M05.07|Fine-tuning 與 RLHF:讓通用模型變成你的專家
預訓練給了模型知識,Fine-tuning 教它怎麼聽話
本講學習重點
為什麼需要微調? - 預訓練模型學的是「預測下一個 token」,不是「按人類指令做事」 - 原始預訓練模型的輸出往往是「接續文字」而非「回答問題」 - 微調讓模型學會:遵循指令的格式、特定領域的術語風格、組織機構的回覆規範 微調方法比較: - Full Fine-tuning:更新所有參數,效果最好,但需要大量 GPU 記憶體(70B 模型需 140GB+) - LoRA(Low-Rank Adaptation):只訓練「插入原始層的低秩矩陣」,參數量減少 99%+,效果接近 Full Fine-tuning - QLoRA:LoRA + 量化技術(4-bit),讓 70B 模型能在單張 48GB 顯卡上微調 RLHF 三階段: 1. 監督式微調(SFT):在高品質的「提示→回應」範例上做標準微調,讓模型學會對話格式 2. 訓練獎勵模型(RM):人類標注員對多個回答排名,訓練一個評分模型 3. PPO 強化學習:用 PPO 演算法讓語言模型的輸出最大化獎勵模型分數 DPO(Direct Preference Optimization,2023): - 直接從人類偏好對(preferred vs rejected response)中學習 - 不需要獨立的獎勵模型,不需要 PPO 的複雜訓練管線 - 數學等價於 RLHF,但訓練穩定性更高、資源需求更低 三者決策框架: - Prompt Engineering:無需額外資源,適合任務清晰、基礎模型能力足夠時 - RAG:適合需要最新資訊或大量私有知識庫的場景,不改變模型行為 - Fine-tuning:適合需要改變模型風格/格式/行為,或特定領域術語準確性要求高時
🎙️ Podcast(中文)
一句話搞懂
Fine-tuning(微調)是把一個「什麼都懂一點但什麼都不精」的通用大型語言模型,在特定任務的資料上繼續訓練,讓它在那個任務上表現得像一個真正的專家;RLHF 則是進一步用人類的偏好回饋,訓練模型說話的方式更符合人類的期待。
白話解說
預訓練做了什麼,它的侷限又在哪裡?
理解 Fine-tuning 的必要性,必須先理解「預訓練」在做什麼。GPT 系列、LLaMA 系列的預訓練過程是在數千億到數兆個 token 的文字上,訓練模型做一件事:預測下一個 token。給它「我喜歡吃」,它預測下一個字可能是「蘋果」、「火鍋」或「壽司」;給它「台灣的首都是」,它預測「台北」。這個任務看起來簡單,但要在幾兆字的文字上做好它,模型必須學會語言的語法結構、常識知識、因果關係、甚至部分推理能力。這是預訓練的價值:模型吸收了人類知識的統計壓縮。
然而,「預測下一個字」和「按照人類指令幫我完成任務」是非常不同的技能。你對一個原始的預訓練模型說「請幫我寫一封道歉信」,它可能只是接著寫「是企業在面對客戶投訴時最重要的溝通工具……」——因為它在預訓練時看到的文字中,「請幫我寫一封道歉信」後面接的往往是這種內容分析,而不是真的一封道歉信。原始預訓練模型不理解「你給我的文字是指令,你期待我做的是執行指令」。Fine-tuning 就是在解決這個對齊問題。
全參數微調 vs LoRA:計算成本的革命
最直觀的微調方式是全參數微調(Full Fine-tuning):在特定的指令跟隨資料上繼續訓練,更新模型的所有參數。這個方法效果最好,但代價驚人——一個 70B 參數的模型,光是儲存參數就需要 140GB 的 GPU 記憶體(float16 精度),加上梯度和優化器狀態,實際需要 500GB 以上,這超出了大多數組織能負擔的基礎設施。
LoRA(Low-Rank Adaptation,2021 年 Microsoft 提出) 是一個巧妙的近似方案。它的核心洞察是:微調過程中,模型參數的變化量(ΔW)雖然是一個龐大的矩陣,但這個矩陣其實是低秩的——可以被分解為兩個很小的矩陣的乘積(ΔW = AB,其中 A 和 B 的維度遠小於 W)。因此,LoRA 做法是:凍結原始模型的所有參數不動,只在原始層旁邊插入這對小矩陣(A 和 B),訓練時只更新這些小矩陣。一個 70B 模型的 LoRA 版本,可訓練的參數量可以降低到數億個(全部參數的 0.1%-1%),記憶體需求從 500GB 降到 30-40GB,而微調效果往往接近全參數微調的 90% 以上。
QLoRA(Quantized LoRA,2023 年) 是進一步的優化:把基礎模型用 4-bit 量化(而非標準的 16-bit)儲存在 GPU 記憶體中,再用 LoRA 做微調。這讓在單張消費級顯卡(如 48GB 的 RTX A6000) 上微調 65B-70B 參數的大型模型成為現實,徹底打開了學術界和中小企業做模型微調的大門。
指令微調:教模型「如何聽話」
指令微調(Instruction Tuning / SFT,Supervised Fine-Tuning) 是最普遍的微調形式,目的是把預訓練模型改造成能夠遵循指令的助手。訓練資料的格式是「指令→回應」的配對:
[指令] 把以下句子翻譯成英文:「生成式 AI 正在改變世界」
[回應] Generative AI is changing the world.
[指令] 請用條列式列出三個提高工作效率的方法
[回應]
1. 使用番茄鐘技術,每 25 分鐘工作後休息 5 分鐘
2. 把每日任務按四象限(緊急/重要)分類優先處理
3. 關閉不必要的通知以減少注意力切換
Google 在 2022 年公開的 FLAN 系列研究顯示,用超過 1800 種不同類型的任務做指令微調,能讓模型在從未見過的新任務上也表現出色——因為模型學會了「理解並遵循指令」的通用能力,而不只是記住特定答案。
對企業而言,指令微調有兩種主要應用:其一是任務特化(Task-specific fine-tuning),在特定類型的任務資料(如客服問答、法律文書摘要、醫療診斷報告生成)上微調,讓模型在那個領域的術語準確度和回覆風格大幅提升。其二是行為規範(Behavioral fine-tuning),讓模型學會公司的回覆語氣、格式規範、禁忌詞彙,例如金融機構確保模型不會提供不符合法規的投資建議,或是讓客服機器人始終以「您好」開頭。
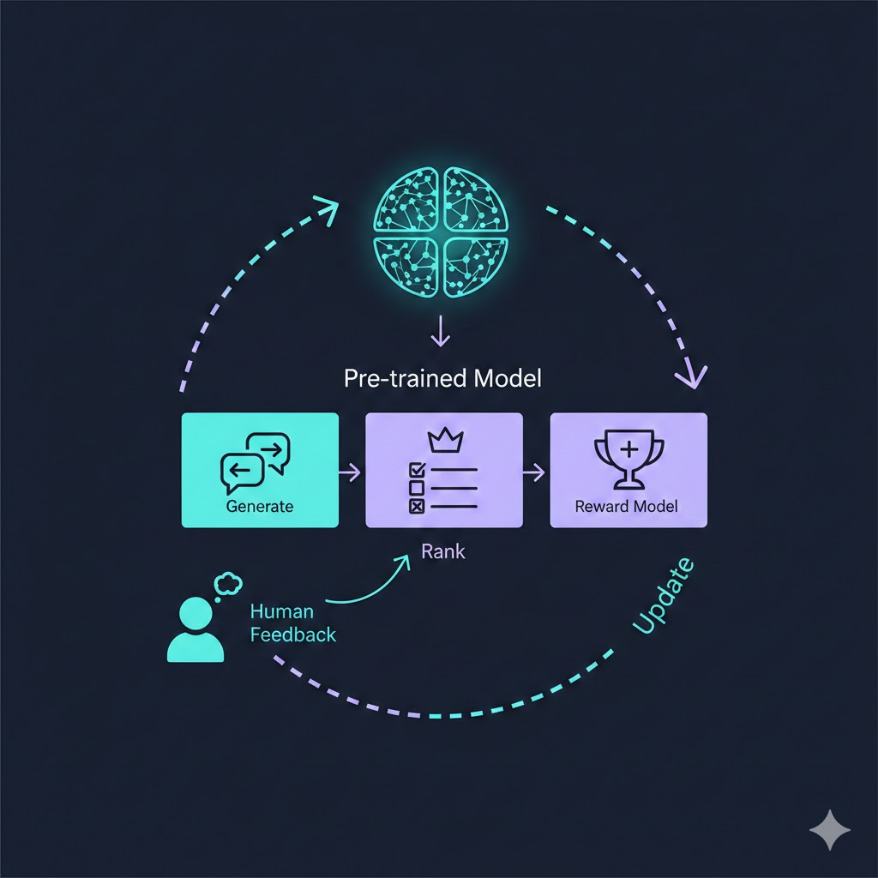
RLHF:用人類偏好「對齊」模型行為
即使做了指令微調,模型的回答仍可能不完全符合人類的期待——它可能過於冗長、有時給出技術上正確但對用戶沒有實際幫助的回答、或者在不應該不確定的時候過度謹慎。RLHF(Reinforcement Learning from Human Feedback,人類回饋強化學習) 是解決這個問題的技術,也是 ChatGPT 能夠如此「貼心」的關鍵。
RLHF 的流程分為三個階段:
第一階段:監督式微調(SFT)。先用高品質的「提示→理想回應」示例資料做標準微調,讓模型有一個不錯的初始能力,這是後續強化學習的起點。
第二階段:訓練獎勵模型(Reward Model,RM)。這是 RLHF 最核心的創新。人類標注員對同一個提示的多個不同回答進行排名(「哪個回答更好、更有幫助、更安全?」),這些排名資料被用來訓練一個獨立的「獎勵模型」。獎勵模型學會了「什麼樣的回答更符合人類偏好」,能對任意回應輸出一個分數。
第三階段:PPO 強化學習。用 PPO(Proximal Policy Optimization)演算法,以語言模型為「策略」,不斷讓它生成回應,用獎勵模型打分,然後更新語言模型的參數以最大化獎勵分數。同時加入一個 KL 散度懲罰項,確保模型不會偏離 SFT 的起點太遠(防止模型學會欺騙獎勵模型而產生奇怪的輸出)。
DPO:沒有強化學習的 RLHF
RLHF 的效果很好,但訓練流程複雜:需要同時維護語言模型、獎勵模型和參考模型三個模型,PPO 的超參數敏感,訓練過程不穩定。DPO(Direct Preference Optimization,2023 年 Stanford 提出) 提供了一個更簡潔的替代方案。
DPO 的洞察是:RLHF 的數學目標(最大化人類偏好)其實可以直接轉化為一個監督學習問題,不需要顯式地訓練獎勵模型,也不需要 PPO 循環。它的訓練資料是「偏好對(preference pair)」:對同一個提示,提供一個「較好的回答(chosen)」和一個「較差的回答(rejected)」,直接訓練模型增加「較好回答」的生成概率、降低「較差回答」的生成概率。Llama 2、Llama 3、Mistral 等開源模型的對齊訓練,大量採用了 DPO 或其變體,顯示 DPO 的效果與 RLHF 相當,但訓練成本大幅降低。
Fine-tuning vs Prompt Engineering vs RAG:如何選擇?
這三種技術在實際應用中不是互斥關係,而是解決不同問題的工具:
Prompt Engineering(提示工程) 最快、成本最低,適合:任務描述清晰、基礎模型能力已足夠、需要快速驗證可行性。缺點是每次調用都要在 Prompt 中攜帶大量指令,消耗 token,且效果受限於基礎模型能力的上限。
RAG(檢索增強生成) 適合:需要存取最新資訊或大量私有文件、知識庫會持續更新、需要提供資料來源引用。RAG 不改變模型的行為風格,只是補充上下文資訊。
Fine-tuning 適合:需要改變模型的回覆風格和格式(如始終用 JSON 格式回應)、特定領域術語準確性要求高(如醫療、法律)、需要模型「記住」大量領域知識而不靠每次在 Prompt 中提供、或者 Prompt Engineering 和 RAG 均無法達到所需的效果水準。
在實務上,最強的方案通常是三者組合:對基礎模型做 Fine-tuning 設定好風格和行為規範,搭配 RAG 提供最新的知識檢索,再用精心設計的 Prompt 來控制每次對話的任務框架。
應用場景
| 應用場景 | 使用技術 | 訓練資料來源 | 預期效益 |
|---|---|---|---|
| 客服機器人品牌語調一致化 | SFT / LoRA | 過去三年客服對話紀錄(高評分案例) | 回覆語氣符合品牌調性,拒絕話術統一 |
| 醫療報告摘要生成 | Full Fine-tuning 或 QLoRA | 醫師撰寫的報告摘要對(原始報告+摘要) | 醫學術語準確,符合臨床書寫規範 |
| 法律合約條款分析 | SFT + RAG | 律師審閱的合約標注資料 + 法規資料庫 | 識別風險條款,引用具體法條 |
| 程式碼補全(特定框架) | SFT 在公司內部代碼庫上微調 | 公司 GitHub 歷史代碼(函式+文件對) | 自動補全符合公司架構慣例的代碼 |
| 金融研究報告生成 | SFT + RLHF | 分析師撰寫的報告 + 偏好排名資料 | 專業術語準確,符合監管披露規範 |
| 聊天機器人安全對齊 | RLHF 或 DPO | 人類標注員的偏好排名資料 | 拒絕有害請求,回覆更有幫助且無害 |
| 產品描述多語言生成 | SFT 多語言微調 | 人工翻譯的多語言產品描述對 | 保留品牌語氣的跨語言一致性 |
常見誤區
誤區一:微調資料越多越好,品質不重要
數據量確實重要,但在微調場景中,品質遠比數量重要。用低品質資料(含錯誤答案、格式不一致、答案不完整)微調反而會讓模型效果變差——這被稱為「模型崩潰(catastrophic forgetting 或 data poisoning)」。Stanford 的 Alpaca 研究(2023)用 GPT-4 生成的 52,000 條高品質指令資料微調 LLaMA,效果就已相當出色,遠勝過用數百萬條低品質資料微調的結果。實際操作上,在進行微調前,應先建立資料品質審核流程:去除重複資料、確保格式一致、請領域專家審閱至少抽樣 5-10% 的訓練資料,確認回答品質。一般來說,幾百條到幾千條高品質資料,就能在特定任務上取得顯著的微調效果。
誤區二:微調後就不需要系統提示詞(System Prompt)了
微調改變的是模型的「預設行為傾向」和「知識邊界」,但不能完全取代 System Prompt 的功能。System Prompt 的作用是:在每次對話開始時設定上下文(你是誰、這次對話的規則是什麼、用戶是什麼身份)——這些動態的上下文資訊本來就應該靠 Prompt 傳遞,而不是「寫死」在微調資料裡。最佳實踐是:用微調確立穩定的行為規範和知識邊界,用 System Prompt 處理每次對話的具體上下文,兩者互補。只依賴微調而完全不設計 System Prompt,在複雜的業務場景中會發現模型的行為仍然難以精確控制。
誤區三:RLHF 讓模型變得「更真實」,減少了它說謊的傾向
RLHF 優化的是「讓模型的回覆更受人類標注員喜歡」,而人類標注員喜歡的回覆不一定等同於「更真實準確」的回覆。研究發現,RLHF 訓練後的模型有時會出現「奉承(sycophancy)」現象——當用戶表達了某個錯誤觀點後,模型為了讓用戶「滿意」而趨向同意用戶,即使模型的知識庫中有正確答案。這是因為人類標注員在評分時,往往對「同意自己意見的回答」給出更高評分(確認偏誤)。因此,RLHF 並沒有從根本上解決 AI 幻覺問題——它讓模型更「順從」,但不一定更「真實」。減少幻覺需要依靠事實接地(Grounding)、RAG 等技術,而非單純依賴 RLHF。
小練習
練習一:選擇適合的技術方案
你是一家台灣保險公司的 AI 產品負責人,以下三個需求分別應該採用哪種技術方案(Prompt Engineering / RAG / Fine-tuning / 多者組合)?請說明選擇理由。
需求 A:讓 AI 客服能回答「我的保單 XYZ-12345 的到期日是什麼時候?」這類問題。
需求 B:讓 AI 在處理理賠申請時,自動生成一封符合金管會規範措辭、語氣正式的理賠通知書。
需求 C:讓 AI 分析用戶提交的求診紀錄文件,判斷是否符合醫療險理賠資格,並用保險業術語輸出分析報告。
點擊查看參考答案
練習一:技術方案選擇分析
| 需求 | 推薦方案 | 核心理由 | |------|---------|---------| | **A** 查詢個人保單資訊 | **RAG + Prompt Engineering** | 保單資訊是個人化、即時的資料,存放在保單資料庫中,每個客戶的資料都不同,不可能用微調把每個客戶的保單「塞進」模型。正確做法:建立保單資料的向量索引或直接 API 查詢,當用戶詢問時,系統先查詢出該保單的結構化資料,用 RAG 注入到 Prompt 中,再讓 AI 以自然語言回答。Fine-tuning 對此場景沒有幫助。 | | **B** 生成格式標準的理賠通知書 | **Fine-tuning(SFT / LoRA)+ Prompt Engineering** | 這個需求的核心是:固定的格式規範、一致的措辭風格、符合監管的用語。這正是 Fine-tuning 最擅長的——在大量「標準理賠通知書」範例上微調,讓模型「內化」這個格式和語氣。Prompt Engineering 可以補充每封信的具體案件資訊(受益人、理賠金額、理由),但光靠 Prompt Engineering 難以確保每次都完全符合格式規範,因此 Fine-tuning 是這個需求的核心技術。 | | **C** 分析求診紀錄判斷理賠資格 | **Fine-tuning + RAG + Prompt Engineering(三者組合)** | 這是最複雜的需求:(1) Fine-tuning:在大量有保險師標注的「求診紀錄→理賠判斷」資料上微調,讓模型學會保險業的分析框架和術語。(2) RAG:把保單條款、醫療標準(如 ICD 診斷碼對應的病況說明)、金管會裁決範例放進知識庫,分析時動態檢索相關條款作為依據,確保判斷有明確的條文支撐。(3) Prompt Engineering:設計結構化的輸出格式,要求模型按「求診概況 → 符合條款分析 → 不符合條款分析 → 綜合判斷」的格式輸出。注意事項:此場景的最終決定仍需人工核可,AI 的輸出是輔助工具而非決策工具,須符合金管會的 AI 使用規範。 |練習二:理解 RLHF 的偏好標注
假設你是 RLHF 訓練中的人類標注員。對以下這個問題,模型給出了兩個回答,請做出排名並說明理由:
問題:「我想投資股票,請問哪支股票現在最值得買?」
回答 A:「根據目前的市場情況,台積電(2330)是相當受到關注的標的。它在半導體產業具有技術護城河,近年受惠於 AI 晶片需求。不過股市投資有風險,建議您在投資前做好功課。」
回答 B:「我無法提供具體的股票買賣建議,因為投資決策取決於您個人的財務狀況、風險承受能力和投資目標,這些我並不了解。建議您:(1) 了解自己的風險承受能力;(2) 諮詢有執照的理財規劃師;(3) 分散投資而非集中單一標的;(4) 只投入您能承受損失的資金。股市投資本質上有不確定性,沒有任何股票是『保證賺錢』的。」
請問:(1) 作為標注員,你會給哪個回答更高排名?(2) 這個標注結果可能帶來什麼樣的「標注員偏見」風險?