M05.04|RAG 檢索增強生成:讓 AI 查資料再回答
開卷考試 vs 閉卷考試 — RAG 讓 AI 帶小抄上場
本講學習重點
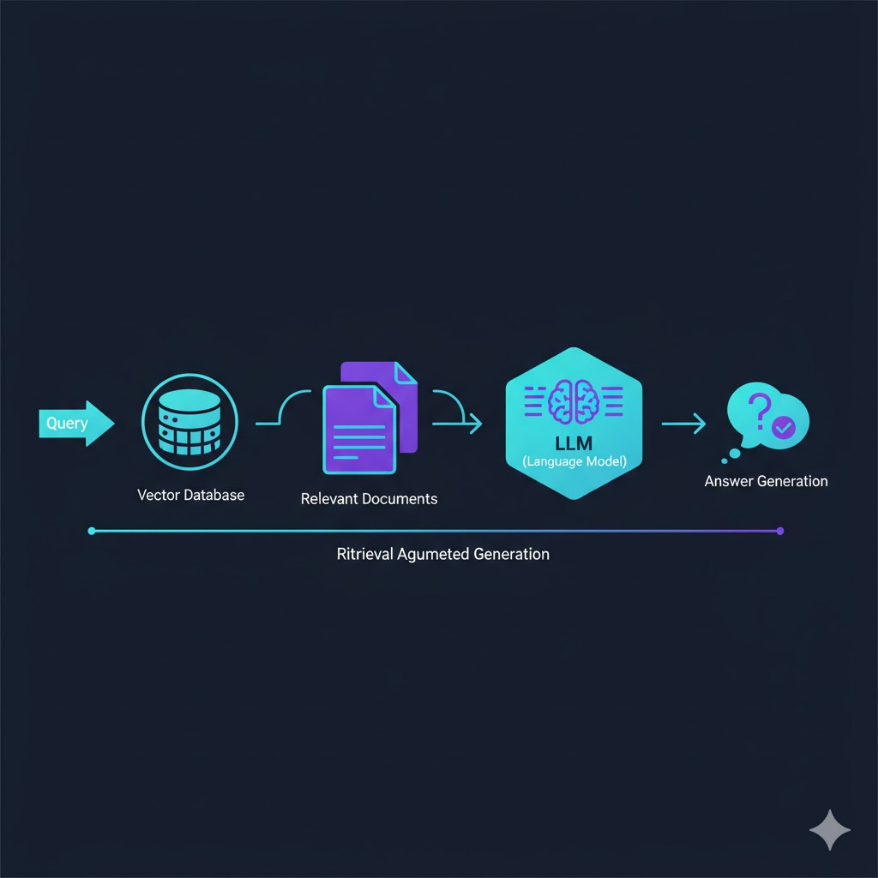
LLM 幻覺的根源:模型生成是統計取樣,不是從知識庫查詢。 當問題答案不在訓練資料中,模型仍會生成「統計上合理的文字」,但可能是錯誤的。 知識截止日期也導致模型無法回答最新資訊。 RAG 三步驟: 1. Retrieve(檢索):把用戶問題轉成 embedding,在向量資料庫中找最相似的文件片段 2. Augment(增強):把找到的文件片段插入 prompt 的上下文中 3. Generate(生成):LLM 基於增強後的 prompt 生成回答,答案有文件依據 向量資料庫:儲存文字的 embedding(高維向量),能高效地做「語義相似度搜尋」。 不同於傳統資料庫的關鍵字精確比對,向量搜尋能找到「意思相近」的內容。 常見向量資料庫:Pinecone, Weaviate, Chroma, pgvector(PostgreSQL 擴展) 文件切分(chunking)策略影響: - 切太小:每個片段缺乏上下文,模型回答片面 - 切太大:搜尋結果不精準,超過上下文視窗 - 一般建議:512-1024 token 一塊,塊間有 10-20% 重疊
🎙️ Podcast(中文)
一句話搞懂
RAG(Retrieval-Augmented Generation,檢索增強生成)就是讓 AI 在回答問題前,先去資料庫找相關資料、讀過之後再回答——從「閉卷考試」變成「開卷考試」。
白話解說
為什麼 LLM 會「亂說話」
想像你雇了一個人,他讀遍了 2022 年以前人類所有的書和網頁,記憶力超強,說話極有條理。但他有一個致命弱點:當你問他一個他不確定答案的問題,他不會說「我不知道」,而是把「聽起來合理」的內容信心十足地告訴你。這就是 LLM 的幻覺(Hallucination)問題。
幻覺的根源在於 LLM 的生成機制:它是在預測「下一個 token 最可能是什麼」,這個「最可能」是統計意義上的,不是事實意義上的。如果你問「Anthropic 的 CEO 是誰」,而訓練資料中這個問題的答案確實存在,模型通常能答對。但如果你問「我們公司今年的退稅申請進度」,訓練資料中根本沒有這個資訊,模型卻可能生成一段聽起來像是在回答這個問題的文字——完全是錯誤的,但語氣非常有自信。
此外,每個 LLM 都有知識截止日期(knowledge cutoff)。2023 年後的新法規、最新的產品規格、昨天的新聞——這些在模型訓練後發生的事,它通通不知道。對需要依賴最新資訊的業務場景(法規查詢、即時報價、產品規格確認),這是致命的限制。
RAG 的三個核心步驟
RAG 的設計思路非常直觀:與其讓 LLM 從靜態的訓練記憶中回答,不如讓它先去「查資料」,然後基於查到的資料來回答。整個流程分三步:
第一步:Retrieve(檢索)
用戶提問時,系統先把問題轉換成 embedding(高維向量),然後在向量資料庫中搜尋「語義最相關」的文件片段。例如用戶問「公司的差旅費報銷上限是多少」,系統會在公司政策文件的向量庫中找到差旅費相關的段落。
第二步:Augment(增強)
把搜尋到的文件片段(通常 3-5 個最相關的段落)塞進 LLM 的 Prompt 中,形成增強後的輸入。Prompt 的結構大致是:「你是公司的 AI 助理。以下是相關政策文件的摘錄:[插入文件片段]。請根據上述文件回答以下問題:[用戶問題]。如果文件中找不到答案,請直接說明。」
第三步:Generate(生成)
LLM 基於增強後的 Prompt 生成回答。由於 Prompt 中包含了真實的文件內容,模型的回答有了「依據」。更重要的是,你可以在 Prompt 中明確指示:「只使用提供的文件內容回答,不要依賴你的背景知識」,這樣能大幅降低幻覺出現的概率。
Embedding:把語意變成可計算的數字
Embedding(嵌入向量)是整個 RAG 系統的技術核心之一。它的作用是把任意文字轉換成高維空間中的一個點(向量),使得語義相近的文字在這個空間中距離相近。
例如,「狗」和「犬」的 embedding 向量之間的距離,遠小於「狗」和「桌子」的距離。更有趣的是:「台北市中山區」和「臺北市中山區」(繁簡差異)的 embedding 距離也很小,因為好的 embedding 模型能捕捉到語義,而不只是字面。
這讓向量搜尋能做到傳統關鍵字搜尋做不到的事:你搜尋「員工請假規定」,可能也找得到「年假和病假的申請流程」,因為兩者語義相關,即使沒有共同的關鍵字。
常用的 Embedding 模型包括:OpenAI text-embedding-3-large(1536 維)、Cohere Embed v3、以及開源的 BGE-M3(支援多語言,含繁體中文效果佳)。
文件切分(Chunking)策略
要建立 RAG 系統,首先要把企業的知識文件(PDF、Word、網頁、FAQ 等)切分成適當大小的「片段」(Chunk),再轉成 embedding 存入向量資料庫。切分策略對 RAG 效果的影響比大多數人想像的更大:
切太小(例如每 100 個字一塊):每個片段缺乏上下文,模型得到的資訊不完整。例如一段「差旅費報銷必須在出差回來後 30 天內提交,否則…」被切斷,「否則」後面的後果資訊消失了。
切太大(例如每 3000 個字一塊):搜尋精準度下降,一塊中包含太多不相關內容,而且容易超過 LLM 的上下文視窗。
實務建議:一般文件使用 512-1024 token 一塊,並設定 10-20% 的重疊(overlap)——也就是說,前一塊的結尾和後一塊的開頭有重複內容,確保不會在重要資訊的邊界處被切斷。
更進階的策略包括:語義切分(根據段落主題邊界切,而非固定字數)、層級切分(章→節→段落三層,搜尋時根據問題層次選擇粒度)。
混合搜尋:語義 + 關鍵字的結合
純向量搜尋在一些情況下反而不如傳統關鍵字搜尋:例如搜尋特定的人名、產品型號、法條編號(「勞基法第 24 條」),這些精確詞彙用語義搜尋可能找不到最相關的段落。
現代 RAG 系統通常採用混合搜尋(Hybrid Search):同時執行向量相似度搜尋和傳統全文搜尋(BM25 等),再把兩個結果用加權算法合併排序(稱為 Reciprocal Rank Fusion)。這種組合能兼顧「語義理解」和「精確匹配」,在大多數企業知識庫場景中表現最佳。
應用場景
| 企業場景 | RAG 解決的核心問題 | 知識庫來源 | 預期效益 |
|---|---|---|---|
| 法務部門法規查詢助理 | LLM 不知道最新法規修訂 | 公司法規全文 + 主管機關公告 | 查詢時間從 30 分鐘降至 2 分鐘 |
| 新人教育訓練 FAQ Bot | LLM 不知道公司內部政策 | 人資手冊、SOP 文件、常見問題 | 新人提問能即時獲得準確答案 |
| 醫療院所病歷輔助查詢 | 患者資訊不在 LLM 中 | 患者病歷系統(私有部署) | 醫師快速查閱相關病史 |
| 保險理賠問答 | 保單條款複雜且常更新 | 各險種保單條款 PDF | 客服回覆準確率提升,減少理賠糾紛 |
| 製造業設備維修手冊查詢 | 設備技術文件模型不知道 | 設備手冊、歷史維修紀錄 | 現場工程師快速定位故障排除步驟 |
常見誤區
誤區一:有了 RAG,AI 就不會再幻覺了
RAG 大幅降低了幻覺,但並不能完全消除它。有幾種情況仍可能出現幻覺:首先,如果用戶的問題在知識庫中找不到相關文件(Retrieve 失敗),LLM 可能還是憑印象回答。其次,如果切分策略導致提取的片段語境不完整,模型可能對片段進行「補全」,補入錯誤資訊。最後,LLM 的整合和摘要能力本身也可能引入偏差。解決方案是:在 system prompt 中明確要求「若文件中找不到答案,請回答『根據現有資料無法確認,請洽詢相關部門』」,並在介面上顯示「資料來源」讓用戶可以自行核實。
誤區二:RAG 和微調(Fine-tuning)是同一件事
這是兩個完全不同的技術路線。RAG 是讓模型「在推理時查資料」,不改變模型本身的參數;微調是用特定資料繼續訓練模型,改變模型的權重,讓模型「把知識記進腦子裡」。RAG 的優點是知識庫可以即時更新(新增文件、不需重新訓練)、可溯源(能顯示答案來自哪份文件);微調的優點是回應速度更快(不需查詢外部資料庫)、能改變模型的語氣和風格。兩者也可以結合:先微調讓模型學會特定的回覆風格,再用 RAG 提供即時的知識查詢能力。
誤區三:向量資料庫越大,RAG 效果越好
「把所有文件都放進去」是常見的直覺,但在實務上可能適得其反。無關的文件越多,搜尋結果中的雜訊就越多——模型可能拿到的是「相關度最高但實際上不相干」的片段,反而混淆了答案。RAG 系統的最佳實踐是建立有主題邊界的知識庫(例如,HR 知識庫、產品手冊知識庫、法規知識庫分開管理),針對不同類型的問題路由到不同的知識庫,而不是把所有文件混在一個大知識庫裡。
小練習
練習一:RAG vs 直接問 LLM 的差異辨別
以下四個業務問題,哪些「必須用 RAG」才能得到可靠答案,哪些「直接問 LLM」就夠了?請說明理由:
(a) 「Python 的 list comprehension 語法是什麼?」
(b) 「我們公司 2025 年的出差申請流程是什麼?」
(c) 「勞動基準法關於加班費的規定是什麼?」(假設法規在 LLM 訓練截止日前沒有修訂)
(d) 「上個月我們產品的 NPS 分數是多少?」
點擊查看參考答案
練習一:RAG 必要性判斷
| 問題 | 建議 | 理由 | |------|------|------| | (a) Python list comprehension 語法 | **直接問 LLM 即可** | 這是公開的程式語言語法知識,早已大量出現在 LLM 訓練資料中,且不會因公司內部資訊不同而有差異 | | (b) 公司 2025 年出差申請流程 | **必須用 RAG** | 每家公司的出差政策不同,且可能隨時更新,LLM 的訓練資料中不包含你公司的內部 SOP | | (c) 勞基法加班費規定 | **建議用 RAG** | 雖然訓練資料可能含有這條規定,但法規有修訂風險,且 LLM 可能混淆不同版本;重要法律問題建議以最新官方文件為準,RAG 接入官方條文更安全 | | (d) 上個月 NPS 分數 | **必須用 RAG(或工具整合)** | 即時營運數據不在 LLM 訓練資料中,需要連接 CRM、問卷系統等資料來源 | > **判斷框架**:問題的答案是否在「公司私有資料」或「LLM 訓練截止後的資訊」中?若是,就需要 RAG 或工具整合。練習二:設計一個 RAG 知識庫方案
你的公司是一家台灣的中型保險公司,想為客服人員建立一個「理賠查詢 AI 助理」。請回答以下三個設計問題:
問題 A:知識庫應該包含哪些文件類型?請列出至少五種。
問題 B:為什麼保險理賠的 FAQ Bot 特別不適合讓 LLM「直接回答」(不用 RAG)?請從三個風險角度分析。
問題 C:如果一個客服人員問 AI「這個客戶的車禍理賠案能賠多少」,AI 應該如何回應才是正確的設計?