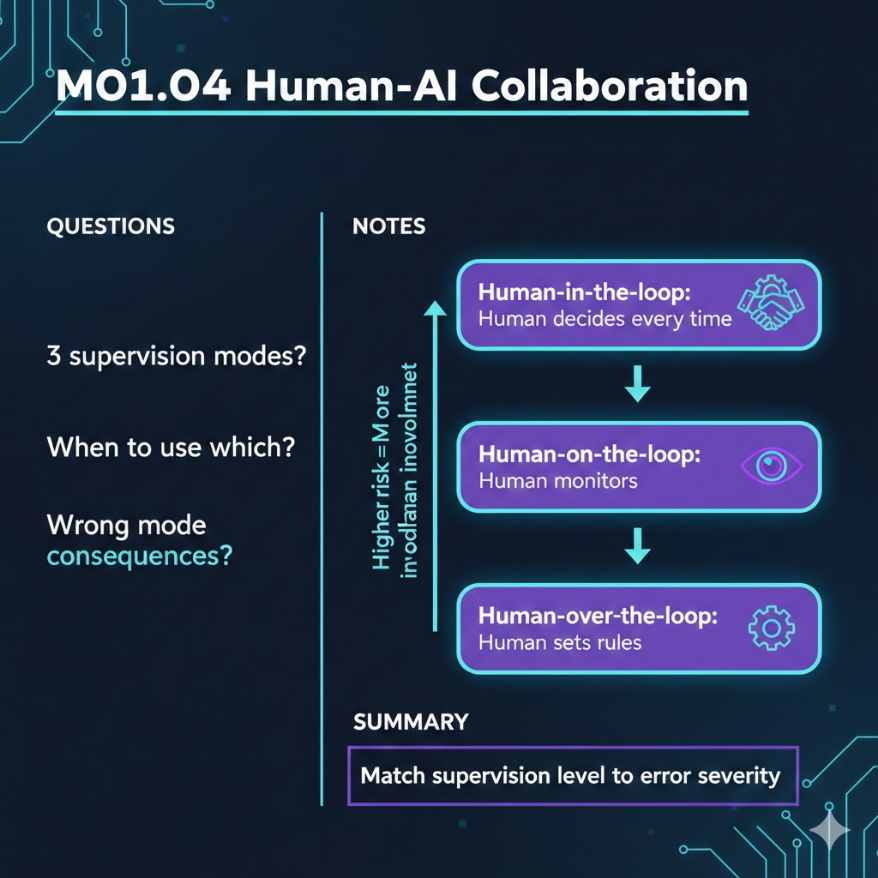
M01.04|人機協作三種監督:Human-in/on/over-the-loop
不是「AI 取代人」或「人管 AI」,而是找到對的合作模式
本講學習重點
In-the-loop人決策、On-the-loop人監看、Over-the-loop人定規則
依錯誤後果嚴重度:越嚴重人參與越多
高風險用太少監督會出大事,低風險用太多監督會拖垮效率
可以,應隨信任度與法規環境動態升降級
🎙️ Podcast(中文)
一句話搞懂
人跟 AI 的合作模式不是只有「全部交給 AI」或「全部人來做」,而是根據風險高低,選擇「人決定、AI 輔助」、「AI 執行、人監看」或「人定規則、AI 自主運作」三種模式。
白話解說
想像三種不同的開車方式。第一種:你自己開車,但車上有導航系統建議路線,最終轉不轉彎你自己決定 — 這就是 Human-in-the-loop(人在迴圈中),每一個關鍵決策都由人做,AI 只是提供建議。第二種:你開啟了車道維持和自動跟車功能,車子自己在開,但你的手放在方向盤上隨時準備接手 — 這就是 Human-on-the-loop(人在迴圈上),AI 負責執行,人負責監看,異常時介入。第三種:你設定好目的地和「不走收費道路」的條件,然後完全交給自動駕駛 — 這就是 Human-over-the-loop(人在迴圈外),人只設定目標和邊界,AI 在框架內自主運作。
這三種模式沒有好壞之分,只有「適不適合」的差別。關鍵判斷標準是:如果 AI 犯錯,後果有多嚴重? 後果越嚴重,人的參與程度就要越高。醫療診斷、司法判決、貸款審批這類「錯了會改變一個人人生」的場景,必須用 Human-in-the-loop。內容推薦、廣告投放這類「錯了頂多浪費一點預算」的場景,可以用 Human-over-the-loop。
很多 AI 專案失敗不是因為技術不行,而是選錯了監督模式。要不就是在高風險場景用了太少的人類監督(結果出大事),要不就是在低風險場景用了太多人類審核(結果效率比不用 AI 還差)。
應用場景
場景一:醫院放射科導入 AI 影像判讀 AI 系統掃描 X 光片後標記出疑似病灶區域,但最終診斷必須由放射科醫師確認。這是典型的 Human-in-the-loop — AI 先篩選、標記,人類做最終判斷。這個設計的好處是:AI 幫醫師省去逐張掃描的時間,讓醫師把精力集中在真正需要判斷的影像上。但最終蓋章的一定是醫師,不是 AI。
場景二:電商平台的商品推薦系統 推薦系統根據用戶行為自動推薦商品,營運團隊設定了幾條規則:不推薦違禁品、不對未成年推薦成人商品、同一商品不連續推薦超過三次。在這些規則內,AI 自主運作。營運團隊每週看一次推薦效果報告,必要時調整規則。這是 Human-over-the-loop 的做法,適合這種「錯了不會出大事、但需要規模化運作」的場景。
監督模式選擇框架
| 判斷維度 | Human-in-the-loop | Human-on-the-loop | Human-over-the-loop |
|---|---|---|---|
| 錯誤後果 | 嚴重且不可逆 | 中等,可補救 | 輕微,可容忍 |
| 決策速度需求 | 可以等人決定 | 需要即時但可中斷 | 必須即時大量處理 |
| 法規要求 | 法規要求人類決策 | 法規要求人類監督 | 無特殊法規要求 |
| 典型場景 | 醫療診斷、司法量刑 | 自動駕駛、工廠品管 | 內容推薦、垃圾郵件過濾 |
| AI 角色 | 建議者 | 執行者(受監督) | 自主代理 |
| 人的角色 | 決策者 | 監督者 | 規則制定者 |
常見誤區
-
「Human-in-the-loop 最安全,全部都用這個就好」 — 如果每一封垃圾郵件都要人類審核才能刪除,你的信箱一天就爆了。過度監督會讓 AI 完全失去效率優勢,而且當人類要審核的量太大時,反而會因為疲勞而漏看真正重要的案例,這叫做「警報疲勞」(Alert Fatigue)。
-
「我們有人在監督,所以 AI 出錯不是我們的責任」 — 「有人在看」不等於「有效監督」。如果監督者沒有足夠的專業知識來判斷 AI 的輸出是否正確,或者 AI 的輸出速度快到人根本來不及審查,那這個監督就是形式上的。設計監督機制時,必須確保監督者有能力、有時間、有權力去否決 AI 的決定。
-
「上線後就不用再調整監督模式了」 — 監督模式應該隨著信任度變化而調整。一個新上線的 AI 系統可能先用 in-the-loop 模式觀察幾個月,確認準確率穩定後再切換到 on-the-loop。反之,如果法規環境變了或 AI 表現退化,也應該把監督等級拉高。
小練習
-
模式判斷:以下場景分別適合哪種監督模式?(a) AI 自動生成社群媒體貼文草稿 (b) AI 在工廠產線上即時偵測瑕疵品並自動剔除 (c) AI 協助法官計算刑期建議。請說明你的判斷理由。
-
設計練習:你的公司想用 AI 來自動回覆客戶的退款申請。退款金額從 100 元到 100,000 元不等。請設計一個分級監督機制 — 什麼條件下用 Human-over-the-loop?什麼條件下升級為 Human-in-the-loop?判斷的依據是什麼?