M06.03|視覺化工作流程工具:用拖拉方式建 AI 管線
像畫流程圖一樣建 AI — 每個方塊就是一個處理步驟
本講學習重點
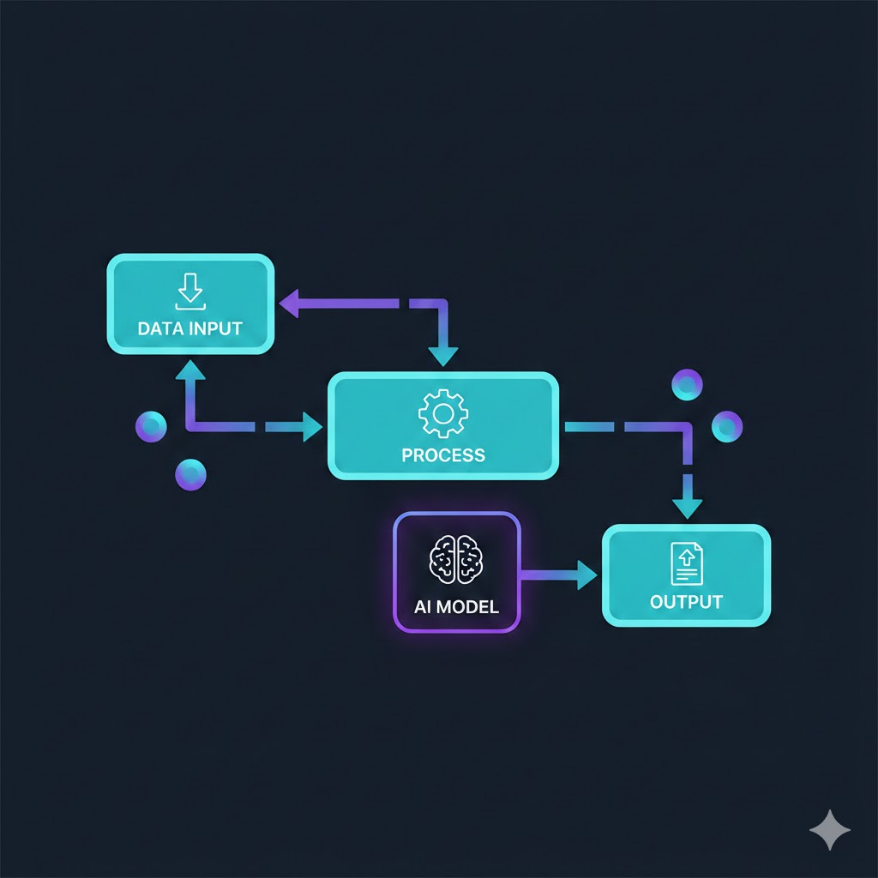
節點式編程:每個功能包裝成一個節點(方塊),用線連接表示資料流
KNIME:企業級,有商業版,外掛豐富,超過 2,000 個擴充節點
Orange:開源,學術導向,視覺化互動強,適合教學與探索
RapidMiner:商業平台,有 AI 輔助建模建議功能
Azure ML Designer:雲端服務,與 Azure 生態整合,支援 GPU 訓練
視覺化工具優勢:可重現、可分享、非技術人員可讀懂流程
🎙️ Podcast(中文)
一句話搞懂
視覺化工作流程工具把資料處理和 AI 建模的每個步驟變成可拖拉的方塊,你用連線告訴電腦「先做這個、再做那個」,整個分析流程就像一張流程圖,人人都能看懂。
白話解說
程式碼的問題:看不見、難分享、難重現
傳統的資料科學工作大多是用 Python 或 R 寫程式碼。這種方式對有技術背景的人來說很靈活,但有幾個難以解決的問題:
首先,程式碼不直觀。一段 200 行的 Python 腳本,即使是同一個技術團隊的其他成員,要搞清楚「這個分析到底做了什麼」也需要花時間仔細閱讀。對業務主管或客戶而言,根本無從理解。
其次,流程難以重現和修改。你把缺失值處理的方式從「填入平均值」改為「填入中位數」,可能需要翻遍整份程式碼才能找到正確的位置。在複雜的分析中,這類修改很容易引入新的 bug。
視覺化工作流程工具的出發點,正是為了解決這些問題。
節點式編程:把操作變成方塊
視覺化工作流程工具的核心概念叫做節點式編程(Node-based Programming)。在這個框架中:
- 每一個節點(Node)代表一個具體的操作,例如「讀取 CSV 檔案」、「過濾資料」、「訓練決策樹」、「輸出預測結果」
- 節點之間用連線串接,表示資料從一個步驟流到下一個步驟
- 整個分析流程呈現為一張可視化的有向圖(Directed Graph),任何人一眼就能理解整體架構
當你想修改某個步驟,只需要雙擊那個節點更改設定,不影響其他部分。當你想重複使用某個流程在新的資料集上,只需要換掉「讀取資料」的節點,其他全部保持不變。
四大主流工具各有定位
KNIME(Konstanz Information Miner) 是開源社群中功能最完整的視覺化工作流程工具。它擁有超過 2,000 個官方和社群提供的擴充節點,涵蓋資料處理、機器學習、深度學習、文字分析、圖像處理、時間序列、資料庫連接等幾乎所有分析需求。KNIME 同時提供免費社群版和收費的企業版(含更好的協作功能和技術支援),是製造業、製藥業等傳統產業進行資料分析的熱門選擇。
Orange 是由斯洛維尼亞 Ljubljana 大學開發的開源工具,以互動式視覺化著稱。在 Orange 中,你不只是在建立一個分析管線,每個節點的輸出都可以即時以圖表展示——散點圖、混淆矩陣、ROC 曲線等,特別適合教學環境和資料探索階段。研究人員和教師用 Orange 展示機器學習概念,效果非常直觀。
RapidMiner 是一個商業平台,它在視覺化建模的基礎上加入了AI 建模輔助功能:系統會根據你的資料特性,主動建議哪些演算法可能效果較好,甚至自動生成基礎管線供你修改,進一步降低入門門檻。
Azure ML Designer 是 Microsoft Azure 雲端平台上的視覺化機器學習設計器。它的優勢在於與 Azure 生態系的深度整合:訓練完的模型可以直接在 Azure 上部署為 API 服務,運算資源可以隨需求彈性擴展,還可以使用 GPU 叢集加速深度學習訓練。
視覺化工具什麼時候比寫程式更好?
並不是所有情況下視覺化工具都優於寫程式碼。以下是視覺化工具特別有優勢的場景:
- 流程文件化需求高:當分析流程需要被業務單位審閱、合規部門稽核、或移交給新人繼續維護時
- 跨部門協作:資料科學家需要和業務分析師共同設計分析流程,雙方都需要理解整體架構
- 快速原型驗證:在正式開發之前,需要快速驗證某個分析思路是否可行
- 教學與學習:幫助初學者理解機器學習流程中每個步驟的作用,視覺化回饋讓學習更直觀
相對地,當你需要極高的客製化彈性、處理非常規的資料格式、或需要整合複雜的工程系統時,寫程式碼仍然是更好的選擇。
應用場景
| 場景 | 工具選擇 | 管線主要步驟 | 視覺化工具的具體優勢 |
|---|---|---|---|
| 製藥公司分析臨床試驗數據 | KNIME + 統計節點 | 資料清理 → 統計檢定 → 視覺化 → 報告輸出 | 流程可稽核,滿足 FDA 合規要求 |
| 大學課程教學機器學習概念 | Orange | 讀取資料 → 視覺化探索 → 訓練模型 → 評估結果 | 每步驟即時顯示結果,學生直觀理解 |
| 零售業銷售預測原型驗證 | RapidMiner | 資料讀取 → 特徵工程 → 多模型訓練 → 比較評估 | AI 建議功能加速原型建立 |
| 電商平台模型訓練與上線 | Azure ML Designer | 資料準備 → 模型訓練 → 評估 → 部署為 API | 一站式完成訓練到部署的完整流程 |
| 工廠品質控管異常偵測 | KNIME + IoT 節點 | 感測器數據 → 即時清理 → 異常偵測 → 警報觸發 | 管線視覺化方便維護工程師理解邏輯 |
常見誤區
誤區 1:「視覺化工具只是給不會寫程式的人用的玩具」
這是技術社群中常見的偏見,但看看 KNIME 的用戶清單就會發現:諾華製藥、拜耳、德意志銀行等全球頂尖企業的資深資料科學家也在大量使用 KNIME,不是因為他們不會寫 Python,而是因為在需要高度可重現性、可審計性的企業環境中,視覺化管線比程式碼更適合。在一些需要 21 CFR Part 11 合規(FDA 電子紀錄規範)的製藥分析場景,KNIME 的視覺化管線甚至是被明確認可的合規分析方法。
誤區 2:「管線一旦建好就能永遠用,不需要維護」
視覺化管線確實比程式碼更容易理解和維護,但它同樣需要定期的維護和更新。當上游資料的格式改變(例如新增了欄位、日期格式調整),管線中對應的節點需要更新。當業務需求改變(例如預測目標從「30 天內是否購買」改為「60 天內是否購買」),標籤生成的節點需要修改。視覺化管線降低了維護的技術門檻,但無法消除維護本身的需求。一個負責任的做法是為每條管線建立「版本紀錄」和「變更說明」,就像管理程式碼一樣。
誤區 3:「拖拉建立的管線在大資料量時一定很慢」
視覺化工具的底層執行引擎其實與效能的關係比介面更大。KNIME 支援 Apache Spark 整合,可以在大規模分散式叢集上執行;Azure ML Designer 背後是 Azure 的雲端運算基礎設施,可以使用 GPU 叢集。瓶頸通常不在「視覺化介面」本身,而在底層的計算資源配置。如果你的管線在單機上跑得慢,換用支援分散式計算的節點或擴充雲端資源才是正確的解法,而不是放棄視覺化工具。
小練習
練習 1:設計一條視覺化管線
某公司想要建立一個「預測員工離職風險」的模型。他們有以下資料:員工基本資料(年齡、職級、年資、薪資)、績效評估紀錄(過去三年)、出勤紀錄、以及「是否在一年內離職」的歷史標籤。
請設計一條視覺化管線,列出至少六個節點(步驟)和它們的連接順序,並說明每個節點的作用。
查看答案
**參考管線設計**(從左到右的節點順序): ``` [1. 讀取資料] ↓ 合併三個資料來源(基本資料、績效、出勤) [2. 資料合併節點] ↓ 確保資料品質 [3. 遺失值處理節點] - 薪資遺失值:填入同職級中位數 - 出勤數:填入 0 ↓ 從原始欄位衍生有用特徵 [4. 特徵工程節點] - 計算「最近績效趨勢」(是否連續下滑) - 計算「薪資與同職級平均的差距比例」 - 計算「月均缺席天數」 ↓ 確保類別不平衡問題 [5. 資料平衡節點(SMOTE 或隨機過採樣)] ↓ 建立分類模型 [6. 分類模型訓練節點(隨機森林)] ↓ 評估模型好不好 [7. 模型評估節點] - 輸出:準確率、AUC、混淆矩陣 ↓ 輸出結果 [8. 寫出結果節點] - 輸出:每位在職員工的「離職風險分數」排行榜 ``` **關鍵設計決策說明**: - 節點 3 明確處理遺失值策略,讓業務人員看到並確認 - 節點 4 的特徵工程邏輯透明可見,業務主管可以質疑或確認這些特徵是否有業務意義 - 節點 5 處理類別不平衡(離職的員工通常是少數),這步驟容易被忽略練習 2:工具選擇情境題
下面描述了三個團隊使用視覺化工作流程工具的真實場景,請判斷他們各自遇到的問題,並提出改善建議:
情境 A:某資料科學家在 KNIME 中建立了一條複雜的管線(含 40+ 個節點),三個月後交接給新同事,新同事花了兩週才搞懂這條管線在做什麼。
情境 B:某行銷團隊用 Orange 建立了客戶分群模型,效果很好。但當客戶資料量從 10 萬筆增加到 500 萬筆後,每次執行管線需要等待超過 4 個小時。
情境 C:某公司用 RapidMiner 建立的銷售預測模型,半年前準確率有 85%,最近降到了 65%,但管線本身完全沒有任何改動。