共 10 講
M04.01
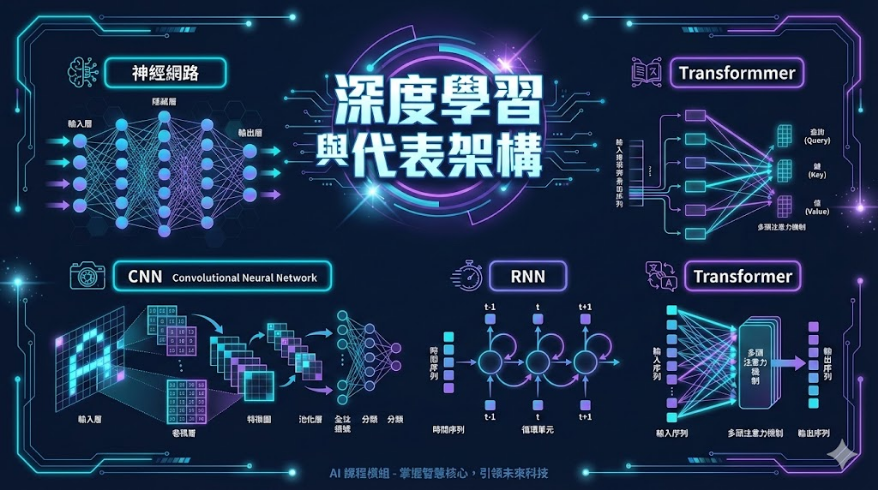
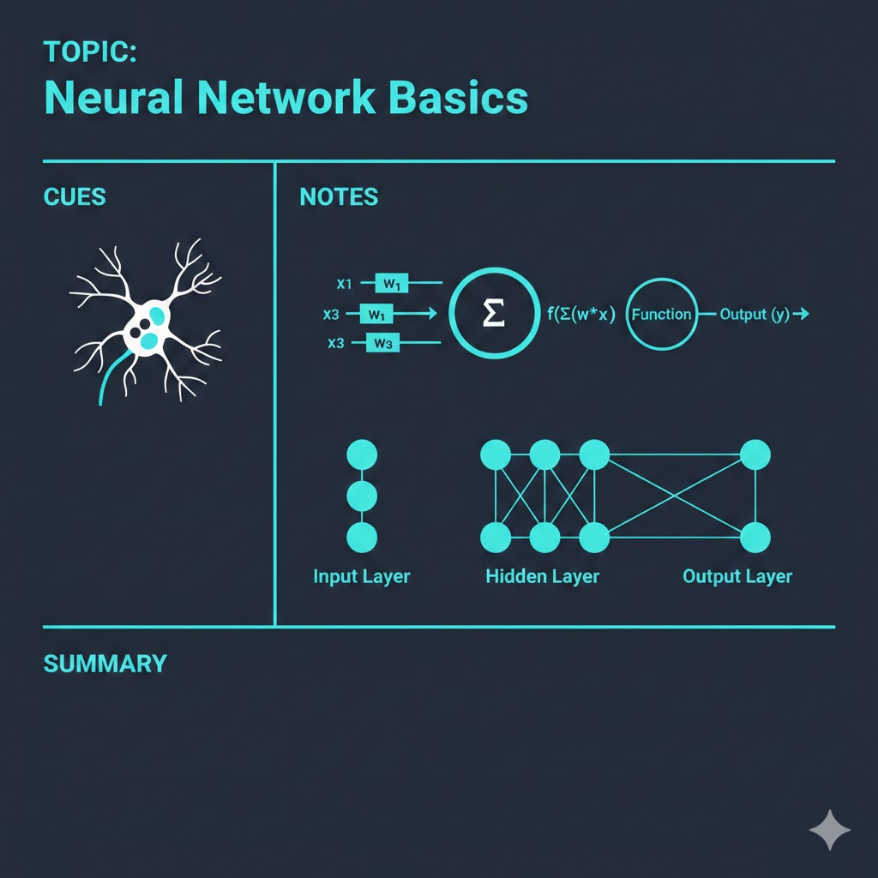
神經網路基礎:從生物神經元到人工神經元
AI 的大腦不是真的腦 — 但運作邏輯有幾分相似
M04.02
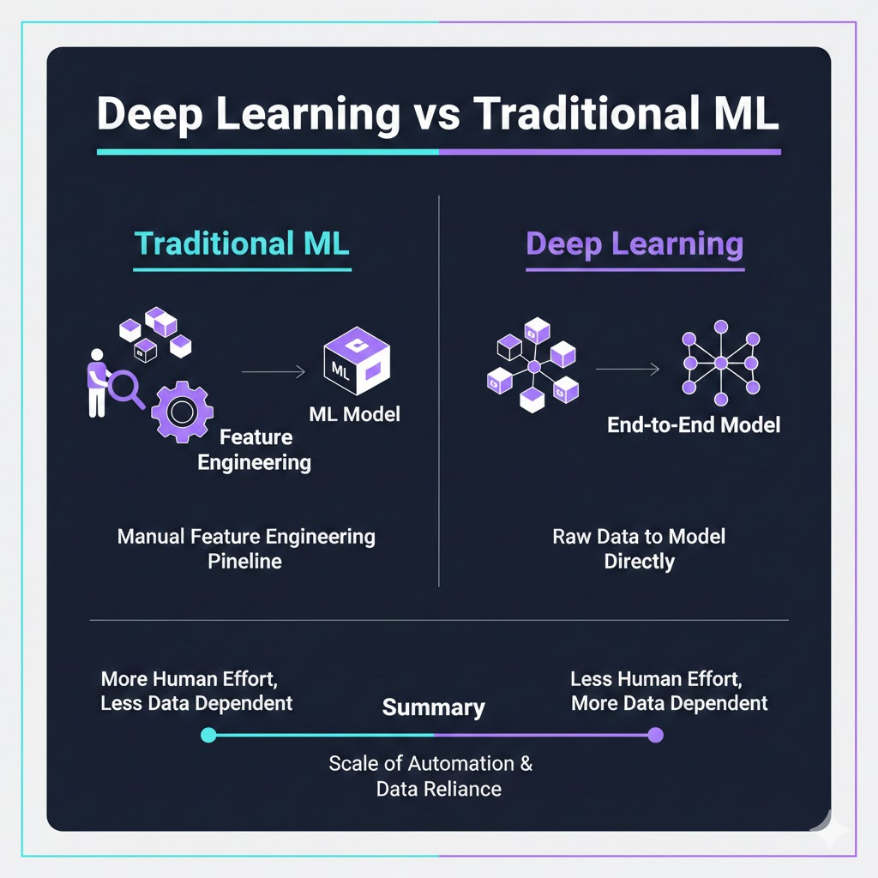
深度學習 vs 傳統機器學習:什麼時候該用深度學習
深度學習不是萬能鑰匙 — 資料少、要解釋的場景,傳統 ML 可能更好

M04.03
CNN 卷積神經網路:讓 AI 學會看圖
CNN 不是一次看整張圖 — 它像用放大鏡一小塊一小塊地掃描
M04.04
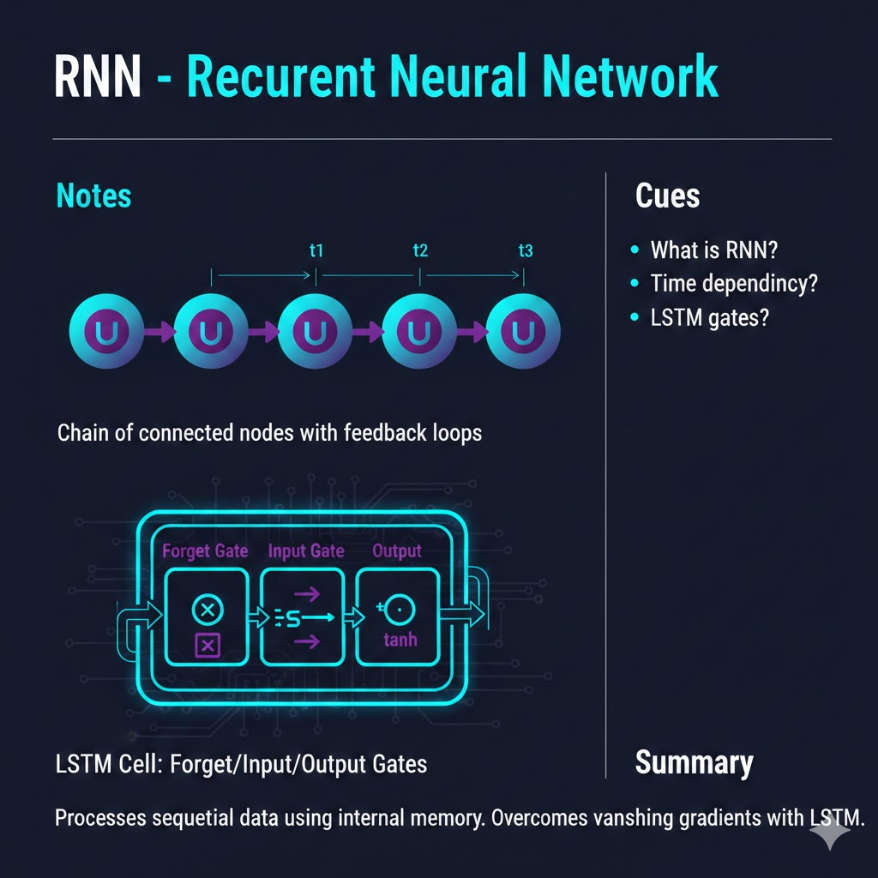
RNN 與序列模型:讓 AI 理解時間順序
RNN 有記憶 — 它知道前面發生了什麼,才能預測接下來會發生什麼
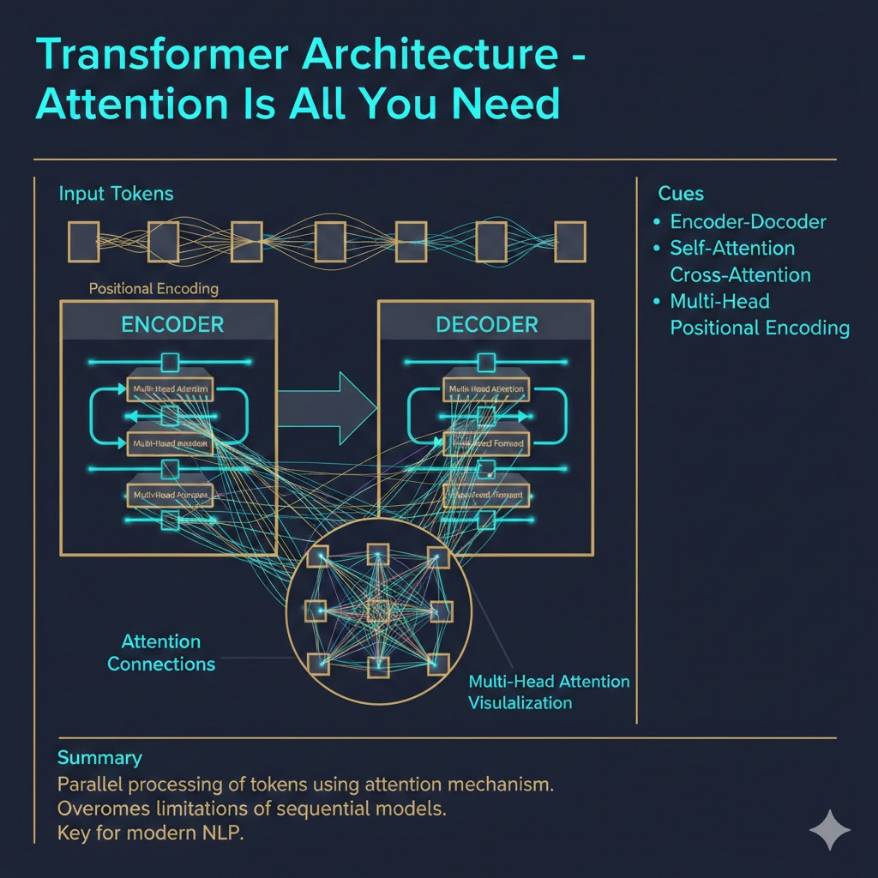
M04.05
Transformer 架構:AI 革命的核心引擎
Attention Is All You Need — 一篇論文改變了整個 AI 產業
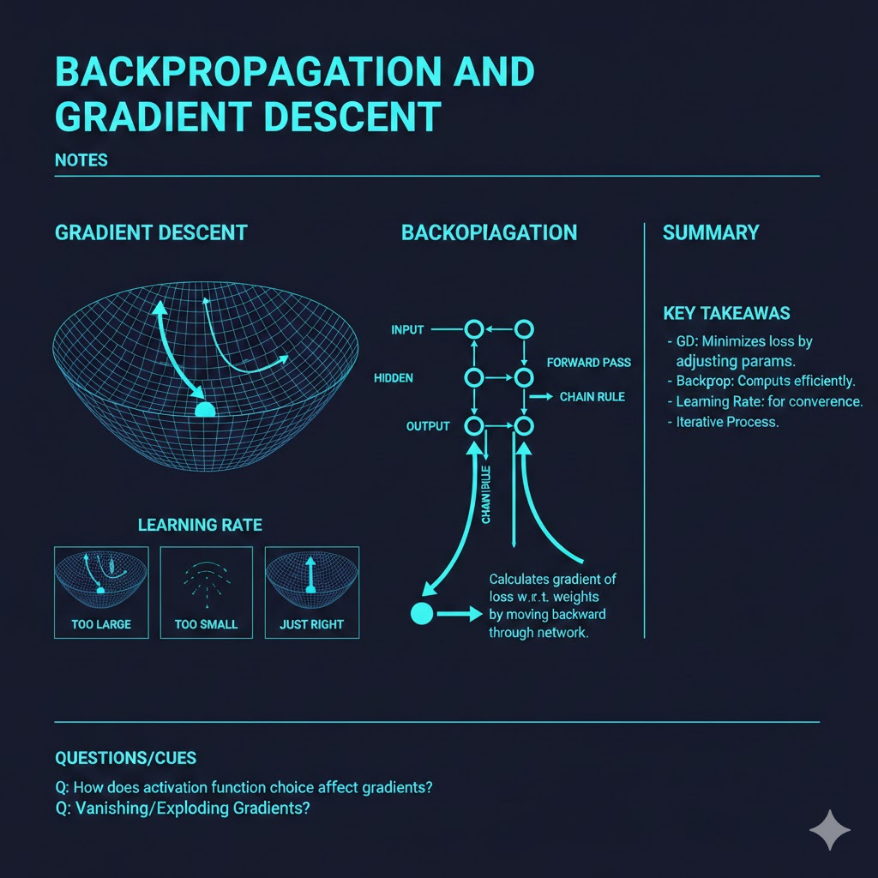
M04.06
反向傳播與梯度下降:AI 怎麼從錯誤中學習
模型答錯了怎麼辦?算出錯多少、往對的方向調整 — 重複幾百萬次
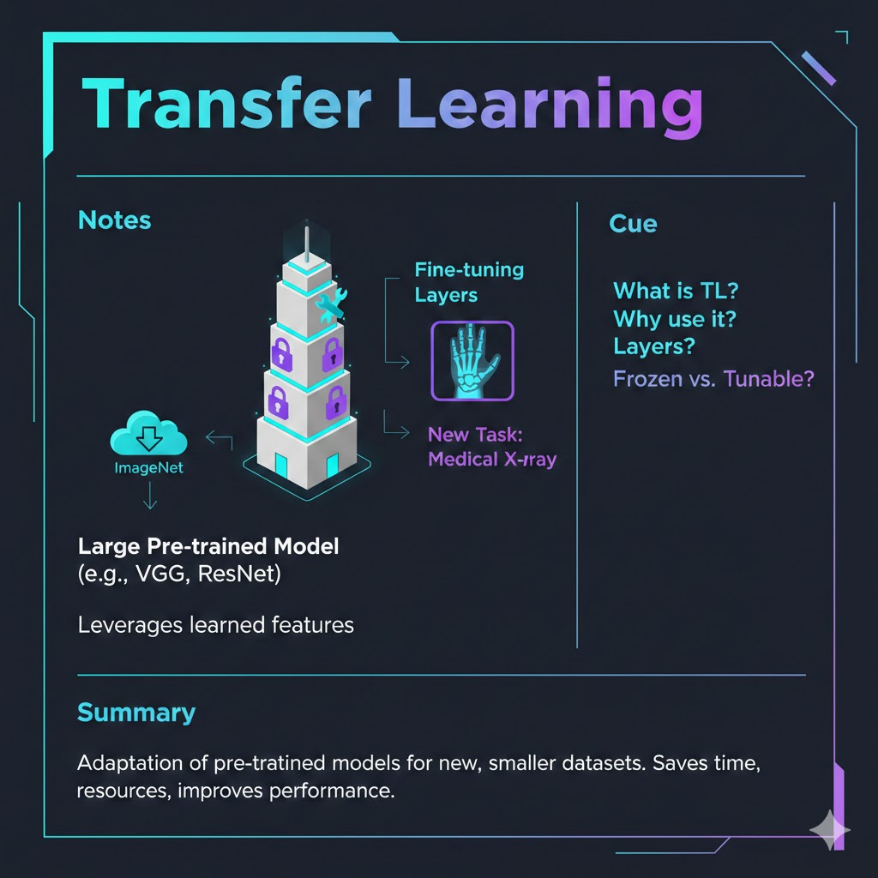
M04.07
遷移學習:站在巨人的肩膀上
不用從零開始 — 用別人訓練好的模型當基底,再微調成你的專家
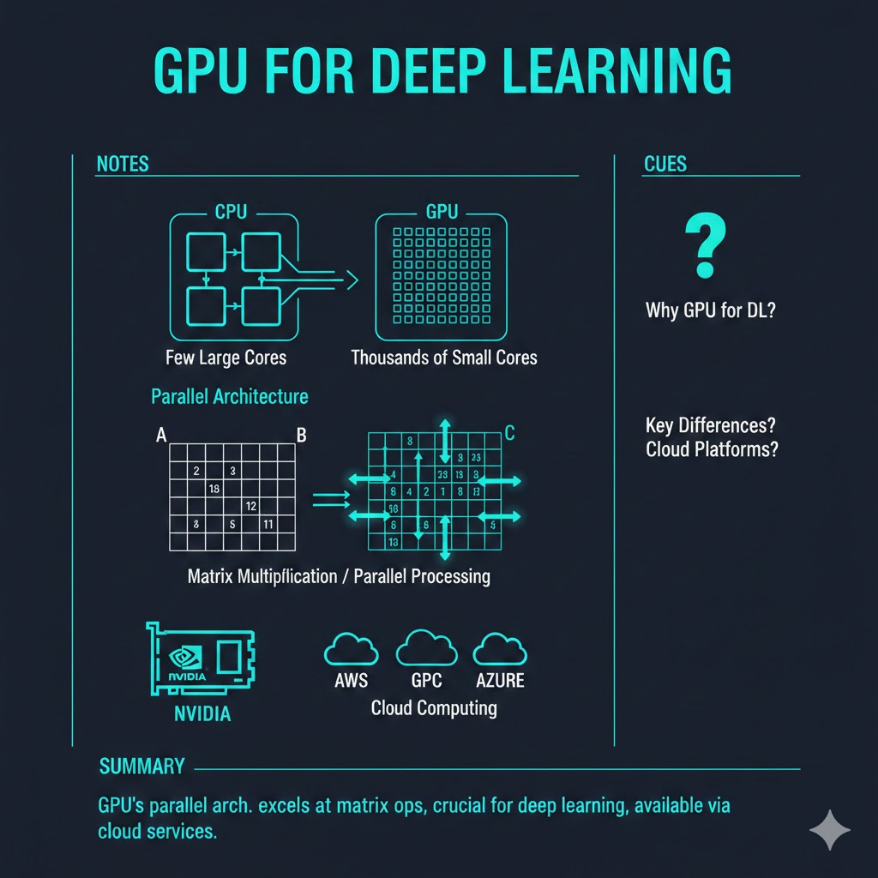
M04.08
GPU 與深度學習硬體:為什麼訓練 AI 需要顯示卡
CPU 是全才教授,GPU 是千人工廠 — 矩陣運算要的是人海戰術

M04.09
深度學習框架:PyTorch vs TensorFlow
工具不重要?錯了 — 選錯框架可能讓你的專案多花三個月

M04.10
深度學習的局限與未來:不是所有問題都需要深度學習
深度學習很強,但它不擅長小數據、要解釋、要推理的場景