M04.01|神經網路基礎:從生物神經元到人工神經元
AI 的大腦不是真的腦 — 但運作邏輯有幾分相似
本講學習重點
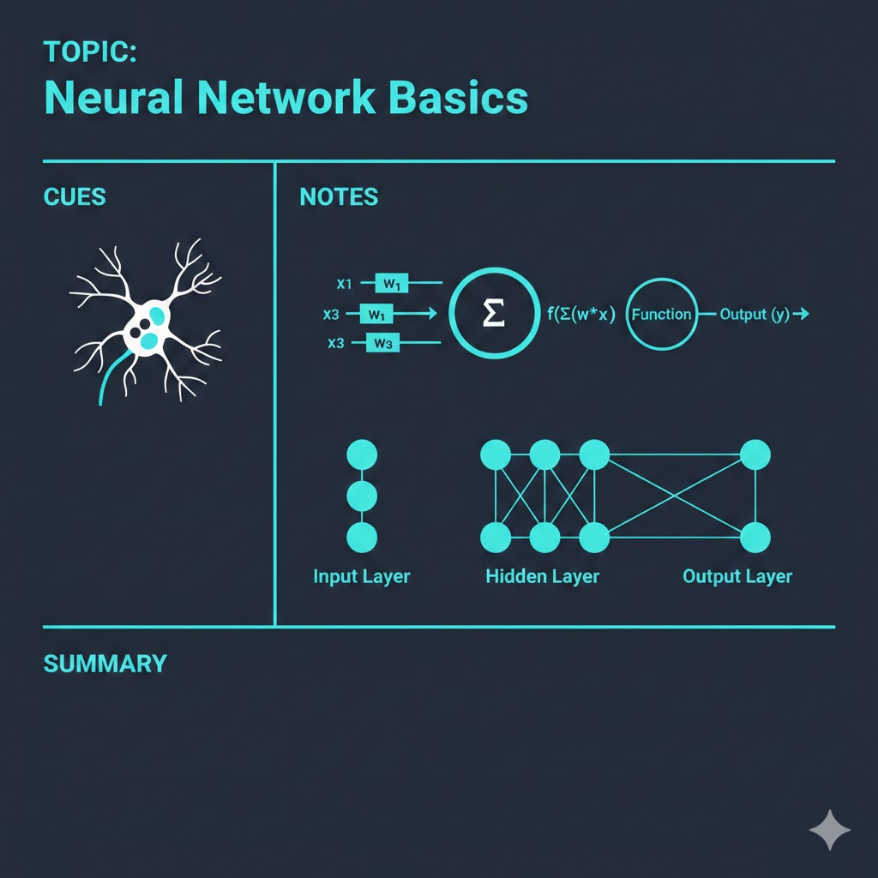
生物神經元的樹突接收訊號、細胞體整合訊號、軸突輸出訊號; 人工神經元的輸入值接收資料、加權求和計算、激活函數決定是否「觸發」輸出。 感知器(Perceptron)是最早的人工神經元模型(1958 年 Rosenblatt): 1. 每個輸入 x_i 乘以對應權重 w_i 2. 加總所有加權輸入並加上偏差值 b 3. 通過激活函數決定輸出 兩種常用激活函數: - Sigmoid:輸出範圍 0~1,適合二元分類的輸出層;缺點是梯度消失問題 - ReLU(Rectified Linear Unit):輸入大於 0 就直接輸出,小於 0 輸出 0; 計算快速,有效緩解梯度消失,現代深度網路主流選擇 神經網路三層結構: - 輸入層(Input Layer):接收原始特徵,不做計算 - 隱藏層(Hidden Layer):提取抽象特徵,層數越多越「深」 - 輸出層(Output Layer):產生最終預測結果 前向傳播(Forward Propagation): 資料從輸入層流向輸出層,每一層對上一層的輸出進行線性變換再通過激活函數。
🎙️ Podcast(中文)
一句話搞懂
神經網路就是把許多「做加法再做判斷」的小單元層層串聯起來——每一層從上一層的輸出提取更抽象的特徵,最終讓電腦從原始資料中自動學出複雜的判斷規則,不需要人工寫規則。
白話解說
從生物到機器:神經元的類比
大腦裡有大約 860 億個神經元,每個神經元透過樹突(Dendrites)接收來自其他神經元的訊號,在細胞體(Cell Body)整合這些訊號,一旦整合後的訊號強度超過「觸發閾值」,就沿著軸突(Axon)把訊號傳給下一個神經元。這個「收訊號、整合、決定要不要觸發」的機制,是整個大腦處理資訊的基礎。
1943 年,神經科學家 McCulloch 和數學家 Pitts 提出了一個問題:能不能用數學公式模仿神經元的行為?他們建立了第一個數學版本的神經元模型,奠定了人工神經網路的理論基礎。
對應關係如下:
| 生物神經元 | 人工神經元 | 功能 |
|---|---|---|
| 樹突(Dendrites) | 輸入值(x₁, x₂, …, xₙ) | 接收外部訊號 |
| 突觸強度(Synapse Strength) | 權重(w₁, w₂, …, wₙ) | 決定每個訊號的重要程度 |
| 細胞體(Cell Body) | 加權求和(Σ wᵢxᵢ + b) | 整合所有輸入訊號 |
| 觸發閾值(Threshold) | 激活函數(Activation Function) | 決定是否「觸發」並輸出 |
| 軸突(Axon) | 輸出值(Output) | 把結果傳給下一層 |
這個類比不是說電腦在「模擬大腦」,而是數學上借用了類似的計算結構——實際的人工神經元遠比生物神經元簡單得多。
感知器:最簡單的人工神經元
1958 年,心理學家 Frank Rosenblatt 提出了感知器(Perceptron),這是第一個可以「學習」的人工神經元模型。感知器的計算過程只有三步:
第一步:加權求和
把所有輸入值 x₁, x₂, …, xₙ 分別乘以對應的權重 w₁, w₂, …, wₙ,再加上一個偏差值(Bias)b:
z = w₁x₁ + w₂x₂ + ... + wₙxₙ + b
= Σ(wᵢxᵢ) + b
權重 w 代表每個輸入特徵的「重要程度」——正的大權重表示這個特徵強烈支持輸出;負的大權重表示強烈反對;接近零的權重表示這個特徵幾乎不影響結果。偏差值 b 讓整個函數可以左右平移,增加靈活性。
第二步:激活函數
把加權求和的結果 z 丟進激活函數,決定輸出值:
output = f(z)
第三步:輸出結果
輸出值再傳到下一個神經元或作為最終預測。
用一個具體例子理解:假設你要預測一封郵件是否為垃圾郵件,輸入特徵是:
- x₁ = 郵件包含「免費」這個詞(1=是,0=否)
- x₂ = 郵件包含外部連結數量
- x₃ = 寄件人在聯絡人清單(1=是,0=否)
z = 2.5 × x₁ + 0.8 × x₂ + (-3.0) × x₃ + (-0.5)
若 x₁=1(含「免費」)、x₂=3(三個連結)、x₃=0(不在聯絡人清單):
z = 2.5×1 + 0.8×3 + (-3.0)×0 + (-0.5)
= 2.5 + 2.4 + 0 - 0.5 = 4.4
z = 4.4 是個正數且很大,代表「高度可疑是垃圾郵件」。激活函數會把這個數字轉換成最終的分類結果。
激活函數:神經元的「觸發機制」
激活函數的作用是在線性計算(加權求和)之後,引入非線性——沒有非線性,不管堆多少層神經元,整個網路的計算能力都等價於一個線性模型,無法學習複雜的模式。激活函數讓神經網路能夠逼近任意複雜的函數。
Sigmoid 函數
\[\sigma(z) = \frac{1}{1 + e^{-z}}\]Sigmoid 把任意實數壓縮到 (0, 1) 之間:
z = -10 → σ(z) ≈ 0.00005(幾乎是 0)
z = 0 → σ(z) = 0.5
z = 10 → σ(z) ≈ 0.99995(幾乎是 1)
優點:輸出可以直接解釋為「機率」,適合作為二元分類的輸出層激活函數。
缺點(梯度消失問題):當 z 很大或很小時,sigmoid 曲線接近水平,導數幾乎為零。在深度網路(多層)中,反向傳播要把梯度從輸出層往輸入層乘回去,每乘一次接近零的數字,梯度就變得更小,傳到前面幾層時梯度已微乎其微,前面的層根本學不到任何東西。這個問題在深層網路中致命,是 sigmoid 在隱藏層被淘汰的主因。
ReLU(Rectified Linear Unit)
\[\text{ReLU}(z) = \max(0, z)\]ReLU 的規則極其簡單:輸入若大於 0 就直接輸出;輸入若小於等於 0 就輸出 0。
z = -5 → ReLU = 0
z = 0 → ReLU = 0
z = 3.7 → ReLU = 3.7
z = 100 → ReLU = 100
優點:
- 計算極快(只是一個比較運算)
- 當 z > 0 時,梯度恆為 1,不存在梯度消失問題
- 稀疏激活(許多神經元輸出為 0),增加網路表達效率
缺點(死亡 ReLU 問題):若某個神經元長期輸入負值,它的輸出永遠是 0,梯度也是 0,這個神經元就「死掉了」永遠學不到東西。實務上可用 Leaky ReLU(負數區域給一個很小的斜率)或 ELU 緩解。
現況:ReLU 及其變種(Leaky ReLU、ELU、GELU)是現代深度學習隱藏層的主流選擇。
| 激活函數 | 輸出範圍 | 主要用途 | 現狀 |
|---|---|---|---|
| Sigmoid | (0, 1) | 二元分類輸出層 | 隱藏層已被取代 |
| Tanh | (-1, 1) | RNN 閘門 | 部分場景仍用 |
| ReLU | [0, +∞) | 深度網路隱藏層 | 主流 |
| Leaky ReLU | (-∞, +∞) | 解決死亡 ReLU | 常見替代方案 |
| Softmax | (0,1),加總=1 | 多分類輸出層 | 標準配備 |
神經網路的三層結構
單一個感知器能力有限。把許多感知器串聯、並聯,排列成「層(Layer)」,就形成了神經網路。標準的神經網路由三種層組成:
輸入層(Input Layer)
接收原始資料的特徵值。輸入層的神經元數量等於特徵數量——如果你的資料有 10 個特徵,輸入層就有 10 個神經元。輸入層本身不做任何計算,只是把原始數值傳給第一個隱藏層。
隱藏層(Hidden Layer)
藏在輸入層和輸出層之間的所有層,統稱隱藏層。每一層從前一層的輸出中提取更抽象的特徵:
輸入層 → 第一隱藏層:學習低階特徵(邊緣、顏色梯度)
→ 第二隱藏層:組合出中階特徵(眼睛形狀、鼻子輪廓)
→ 第三隱藏層:組合出高階特徵(人臉結構)
→ 輸出層:根據高階特徵做最終判斷
「深度」學習(Deep Learning)的「深」就是指有多個隱藏層。層數越多,網路能學習的特徵抽象程度越高,但計算量也越大、訓練難度也越高。
每個隱藏層的神經元數量(稱為「寬度」)是超參數,需要根據問題複雜度調整——太少學不到足夠的特徵,太多容易過擬合且浪費計算資源。
輸出層(Output Layer)
產生最終預測結果。輸出層的神經元數量取決於任務類型:
| 任務類型 | 輸出層神經元數 | 激活函數 | 輸出解釋 |
|---|---|---|---|
| 二元分類 | 1 | Sigmoid | 0~1 之間的機率值 |
| 多分類(N 類) | N | Softmax | N 個機率值,加總為 1 |
| 迴歸(預測數值) | 1 | 無(線性) | 直接輸出預測數值 |
前向傳播:資料如何流過網路
前向傳播(Forward Propagation)是神經網路進行預測的過程——資料從輸入層進入,一層一層地向右流動,最終從輸出層輸出預測值。
以一個簡化的兩層網路(一個隱藏層)為例:
輸入特徵:x = [x₁, x₂]
隱藏層:3 個神經元,ReLU 激活
輸出層:1 個神經元,Sigmoid 激活(二元分類)
計算步驟:
步驟一:輸入層 → 隱藏層
隱藏層神經元 h₁:z₁ = w₁₁x₁ + w₁₂x₂ + b₁
a₁ = ReLU(z₁)
隱藏層神經元 h₂:z₂ = w₂₁x₁ + w₂₂x₂ + b₂
a₂ = ReLU(z₂)
隱藏層神經元 h₃:z₃ = w₃₁x₁ + w₃₂x₂ + b₃
a₃ = ReLU(z₃)
步驟二:隱藏層 → 輸出層
輸出神經元: z_out = v₁a₁ + v₂a₂ + v₃a₃ + b_out
ŷ = Sigmoid(z_out) ← 最終預測機率
前向傳播是純粹的「計算」過程——把輸入資料代進去,一路乘以權重、通過激活函數,最後得到預測值。這個過程本身不涉及學習;學習(調整權重)是透過反向傳播(Backpropagation)完成的,那是下一個主題。
應用場景
台灣健保的慢性病風險預測
台灣健保資料庫是全球最完整的醫療資料庫之一,涵蓋超過 2,300 萬人的就醫紀錄。衛福部國健署與多個學研機構合作,利用神經網路分析多種慢性病(糖尿病、高血壓、腎臟病)的早期風險因子。
在「糖尿病前期篩查」專案中,研究團隊建立了一個三層神經網路:
- 輸入層(24 個神經元):年齡、BMI、空腹血糖、血壓、膽固醇、三酸甘油酯、家族史等 24 個特徵
- 隱藏層一(64 個神經元,ReLU):從基礎生化指標中提取代謝症候群相關模式
- 隱藏層二(32 個神經元,ReLU):組合出更高階的風險因子組合
- 輸出層(1 個神經元,Sigmoid):輸出 5 年內發展為糖尿病的機率
與傳統的邏輯回歸模型相比,神經網路在同樣的特徵集上將 AUC-ROC 從 0.76 提升至 0.84,尤其在捕捉多個風險因子交互作用(例如「高 BMI + 高血糖 + 家族史同時存在」的非線性疊加效應)方面表現顯著更好。這種非線性特徵組合能力,正是隱藏層激活函數帶來的核心優勢。
常見誤區
誤區一:神經網路的「神經元」和大腦的神經元是一樣的東西
許多人看到「神經元」這個名稱,以為 AI 真的在模擬生物大腦。實際上,人工神經元只是一個數學函數:做加法(加權求和)再做一個非線性轉換(激活函數)。生物神經元是複雜的電化學系統,涉及離子通道、神經傳導物質、樹突整合等數十種機制,比人工神經元複雜幾個數量級。兩者的相似性是「計算流程的類比」,而非「生物機制的模仿」。把人工神經網路說成「AI 有大腦」是嚴重的誤導。
誤區二:隱藏層越多,神經網路一定越好
層數增加確實能提升網路的表達能力,但並不代表「越深越好」。在資料量不夠的情況下,層數太多會嚴重過擬合——網路把訓練資料的雜訊也記住了,對新資料的泛化能力反而更差。此外,層數太深會帶來梯度消失或梯度爆炸問題(在 ResNet 引入殘差連接之前,超過 20 層的網路幾乎無法有效訓練)。選擇層數要根據資料量、任務複雜度和計算資源三者權衡,沒有「越深越好」這回事。
誤區三:權重是由人來設定的
初學者常誤以為需要人工指定每個神經元的權重值。事實上,網路啟動時所有權重都是隨機初始化的(通常用 Xavier 或 He 初始化),然後透過反向傳播 + 梯度下降,用訓練資料自動調整權重,使得預測誤差(損失函數值)逐漸降低。人工設計的是網路架構(幾層、每層幾個神經元、用什麼激活函數),而不是具體的權重數值。權重是訓練的產物,不是設計的產物。
小練習
練習一:計算一個神經元的輸出
某個神經元有三個輸入特徵,權重和偏差值如下:
- w₁ = 0.5,w₂ = -1.2,w₃ = 0.8
- 偏差值 b = 0.3
- 激活函數:ReLU
當輸入為 x₁ = 2.0、x₂ = 1.0、x₃ = 3.0 時:
(1) 計算加權求和 z 的值。 (2) 計算 ReLU(z) 的輸出值。 (3) 如果把激活函數改成 Sigmoid,輸出值大約是多少(不需精確計算,判斷範圍即可)?
看解答
**第 (1) 題:加權求和** ``` z = w₁x₁ + w₂x₂ + w₃x₃ + b = 0.5 × 2.0 + (-1.2) × 1.0 + 0.8 × 3.0 + 0.3 = 1.0 + (-1.2) + 2.4 + 0.3 = 2.5 ``` **第 (2) 題:ReLU 激活** ``` ReLU(2.5) = max(0, 2.5) = 2.5 ``` 因為 z = 2.5 > 0,ReLU 直接輸出原值,不做任何變換。 **第 (3) 題:Sigmoid 激活** z = 2.5 是一個正數,且數值不算小。 Sigmoid(0) = 0.5,Sigmoid(2) ≈ 0.88,Sigmoid(3) ≈ 0.95。 因此 Sigmoid(2.5) ≈ 0.92,輸出值接近 1,表示這個神經元「強烈激活」,輸出的機率值約為 92%。 **關鍵直覺**: - ReLU 的輸出是原始數值(不壓縮),適合隱藏層傳遞特徵強度 - Sigmoid 的輸出是 0~1 的機率值,適合最後輸出層表達「是/否」的置信度練習二:設計神經網路架構
以下是三個不同的預測任務,請為每個任務設計輸出層的神經元數量和激活函數:
任務 A:判斷一張 X 光片是否有肺結節(只需回答「有」或「沒有」)。
任務 B:對一篇新聞文章進行分類,共有「政治」、「財經」、「運動」、「娛樂」、「科技」五個類別。
任務 C:預測台北市未來 24 小時的平均溫度(攝氏度,連續數值)。