M04.02|深度學習 vs 傳統機器學習:什麼時候該用深度學習
深度學習不是萬能鑰匙 — 資料少、要解釋的場景,傳統 ML 可能更好
本講學習重點
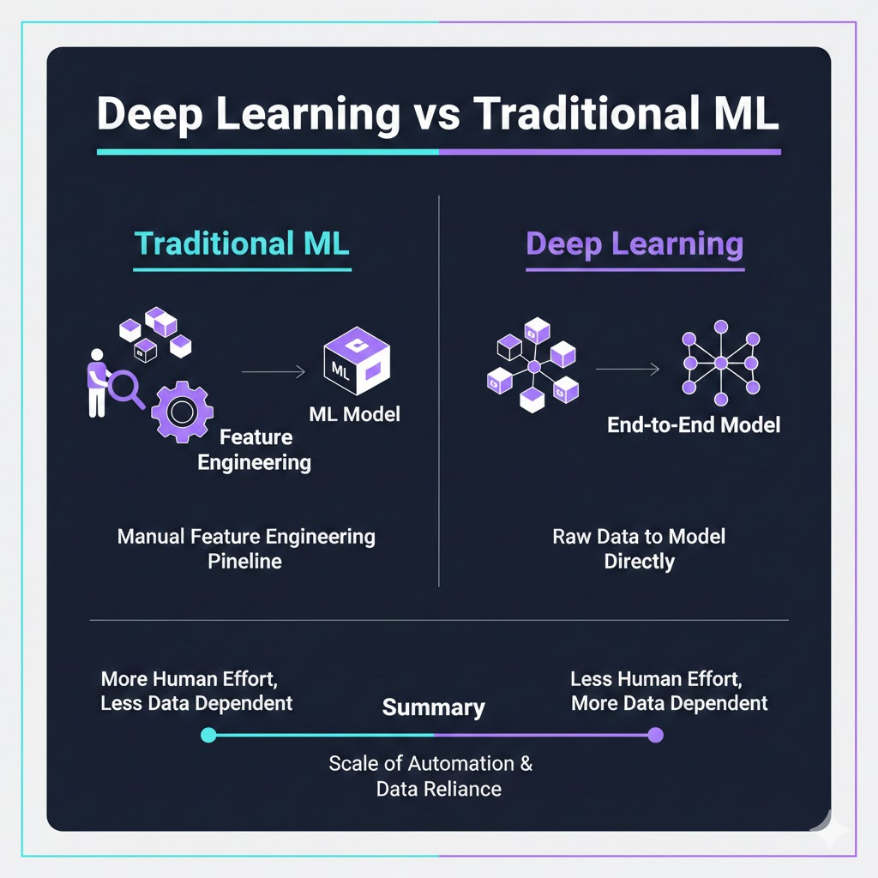
最大差異:特徵提取方式 - 傳統 ML:需要人工特徵工程(Feature Engineering),由領域專家手動設計輸入特徵 - 深度學習:自動特徵提取(Automatic Feature Extraction),從原始資料中自己學習哪些特徵重要 資料需求差距顯著: - 傳統 ML:數百到數萬筆即可有效訓練 - 深度學習:通常需要數萬到數百萬筆才能發揮優勢 - 資料少時:深度學習容易過擬合,傳統 ML 更穩健 可解釋性取捨: - 傳統 ML(邏輯回歸、決策樹):每個預測可以追溯到具體規則 - 深度學習:中間層權重難以解釋,是「黑盒」 - 法規合規(金融、醫療)通常要求可解釋性 計算成本: - 深度學習訓練需要 GPU,時間以小時到天計 - 傳統 ML 在 CPU 上即可訓練,時間以秒到分鐘計 - 推論成本:深度學習也較高(但已有模型壓縮技術) 決策指南: 1. 資料量 < 1 萬筆?→ 優先考慮傳統 ML 2. 需要向監管或客戶解釋預測理由?→ 傳統 ML 3. 輸入是非結構化資料(圖片、文字、語音)?→ 深度學習 4. 有 GPU 資源和足夠的訓練時間?→ 才考慮深度學習
🎙️ Podcast(中文)
一句話搞懂
傳統機器學習需要人工設計輸入特徵(特徵工程),深度學習能從原始資料自動學出特徵——但這個優勢是用「需要更多資料、更多算力、更難解釋」換來的;在資料量少或需要可解釋性的場景,傳統機器學習往往是更務實的選擇。
白話解說
最根本的差異:誰來做特徵工程
理解深度學習和傳統機器學習的差異,最關鍵的切入點是「特徵」從哪裡來。
傳統機器學習演算法(邏輯回歸、SVM、隨機森林、XGBoost 等)本身只能處理人類事先定義好的特徵。以辨識貓狗圖片為例,傳統 ML 無法直接吃進一張 224×224 像素的圖片然後輸出答案——你必須先手動設計特徵:「邊緣像素比例」、「特定紋理頻率」、「顏色直方圖分佈」……這個過程叫做特徵工程(Feature Engineering),需要大量的領域知識和人工投入,往往是整個 ML 專案中最耗時、最依賴人類智慧的部分。
深度學習(神經網路)的革命性突破在於:它能自動從原始資料中學習哪些特徵對任務有用。把原始的 224×224 像素圖片直接丟進卷積神經網路,網路會自己在第一層學到「辨識邊緣有用」,在第二層學到「辨識耳朵形狀有用」,在更深層學到「辨識貓臉整體結構有用」。整個特徵提取的流程被整合進訓練過程,人類不需要事先知道哪些特徵重要。
傳統機器學習流程:
原始資料 → [人工特徵工程] → 數值特徵向量 → ML 演算法 → 預測結果
↑
需要領域專家
深度學習流程:
原始資料 ──────────────────────────────────────────→ 預測結果
↑
自動特徵提取(整合在神經網路中)
這個差異在非結構化資料(圖片、語音、文字)上體現得最為明顯。對於結構化資料(表格中整齊的數值欄位),特徵工程的難度相對低,傳統 ML 的劣勢縮小——這也是為什麼在 Kaggle 競賽的表格資料題目上,XGBoost 和 LightGBM 至今仍能與深度學習一爭高下。
資料量:深度學習的飢渴問題
深度學習的自動特徵提取能力是有代價的。一個現代深度學習模型可能有幾百萬個需要學習的參數(權重)——ResNet-50 有 2,500 萬個,GPT-2 有 15 億個。要讓這些參數收斂到有意義的值,需要大量的訓練樣本。
直覺類比:一個要學會辨識數千種物品的學生,如果每種物品只給他看 5 張圖片,他只能死記硬背,遇到角度稍微不同的新圖片就認不出來。給他看 100 萬張,他才能真正歸納出辨識規律。深度學習模型就是這樣的「需要大量例子才能歸納」的學習者。
不同資料量對兩類方法的影響:
| 訓練資料量 | 傳統 ML 表現 | 深度學習表現 | 建議 |
|---|---|---|---|
| < 1,000 筆 | 良好(參數少,不易過擬合) | 差(嚴重過擬合) | 傳統 ML |
| 1,000 ~ 10,000 筆 | 良好 | 尚可(需要正則化技術) | 傳統 ML 為主 |
| 10,000 ~ 100,000 筆 | 趨於飽和(難以進一步提升) | 開始展現優勢 | 視任務而定 |
| > 100,000 筆 | 效能瓶頸明顯 | 顯著優於傳統 ML | 深度學習 |
| > 1,000,000 筆 | 遠遠落後 | 持續提升,上限高 | 深度學習 |
資料不足時的解決方案:深度學習提出了遷移學習(Transfer Learning)來緩解資料飢渴問題——用在大型資料集(如 ImageNet 的 120 萬張圖片)上預訓練好的模型,再用少量的目標資料進行微調(Fine-tuning)。這讓原本需要幾十萬張標記圖片的分類任務,用幾千張就能達到不錯的效果。但即便如此,傳統 ML 在極小資料集(< 1,000 筆)上的穩健性仍然難以撼動。
可解釋性:黑盒的代價
「這個 AI 為什麼做出這個決定?」——這個問題在許多真實應用場景中至關重要,但深度學習對此的回答令人沮喪。
一個 ResNet 影像辨識模型有 2,500 萬個權重,每次預測是這 2,500 萬個數字共同作用的結果,沒有人能直接「閱讀」這些權重理解模型的判斷邏輯。這就是所謂的黑盒(Black Box)問題。
相比之下,傳統 ML 的許多模型本身就是可解釋的:
- 邏輯回歸:每個特徵的係數直接告訴你「這個因素增加一個單位,預測機率增加多少」
- 決策樹:整棵樹的分支邏輯可以用 if-else 語言完整描述,人類可以逐步追蹤任何一個預測的決策路徑
- 線性 SVM:哪些特徵讓樣本更靠近決策邊界的哪一側,是可以直觀理解的
可解釋性在台灣以下場景有法規或業務上的強制要求:
| 場景 | 法規 / 要求 | 影響 |
|---|---|---|
| 銀行信貸審核 | 金管會規定拒絕申貸需提供理由 | 不可用純黑盒模型 |
| 醫療 AI 輔助診斷 | 醫師須對診斷結果負責,需理解 AI 依據 | 需可解釋性工具輔助 |
| 政府補貼資格審查 | 行政程序法要求行政決定需有理由 | 傳統規則或可解釋 ML |
| 保險核保 | 保險業監理機制要求公平合理 | 模型偏差需可追溯 |
值得注意的是,可解釋性研究(XAI, Explainable AI)正在縮小這個差距,SHAP 和 LIME 等技術可以為深度學習的個別預測生成近似解釋。但這些解釋是事後近似,不是模型本身固有的可解釋性,在高風險決策場景中有其侷限性。
計算成本:訓練深度學習的真實代價
深度學習的計算需求遠超傳統 ML,這個差距在實際部署時往往超乎預期:
訓練成本
| 比較項目 | 傳統 ML(如 XGBoost) | 深度學習(如 ResNet-50) |
|---|---|---|
| 訓練硬體 | 普通 CPU 即可 | 通常需要 GPU(甚至多 GPU) |
| 訓練時間 | 秒到分鐘 | 小時到天 |
| 記憶體需求 | 數 GB RAM | 數 GB 顯示卡記憶體(VRAM) |
| 電費成本 | 幾乎可忽略 | 在台灣用 RTX 3090 訓練一天約 20~40 元 |
| 雲端成本 | 幾美元 | 幾十到幾千美元(視模型大小) |
推論(部署後使用)成本
傳統 ML 模型訓練好之後,推論幾乎不需要計算資源——一個邏輯回歸模型在 CPU 上每秒可以處理幾萬筆請求,記憶體佔用不到 1 MB。深度學習模型的推論計算量依然很大,大型模型若要達到低延遲,通常還是需要 GPU,硬體成本持續發生。
模型壓縮技術(量化、剪枝、知識蒸餾)可以縮小這個差距,但都伴隨一定程度的準確率損失。
決策指南:什麼時候選哪個
根據以上四個維度,整理出一個實用的決策框架:
問題一:你的輸入資料是什麼類型?
非結構化資料(圖片、語音、原始文字)→ 優先考慮深度學習
結構化資料(數值、類別欄位的表格)→ 傳統 ML 通常更快更穩
問題二:你有多少標記訓練資料?
< 10,000 筆 → 傳統 ML(或深度學習 + 遷移學習)
10,000 ~ 100,000 筆 → 看任務類型決定
> 100,000 筆 → 深度學習開始展現優勢
問題三:你的應用場景需要解釋決策理由嗎?
需要(金融法規、醫療、法律)→ 傳統 ML 或可解釋深度學習
不需要(純預測效能)→ 深度學習可能更好
問題四:你有 GPU 資源和充裕的開發時間嗎?
是 → 可以嘗試深度學習
否 → 傳統 ML 是務實選擇(幾分鐘就能跑出基線模型)
簡易決策樹:
是非結構化資料?
├── 是 → 資料量足夠(> 1萬筆)?
│ ├── 是 → 深度學習(CNN/Transformer)
│ └── 否 → 深度學習 + 遷移學習,或重新蒐集資料
└── 否(結構化資料)
├── 需要可解釋性? → 邏輯回歸、決策樹
└── 不需要可解釋性?
├── 資料 < 1萬筆 → XGBoost / 隨機森林
└── 資料 > 10萬筆 → XGBoost 先試,視情況再試深度學習
應用場景
台灣金融業的兩個對照案例
以下是台灣金融業中,一個適合深度學習、一個適合傳統 ML 的真實業務對照:
| 比較維度 | 案例 A:信用卡交易詐騙偵測 | 案例 B:信貸核准審查 |
|---|---|---|
| 資料類型 | 結構化(金額、地點、商家類別、時間等數值欄位) | 結構化(收入、負債比、就業年資、財務比率) |
| 資料量 | 每月數千萬筆交易 | 每年數十萬筆申請 |
| 可解釋性需求 | 低(系統自動判斷即可,後台人工複核高風險) | 極高(金管會規定拒貸需說明具體理由) |
| 速度需求 | 極高(每筆交易 100 毫秒內判斷) | 中等(72 小時內完成審核) |
| 推薦方法 | LightGBM / XGBoost(不是深度學習) | 邏輯回歸 + 決策樹(傳統 ML) |
| 理由 | 結構化資料,XGBoost 表現已接近深度學習上限;推論速度快;可解釋性非硬性要求 | 法規要求可解釋;資料量雖足夠,但「說得出理由」比微幅提升準確率更重要 |
反直覺的重點:信用卡詐騙偵測每天處理數千萬筆交易,資料量遠超深度學習的最低需求——但業界主流工具依然是 XGBoost/LightGBM,而不是深度學習。原因在於:結構化資料 + 速度要求 + 已夠好的準確率,使得深度學習帶來的邊際效益遠小於它帶來的系統複雜度和計算成本。
相比之下,若同一家銀行要做「客服語音分析」(從通話錄音中識別客戶情緒和問題類型),就應該毫不猶豫地選擇深度學習(如 Wav2Vec + Transformer),因為語音是非結構化資料,傳統 ML 根本無法有效處理。
常見誤區
誤區一:深度學習效果一定比傳統 ML 好,應該直接用深度學習
許多人把「深度學習」等同於「更先進、效果更好」,認為無論什麼問題都應該優先用深度學習。這是一個成本高昂的誤解。在結構化資料(表格型資料)場景,XGBoost 和 LightGBM 在業界競賽和生產環境中的表現,至今仍與甚至優於許多深度學習方案。更重要的是,傳統 ML 的開發週期更短、所需資料更少、可解釋性更好——在業務時程緊迫或資料稀缺的情況下,傳統 ML 跑出的「80% 效果」可能遠比深度學習耗時三個月才跑出的「85% 效果」更有商業價值。工具的選擇永遠服務於業務目標,而不是技術本身的「炫酷程度」。
誤區二:深度學習只要資料夠多就一定能學好
「只要餵夠多資料,深度學習就能解決一切」是另一個常見神話。資料量是必要條件但非充分條件。資料的品質、標記的準確性、資料是否覆蓋模型需要面對的真實場景分布,這些因素和資料量同樣重要甚至更重要。另外,即使有足夠的資料,如果網路架構選擇不當、超參數設定不對、訓練技巧不足,深度學習模型依然可能遠低於預期。深度學習有更多「需要調校的旋鈕」,在缺乏深度學習工程能力的團隊中,傳統 ML 更容易達到穩健的結果。
誤區三:傳統 ML 是過時的技術,遲早會被深度學習完全取代
從技術演進來看,這個推論看似合理,但在實際工業界和 2026 年的今天並不成立。在金融、製造、零售等行業的大量日常 AI 應用(信用評分、需求預測、庫存優化、客戶流失預測)中,XGBoost、隨機森林、邏輯回歸依然是生產環境中使用最廣泛的工具。這不是因為工程師「不懂深度學習」,而是因為這些工具在有限資料、低計算資源、需要可解釋性的大量真實業務場景中,提供了最佳的效益比。深度學習和傳統 ML 是互補關係,不是取代關係。
小練習
練習一:分析四個業務場景,選擇適合的方法
以下是台灣四家不同產業的 AI 需求,請為每個場景選擇「深度學習」或「傳統機器學習」,並說明最關鍵的理由:
場景 A:台灣某醫院要開發一套系統,從胸腔 X 光片中自動偵測是否有肺炎陰影,輔助影像科醫師進行初步篩查。醫院已累積 50,000 張有標記的 X 光片。
場景 B:台灣某保險公司要建立客戶流失預測模型,資料為會員系統中的結構化資料(投保品項、繳費記錄、客服互動次數等),共 8,000 筆有標記的歷史資料(流失/未流失)。
場景 C:台灣某電商平台要從用戶的商品評論文字中自動分析情感傾向(正面/中性/負面),每天有 10 萬筆新評論需要處理,累積標記資料已達 200 萬筆。
場景 D:台灣某中小型製造商要預測明天各產品的出貨需求,以優化備料計劃。歷史資料為 3 年的每日銷售紀錄(產品 SKU、日期、節慶標記、促銷活動、出貨量),共 1,095 筆(每天一筆,多個 SKU 加總約 5,000 筆)。
看解答
**場景 A:X 光片肺炎偵測 → 深度學習(CNN)** - 資料類型:非結構化(圖片),傳統 ML 無法直接處理像素 - 資料量:50,000 張雖然不算多,但可用在 ImageNet 上預訓練的 ResNet 或 DenseNet 做遷移學習,幾千張就能微調出不錯的效果 - 可解釋性:可用 Grad-CAM 技術生成熱圖,標示模型關注的肺部區域,幫助醫師理解依據 - **選深度學習**,且優先使用遷移學習降低資料需求 **場景 B:保險客戶流失預測 → 傳統機器學習(XGBoost 或隨機森林)** - 資料類型:結構化(表格型),傳統 ML 的優勢場景 - 資料量:8,000 筆對深度學習而言偏少,容易過擬合;對 XGBoost 而言已足夠訓練出穩健的模型 - 可解釋性:保險業監理機關可能要求說明流失預測依據,XGBoost 搭配 SHAP 可以解釋每個客戶的風險因素 - **選傳統 ML**,且可考慮搭配 SMOTE 處理正負樣本不平衡問題 **場景 C:電商評論情感分析 → 深度學習(BERT 類 Transformer)** - 資料類型:非結構化(文字),深度學習的優勢場景 - 資料量:200 萬筆標記資料非常充裕,深度學習可以充分發揮 - 語言:繁體中文,傳統 ML 的特徵工程(TF-IDF 等)難以捕捉詞義和上下文;BERT 類模型在中文情感分析上準確率遠高於傳統方法 - **選深度學習(BERT-base-chinese 微調)**,可充分利用豐富的標記資料 **場景 D:製造業需求預測 → 傳統機器學習(XGBoost 或 LightGBM + 時序特徵工程)** - 資料類型:結構化(時序型表格資料) - 資料量:5,000 筆(按 SKU 算)整體偏少,深度學習容易過擬合 - 特殊性:時序資料有規律可言(星期幾效應、節慶效應、促銷週期),人工特徵工程(lag 特徵、移動平均、節慶標記)能有效捕捉這些規律 - 深度學習時序模型(LSTM、Temporal Fusion Transformer)需要更多資料才能發揮優勢 - **選傳統 ML + 時序特徵工程**,快速迭代且結果容易解釋練習二:深度學習 vs 傳統 ML 的取捨分析
某台灣新創公司的 AI 工程師小玲,正在評估兩個模型方案:
方案一(XGBoost):
- 訓練時間:15 分鐘(CPU)
- 開發週期:2 週
- AUC-ROC:0.87
- 可解釋性:高(SHAP 可解釋每個預測)
- 月推論成本:約 500 元(雲端 CPU 實例)
方案二(深度學習,MLP):
- 訓練時間:3 小時(GPU)
- 開發週期:6 週
- AUC-ROC:0.89
- 可解釋性:低(黑盒)
- 月推論成本:約 3,000 元(需要 GPU 實例)
任務背景:預測電商平台使用者是否會在 7 天內完成首次購物(結構化行為資料,50,000 筆訓練資料)。業務方希望盡快上線,且行銷部門想要了解「哪些因素最能預測購買」以制定策略。
請問:小玲應該選哪個方案?請從業務需求和技術條件兩個角度分析。