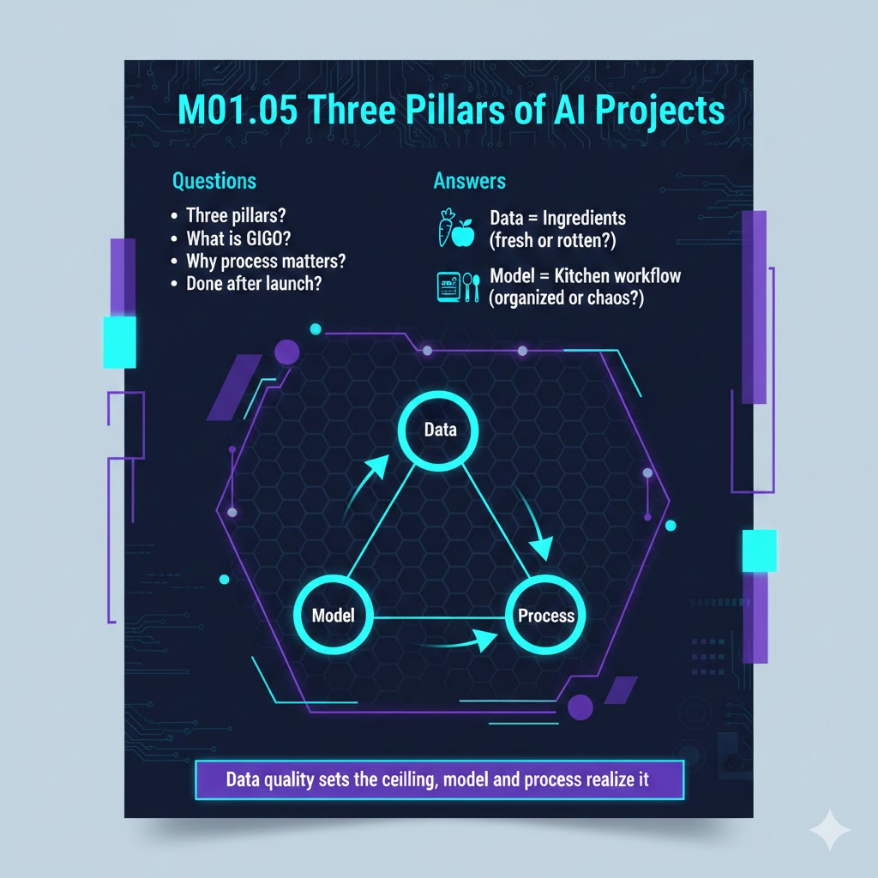
M01.05|AI 專案成功三要素:資料、模型、流程
沒有好資料,再厲害的模型也只是「垃圾進、垃圾出」
本講學習重點
資料(食材)、模型(食譜)、流程(廚房動線)
Garbage In Garbage Out,爛資料只會產出爛結果
沒有好流程,IT和業務各說各話,問題定義都對不齊
不是,上線才是開始,需持續監控防止模型衰退
🎙️ Podcast(中文)
一句話搞懂
AI 專案的成功取決於三根柱子 — 好的資料(食材)、對的模型(食譜)、完整的流程(廚房動線),缺了任何一根,整道菜就會崩塌。
白話解說
把 AI 專案想成開一家餐廳。資料就是食材:如果你買的蔬菜爛了一半、肉品標示不清楚、調味料過期了,就算請到米其林三星主廚也做不出好菜。這就是 AI 界最經典的一句話:「Garbage In, Garbage Out」(垃圾進、垃圾出)。很多公司花大錢買最先進的 AI 模型,卻不肯花時間整理資料,就像買了頂級廚具卻用爛食材,結果當然是災難。
模型就是食譜:做一碗滷肉飯不需要法式料理的食譜。同樣的道理,預測下個月銷量不需要用到百億參數的大型語言模型,一個簡單的迴歸模型可能就夠了。選模型的原則是「夠用就好」,不是越大越新越好。大模型需要更多資料、更多運算資源、更長的訓練時間,而且越複雜的模型越難解釋它為什麼做出某個決定。
流程就是廚房動線:就算食材新鮮、食譜正確,如果廚房裡的動線一團亂 — 備料區跟出餐口擠在一起、沒有品管流程、客人點了菜卻沒人通知廚房 — 餐廳一樣會倒。AI 專案的流程包括:問題定義、資料收集與清洗、模型訓練與驗證、部署上線、持續監控與更新。每個環節都不能跳過,尤其是最後的「持續監控」— 很多專案上線後就沒人管了,模型的預測準確率慢慢下降(稱為 Model Drift),半年後已經跟亂猜沒兩樣,但因為沒人在看,大家還以為 AI 運作正常。
應用場景
場景:一個三根柱子都出問題的真實案例 某家中型製造公司想用 AI 預測設備故障,希望在機器壞掉之前就排好維修,減少停機損失。結果這個專案花了八個月、兩百萬預算,最後宣告失敗。覆盤發現三根柱子全倒了:
- 資料問題:工廠過去的維修紀錄都寫在紙本表單上,字跡潦草、格式不一致,有的寫「馬達異常」、有的寫「M-1 故障」、有的只寫「修好了」。數位化後的資料品質極差,AI 根本學不到有意義的模式。
- 模型問題:廠商推薦了一個需要十萬筆以上資料才有效的深度學習模型,但這家工廠三年來總共只有 800 筆維修紀錄。資料量根本撐不起這麼複雜的模型。
- 流程問題:專案由 IT 部門主導,但維修知識全在老師傅的腦袋裡。IT 部門不懂設備、老師傅不懂 AI,兩邊從來沒有好好坐下來對齊「到底要預測什麼」。最後 AI 預測的「故障」跟老師傅認知的「故障」定義根本不同。
如果這家公司先從流程著手(讓 IT 和維修部門一起定義問題)、再處理資料(把紙本紀錄統一格式、建立標準化的數位紀錄流程)、最後選擇適合小資料量的模型(例如統計方法或簡單的機器學習),這個專案成功的機率會高很多。
常見誤區
-
「資料越多越好」 — 資料的品質遠比數量重要。一萬筆標記錯誤的資料,不如一千筆標記正確的資料。而且有時候資料太多反而會引入雜訊。真正的重點是:資料是否能代表你想解決的問題?標記是否一致且正確?有沒有涵蓋各種邊界情況?
-
「先選模型,再去找資料」 — 這是本末倒置。正確的順序是:先釐清問題、再盤點手上有什麼資料、然後根據資料的特性和數量選擇適合的模型。就像你應該先看冰箱裡有什麼食材,再決定今天煮什麼菜,而不是先決定要做佛跳牆再去張羅食材。
-
「模型上線就算完成了」 — 上線只是開始,不是結束。真實世界的資料分布會隨時間改變(例如消費者行為在疫情前後完全不同),模型如果不持續監控和更新,效果會逐漸衰退。最佳實務是設定效能指標(KPI),定期檢視模型表現,當準確率低於門檻值時自動觸發重新訓練。
小練習
-
三要素診斷:回想你工作中一個曾經失敗(或效果不如預期)的專案(不一定是 AI 專案)。用「資料、模型/方法、流程」的框架分析,這個專案最弱的環節是哪一個?如果當時加強那個環節,結果可能會不同嗎?
-
優先順序排列:假設你有一筆 100 萬的 AI 專案預算,你會怎麼分配在這三個面向上?資料整理與標記佔多少?模型開發與訓練佔多少?流程設計與上線後監控佔多少?請寫下你的分配比例和理由。提示:業界的經驗法則是,資料相關工作通常佔整個 AI 專案 60-80% 的時間和成本。