識框架。當你說「你是一位有 20 年經驗的心臟科醫師」,模型會從醫學文獻、病歷討論、醫師論壇等訓練資料中提取更相關的語言模式,輸出更接近醫師思考方式的內容。
System Prompt(系統提示詞) 是對話開始前設定的固定指令,通常由開發者或企業管理員設置,用戶看不到。它的功能是:
- 定義角色與人格:「你是 OO 公司的客服助理,名叫小智,使用親切的口語體。」
- 設定行為限制:「只回答與本公司產品相關的問題,遇到敏感話題請說『我沒辦法協助這個問題』。」
- 規定輸出格式:「所有回答必須使用繁體中文,每個回答結尾都要加上客服評分邀請。」
- 注入背景知識:「公司最新的退換貨政策是……(插入政策全文)」
User Prompt 則是每輪對話中用戶的即時輸入,是動態變化的部分。一個好的 AI 產品設計,是用精心設計的 system prompt 建立穩定的行為框架,讓 user prompt 的隨機性被框架所約束。
結構化輸出:讓 AI 說人話也說機器話
當你的 LLM 輸出要被程式進一步處理(存入資料庫、呈現在前端、觸發下游 API),你需要讓模型以固定的結構格式輸出。最常見的方法是在 prompt 中明確指定格式:
請分析以下客戶留言,並以 JSON 格式輸出:
- sentiment:正面/負面/中性
- main_issue:客戶的主要問題(一句話)
- urgency:高/中/低
- suggested_action:建議的處理動作
留言內容:「我三天前下的訂單還沒寄出,客服電話一直沒人接,真的很失望。」
好的輸出 prompt 三要素:格式範例(告訴模型輸出長什麼樣)、欄位定義(每個欄位的含義和可能值)、具體資料(避免模型憑空想像)。
應用場景
| 使用場景 | 最適提示策略 | 關鍵 Prompt 技巧 | 效果說明 |
|---|---|---|---|
| 客服投訴分類自動化 | Few-shot + 結構化輸出 | 提供 5-10 個分類範例,要求 JSON 輸出 | 分類準確率提升,可直接接資料庫 |
| 法律合約風險審閱 | 角色提示 + CoT | 指定「資深合約律師」角色,要求逐條分析後給結論 | 風險遺漏率降低,推理過程可追蹤 |
| 產品文案批量生成 | Few-shot + 限制字數 | 提供 3 個品牌風格範例,限定字數和關鍵詞 | 風格一致性大幅提升 |
| 複雜財務計算解析 | CoT(逐步思考) | 明確要求「每個計算步驟都要寫出」 | 數值錯誤率降低,計算過程可查驗 |
| 多語言客服標準化 | System Prompt 語言設定 | 在 system prompt 設定語言規則和術語表 | 各語言版本術語統一,品牌語氣一致 |
常見誤區
誤區一:Prompt 越長越好
許多初學者以為 prompt 越詳細越好,於是堆了幾千字的指令。但 LLM 的注意力是有限的:過長的 prompt 中,真正關鍵的指令可能被稀釋,模型反而可能忽略某些重要要求。好的 prompt 追求的是精準而不是詳盡——把最重要的限制放在開頭或結尾(注意力機制對序列兩端敏感),把模棱兩可的說法改成明確的約束。與其寫「請寫一篇好的文章」,不如寫「請寫一篇 500 字、適合高中生閱讀的科普文章,使用日常生活比喻,避免專業術語」。
誤區二:好的 Prompt 可以讓 AI 什麼都做到
Prompt Engineering 能大幅提升輸出品質,但無法突破模型本身的能力邊界。如果底層模型沒有受過充分訓練的特定領域知識,再好的 prompt 也難以讓它生成高品質的專業輸出。例如,要求一個沒有充分訓練台灣法規資料的 LLM 提供精確的台灣稅法建議,prompt 再怎麼設計都可能出錯。這時候需要的是 RAG(提供外部知識)或微調(注入領域知識),而不是更精巧的 prompt。
誤區三:Prompt 一次寫好就永遠有效
LLM 的輸出具有隨機性(sampling temperature),而且不同版本的模型、不同時間的 API 調用,行為可能有細微差異。在生產環境中部署 Prompt,需要建立系統性的Prompt 測試集(一組標準問題和期望輸出),每次更新 prompt 或模型版本時都跑一遍測試,確認品質沒有退化。把 prompt 當成程式碼一樣進行版本控管(寫入 git repo),記錄每次修改的原因和效果,是成熟 AI 產品工程的必要實踐。
小練習
練習一:改寫模糊的 Prompt
以下是一個品質很差的 Prompt,請根據 Prompt Engineering 的原則,把它改寫成一個更有效的版本:
原始 Prompt(差版): 「幫我寫一個行銷文案。」
請依照以下結構改寫:
- 角色設定(誰在說話?)
- 任務定義(要做什麼?)
- 受眾定義(給誰看?)
- 格式與字數限制
- 語氣與限制條件
點擊查看參考答案
練習一:改寫 Prompt 參考答案
**改寫後的 Prompt(好版)**: ``` 你是一位專精 B2C 電商的資深行銷文案撰寫人,擅長為台灣年輕消費者(25-35 歲,都會區, 習慣網購)撰寫有說服力的短文案。 請為以下產品撰寫一則社群媒體(Instagram 限時動態)廣告文案: 產品:100% 天然蜂蜜礦物洗顏慕斯,主打「溫和不刺激、洗後不緊繃」。 售價:NT$450 / 150ml。 現在有首購優惠:加購第二件打七折。 要求: - 字數:80-120 字(繁體中文) - 語氣:輕鬆有趣,帶有一點台灣年輕人的口語感,但不要過度俚語 - 必須包含:一個感官形容詞描述使用感受、首購優惠資訊、至少一個 emoji - 不要使用「最好」「第一」等最高級聲稱 - 結尾加上行動呼籲(CTA) ``` **為什麼這樣寫更好**: | 改進點 | 原版問題 | 改版如何解決 | |--------|---------|------------| | 角色設定 | 無 | 指定「B2C 電商資深文案」,激活相關知識框架 | | 受眾定義 | 無 | 明確指定年齡層、地區、行為特徵 | | 產品資訊 | 無 | 提供完整產品資料,模型不需要猜 | | 格式限制 | 無 | 指定字數、平台、語氣 | | 禁止項 | 無 | 明確說明不要出現的內容,避免合規風險 |練習二:Chain-of-Thought 實戰
以下是一個業務判斷問題,請先寫出「沒有 CoT 的 Prompt」,再寫出「有 CoT 的 Prompt」,並解釋為什麼後者能得到更可靠的答案:
情境:你是台灣一家中型製造商的業務主管,有一個客戶說「你們的報價比競爭對手貴 15%,如果不降價我就不下單」。你希望 AI 幫你分析是否應該降價,以及如何回應。