M01.07|用例選擇:哪些問題適合用 AI,哪些不適合
不是所有釘子都需要 AI 這把錘子
本講學習重點
資料充足、任務重複、模式明確時最適合
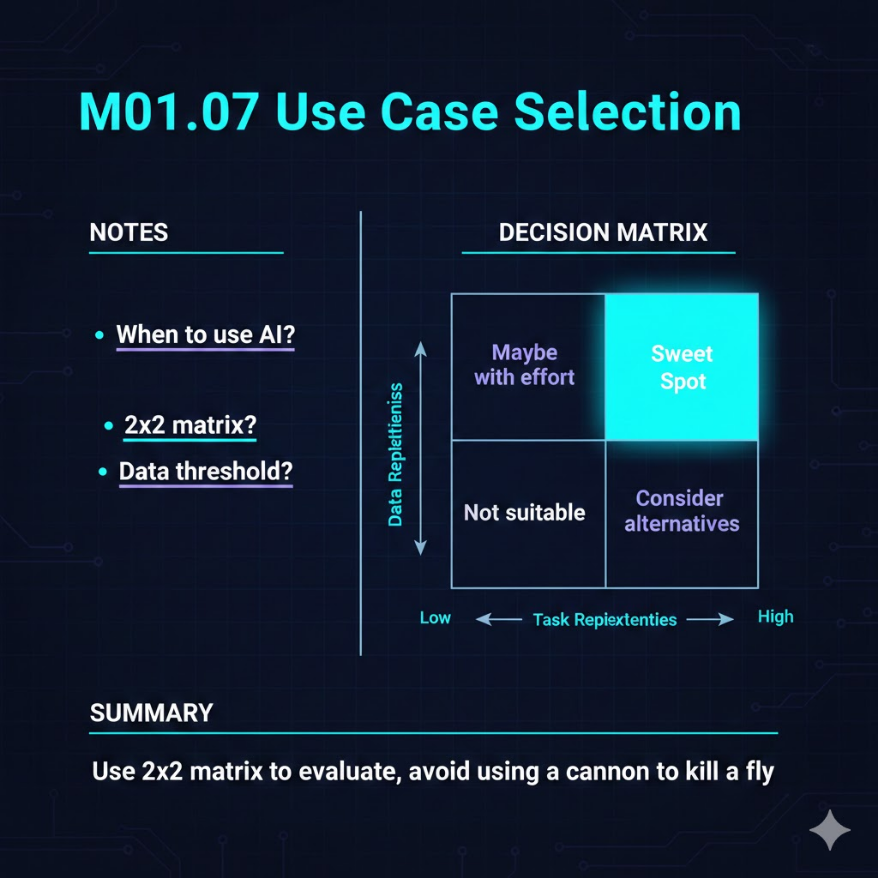
橫軸資料充足度、縱軸任務重複性,右上角是甜蜜點
不只看量,更看品質、標註完整度與一致性
錯誤代價越高,導入難度與成本指數級上升
🎙️ Podcast(中文)
一句話搞懂
AI 最適合「有大量資料可以學習、任務重複且有明確模式」的問題;如果資料少、結果難定義、或者用 Excel 就能解決,硬上 AI 只是浪費錢。
白話解說
你家廚房水龍頭漏水,你會叫水電師傅來修,不會叫建築師來重新設計整棟房子。同樣的道理,很多工作場景其實用 Excel 公式、簡單規則引擎、甚至一個 Google 表單就能搞定,不需要動用 AI 這把重型武器。
判斷一個問題適不適合用 AI,可以用一個簡單的 2x2 矩陣來思考,橫軸是「資料是否充足且可取得」,縱軸是「任務是否重複且有規律」。右上角(資料充足 + 高度重複)是 AI 的甜蜜點,例如客服分類、信用卡詐騙偵測、產品推薦。左下角(資料稀少 + 很少發生)是 AI 最不擅長的區域,例如預測黑天鵝事件、判斷一次性的策略決策。
還有一個常被忽略的判斷標準:容錯空間。推薦系統推錯一部電影,用戶頂多翻白眼;但醫療診斷判錯一個癌症,後果完全不同。容錯空間越小,對 AI 準確度的要求越高,導入難度和成本也會指數級上升。最重要的原則是:「能用 AI 不代表應該用 AI」。
應用場景
適合 AI 的三個例子:
-
電商平台的商品推薦:每天數百萬筆瀏覽和購買紀錄,模式明確(買了尿布的人常買濕紙巾),錯誤成本低(推錯頂多不點),而且有持續的回饋數據可以讓模型越來越準。momo、PChome 這類平台,推薦系統的投資報酬率通常很高。
-
製造業的預測性維護:台灣的工具機廠在設備上裝了大量感測器,每秒都在產生溫度、震動、電流數據。這些資料量大、模式明確(壞掉前通常有徵兆),而且預測錯了頂多多檢查一次,但預測對了可以省下數百萬的停機損失。
-
保險公司的理賠文件分類:每天收到上千份理賠申請,要分類成車禍、醫療、財損等類別再派給對應的審核員。這種高重複性的分類任務,AI 的準確度很容易超過人工分類。
不適合 AI 的兩個例子:
-
新創公司的商業模式決策:「我們該 pivot 到哪個市場?」這種問題沒有歷史資料可供學習(因為是全新的情境),結果的好壞要好幾年後才知道,而且涉及大量主觀價值判斷。這時候創辦人的直覺和市場經驗比任何模型都有用。
-
台灣中小企業的年度尾牙抽獎系統:一年用一次、邏輯很簡單(隨機抽取)、用 Excel 的 RANDBETWEEN 函數三分鐘就搞定。有人真的提案要用 AI 做「智慧抽獎」,這就是典型的殺雞用牛刀。
常見誤區
-
「我們有很多資料,所以一定適合 AI」 — 資料多不代表資料品質好。如果你的 CRM 裡面一半的客戶電話是空的、地址格式不統一、業務員隨便填的備註,那再多的資料也訓練不出好模型。資料「充足」不只看量,還要看品質、標註完整度和一致性。
-
「競爭對手在用 AI,我們也要用」 — 這叫 FOMO(害怕錯過),不是決策。對手用 AI 做推薦系統可能很合理,但你的業務模式、資料基礎、技術能力可能完全不同。先評估自己的用例,不要因為別人在做就跟風。
-
「這個任務人做得到,AI 一定也做得到而且更快」 — 人類擅長的許多事情 AI 其實很爛。例如理解言外之意、處理模糊指示、在全新的情境下臨場應變。客服回覆制式問題 AI 很行,但安撫一個情緒崩潰的客戶?目前 AI 還差得遠。
小練習
-
用例評估矩陣:列出你部門目前三個最花時間的日常工作,用以下四個標準打分(1-5 分):(a) 資料充足度、(b) 任務重複性、(c) 模式明確性、(d) 容錯空間大小。四項加總超過 16 分的,可能是好的 AI 候選用例;低於 10 分的,建議先用其他方式解決。
-
反向思考練習:找一個你覺得「這個一定要用 AI」的場景,然後認真想:不用 AI 的話,用規則引擎、Excel 或人工能不能做到 80% 的效果?如果可以,那你要問的下一個問題是:那剩下 20% 的提升,值得投資多少錢和時間?