M01.06|AI 風險地圖:準確性、偏誤、資安、隱私、合規
AI 出錯不可怕,可怕的是你不知道它會在哪裡出錯
本講學習重點
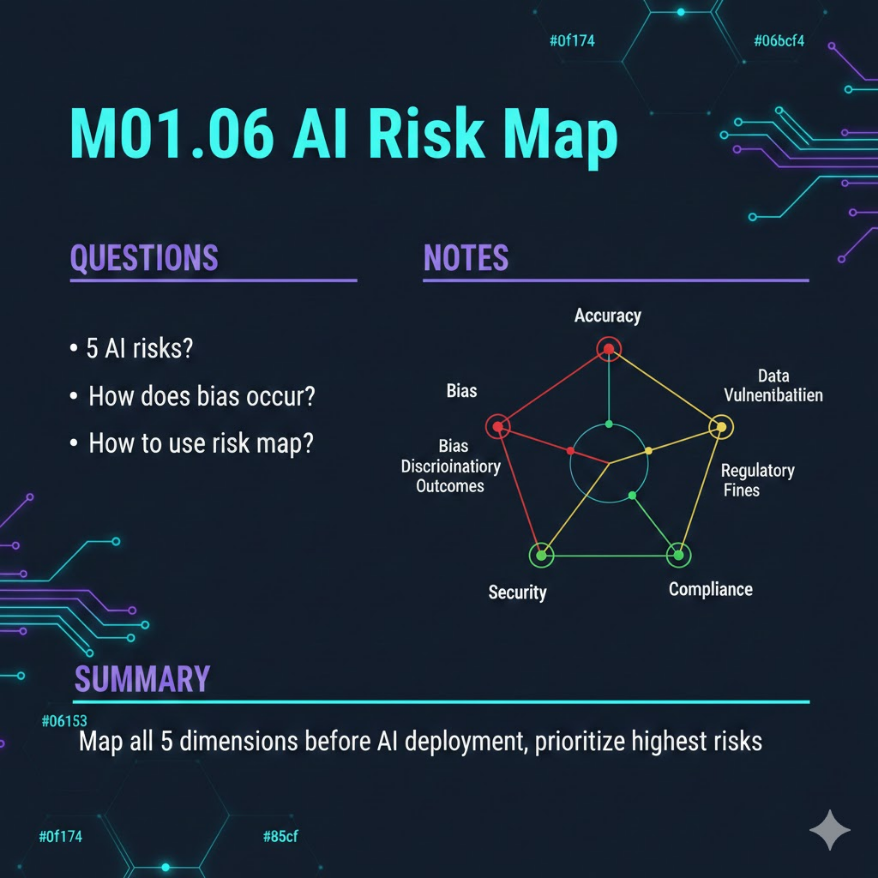
準確性、偏誤、資安、隱私、合規五個維度
訓練資料中的歷史偏見被模型學習並放大
逐一標出高/中/低等級,優先處理最高風險
GDPR可解釋性、個資法、金管會AI指引
🎙️ Podcast(中文)
一句話搞懂
AI 的風險不只是「算錯」,而是涵蓋準確性、偏誤、資安、隱私、合規五個維度,你必須像看地圖一樣,事先標出每個風險的位置和嚴重程度。
白話解說
想像你要開車從台北到高雄,上路前你會打開 Google Maps 看哪裡塞車、哪裡有事故、哪裡在施工。AI 的「風險地圖」就是同樣的概念 — 在導入 AI 之前,你要先掃過五大風險區域,知道哪裡可能出問題。
準確性風險是最直觀的:模型可能算錯。更危險的是「幻覺」(hallucination) — AI 信心滿滿地給你一個完全錯誤的答案。例如 ChatGPT 曾經編造不存在的法律判例,如果律師沒查證就拿去用,後果不堪設想。重點是:AI 的信心程度跟答案的正確性之間,不一定有關聯。
偏誤風險來自訓練資料。如果一家公司用過去十年的履歷篩選資料來訓練 AI,而過去錄取的多數是男性工程師,那 AI 就會學到「男性 = 好候選人」的偏見。亞馬遜曾發生過這個案例,最後被迫放棄整個系統。台灣的銀行如果用歷史核貸資料來訓練 AI,也可能對特定族群、特定郵遞區號產生不公平的歧視。
資安風險包括對抗攻擊 (adversarial attack)、提示注入 (prompt injection)、資料投毒 (data poisoning)。有人在路標上貼小貼紙,就能讓自駕車把「停」誤判為「限速 80」。提示注入更常見 — 用戶在輸入中夾帶指令,騙 AI 繞過限制吐出機密資料。
隱私風險是台灣企業最容易忽略的。當你把客戶資料餵給 AI 模型訓練,即使匿名處理過,也可能透過交叉比對被「重新識別」(re-identification)。2023 年三星員工把公司原始碼貼到 ChatGPT 的事件,就是血淋淋的教訓。
合規風險則是法規面:歐盟 GDPR 要求 AI 決策的可解釋性,台灣《個人資料保護法》對個資蒐集有明確規範,金融業還有金管會的 AI 使用指引。不合規的代價可能是天價罰款加上商譽損失。
應用場景
場景一:銀行信用評分 AI 一家台灣的銀行想用 AI 做信用評分。風險地圖檢查:準確性 — 模型如果誤判,可能拒絕好客戶或放款給壞客戶;偏誤 — 對特定職業、地區可能有歧視;隱私 — 處理大量個人財務資料;合規 — 金管會要求決策可解釋、不能「黑箱拒貸」。這個案例幾乎踩中所有五個風險維度,必須逐一設計防護措施。
場景二:工廠品質檢測 AI 一家半導體封測廠用 AI 做晶片外觀瑕疵檢測。準確性風險最高(漏檢一顆就是重大品質事故),偏誤風險較低(圖像資料較客觀),隱私風險幾乎沒有(不涉及個人資料),合規風險中等(需符合 ISO 品質標準)。這種案例的風險分布就跟銀行完全不同。
常見誤區
-
「我們用的是大公司的 API,應該沒有風險」 — API 供應商保證的是系統可用性,不是你的使用情境沒有偏誤或隱私問題。風險責任在使用者身上,不在供應商。
-
「資料匿名化之後就沒有隱私風險了」 — 研究顯示,只需要郵遞區號、生日、性別三個欄位,就能唯一識別 87% 的美國人。台灣的人口密度更高,重新識別的風險更大。匿名化是必要措施,但不是萬靈丹。
-
「模型準確率 95%,夠好了」 — 要看場景。如果你一天處理 10,000 筆交易,5% 錯誤率代表每天 500 筆出問題。而且那 5% 的錯誤如果集中在某個族群(例如原住民客戶),就同時觸發了偏誤風險。準確率數字要搭配「錯在哪裡」一起看。
小練習
-
繪製風險地圖:選一個你公司正在考慮或已經在用的 AI 應用,對照五大風險維度(準確性、偏誤、資安、隱私、合規),用高 / 中 / 低標出每個維度的風險等級,並寫下你認為最需要優先處理的那一個風險以及原因。
-
幻覺偵測練習:請 ChatGPT 或任何一個 AI 聊天機器人「推薦三本關於台灣 AI 治理的書籍」,然後實際去搜尋這些書是否存在。記錄幻覺發生的比例,體會「AI 信心 ≠ AI 正確」。