M04.04|RNN 與序列模型:讓 AI 理解時間順序
RNN 有記憶 — 它知道前面發生了什麼,才能預測接下來會發生什麼
本講學習重點
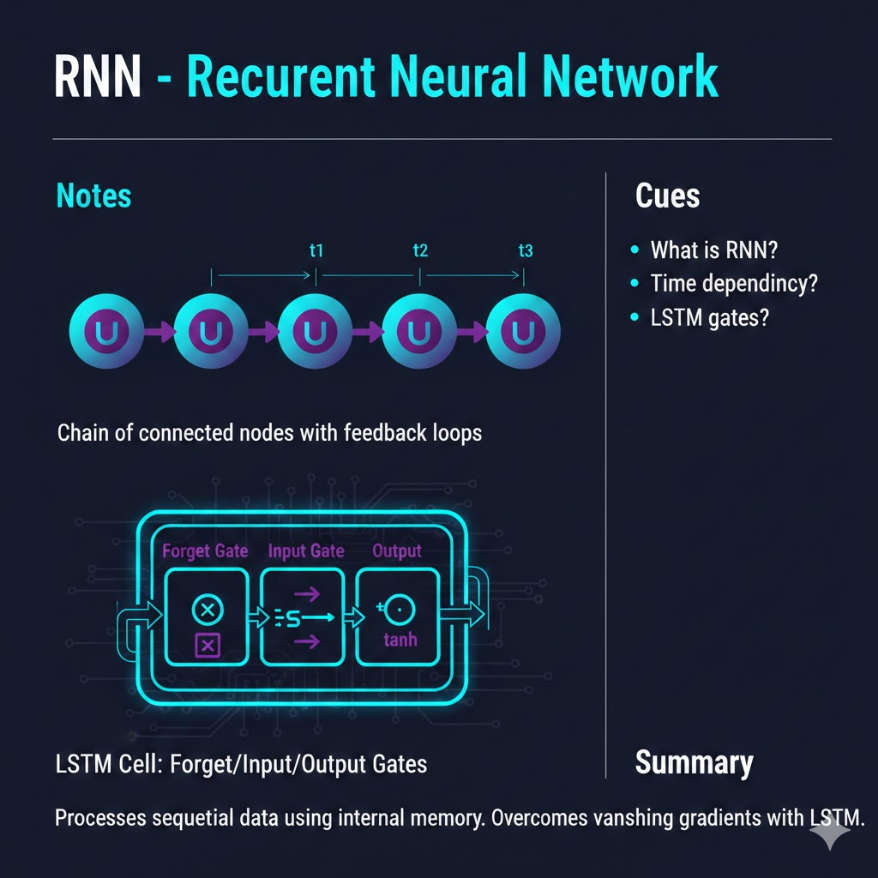
序列資料的特性:資料點之間有時間或位置上的相依關係,順序本身就是重要資訊。 一般 MLP/CNN 固定輸入維度,無法處理可變長度的序列,也沒有「記憶」。 RNN 核心機制: - 每個時間步(time step)接受當前輸入 x_t 和前一步的 hidden state h_{t-1} - 輸出新的 hidden state h_t,傳遞給下一個時間步 - hidden state 是 RNN 的「工作記憶」,攜帶過去資訊 梯度消失問題(Vanishing Gradient): - 反向傳播時,梯度需要穿越所有時間步 - 每步乘以一個小於 1 的數,梯度指數衰減 - 結果:RNN 難以學習長距離依賴關係(如 100 步前的資訊) LSTM 解決方案——三個閘門機制: - 遺忘閘(Forget Gate):決定從記憶細胞中遺忘哪些資訊(0=完全忘,1=完全保留) - 輸入閘(Input Gate):決定哪些新資訊寫入記憶細胞 - 輸出閘(Output Gate):決定從記憶細胞中輸出哪些資訊給下一層 GRU(Gated Recurrent Unit): - 將 LSTM 的三個閘門簡化為兩個(重置閘、更新閘) - 參數量少,訓練更快,在許多任務上與 LSTM 表現相當 雙向 RNN(Bidirectional RNN): - 同時從序列頭尾兩個方向處理輸入 - 每個時間步的輸出結合「過去脈絡」與「未來脈絡」 - 適用於文字分類、命名實體識別等任務(可看到完整句子後再預測)
🎙️ Podcast(中文)
一句話搞懂
RNN(遞迴神經網路)就像一個有工作記憶的人:它在讀每一個字、每一個數字時,都把前面看過的內容帶在腦子裡,所以能理解「前後文的關係」——LSTM 則是記憶力更強、更不容易忘事的進化版本。
白話解說
為什麼順序很重要——一般神經網路的盲點
考慮以下兩句話:
「股票今天大漲,投資人心情很好」
「股票今天大跌,投資人心情很好」
這兩句話的詞彙大部分相同,但「大漲」和「大跌」的位置讓整個句意完全相反。若你把每個字拆開,忽略順序,這兩句話幾乎無法區分。
再考慮時間序列資料:
台積電股價(週): 580, 590, 605, 615, 620, ...
台北氣溫(日): 12, 14, 18, 22, 25, ...
今天的股價「依賴」昨天的股價,明天的氣溫「依賴」今天的氣溫。這種「現在的值取決於過去的值」的性質,叫做時序依賴(Temporal Dependency)。
一般的多層感知器(MLP)或卷積神經網路(CNN)有一個根本限制:每次輸入都是獨立的。你把今天的特徵丟進去,它只看今天的資料,對昨天、前天、上個月的趨勢毫無記憶。這就像一個每天失憶的人試圖分析股票趨勢——完全做不到。
序列模型(Sequence Model)的誕生就是為了解決這個問題:它能記住過去,用過去預測未來。
RNN 的核心:hidden state 作為記憶
RNN 的關鍵設計是引入了隱藏狀態(Hidden State,h),它在每個時間步之間傳遞,承載著「目前為止看過的所有資訊的摘要」。
RNN 的運作流程:
時間步 t=1:
輸入 x₁(第一個字/數值)
+ 初始隱藏狀態 h₀(通常是全零向量)
→ 計算新隱藏狀態 h₁ = f(x₁, h₀)
→ 輸出 y₁
時間步 t=2:
輸入 x₂(第二個字/數值)
+ 上一步的隱藏狀態 h₁(帶著第一步的記憶)
→ 計算新隱藏狀態 h₂ = f(x₂, h₁)
→ 輸出 y₂
時間步 t=3:
輸入 x₃
+ 上一步的隱藏狀態 h₂(帶著前兩步的記憶)
→ h₃ = f(x₃, h₂)
...
隱藏狀態 h 就是 RNN 的「工作記憶」。每一步都把當前輸入和過去記憶混合,產生更新後的記憶,再傳給下一步。
視覺化比喻:想像一位翻譯員正在同步翻譯演講。她每聽到一個詞,都會結合「目前的工作記憶」(對整句話脈絡的理解)和「剛聽到的新詞」,來更新自己的理解,並在適當時機輸出譯文。這就是 RNN 的工作方式。
梯度消失問題:RNN 的致命弱點
基礎 RNN 有一個嚴重的問題,讓它在長序列上表現很差:梯度消失(Vanishing Gradient Problem)。
要理解這個問題,先回想神經網路的訓練方式:透過反向傳播(Backpropagation)計算損失函數對每個權重的梯度,然後用梯度下降更新權重。
RNN 在反向傳播時,梯度必須穿越每一個時間步,從序列末端傳回序列開頭。每穿越一個時間步,梯度就要乘以一個數(激活函數的導數)。如果這個數小於 1(例如 sigmoid 函數的導數最大值只有 0.25),那麼穿越 100 個時間步後:
梯度大小 ≈ 0.25¹⁰⁰ ≈ 6 × 10⁻⁶¹
這個數字趨近於零,表示距離輸出 100 步之前的權重幾乎收不到任何更新信號。RNN 因此「遺忘」了遠處的資訊。
直覺比喻:你試圖向 100 個人傳遞一條訊息(口耳相傳),每個人傳遞時都稍微扭曲一點。傳到第 100 個人時,原始訊息已經面目全非。梯度消失就是這個「傳話遊戲」導致信號在傳遞中消失殆盡。
這個問題的實際影響:基礎 RNN 只能記住大約 10–20 個時間步以內的資訊,更長的依賴關係(如一段對話的前後呼應)就完全學不到。
LSTM:用三個閘門解決遺忘問題
1997 年,Hochreiter 和 Schmidhuber 提出了 LSTM(Long Short-Term Memory,長短期記憶網路),透過精巧的「閘門機制(Gating Mechanism)」解決了梯度消失問題。
LSTM 的核心創新是引入了一條記憶細胞(Cell State,C),它就像一條高速公路,資訊可以幾乎不受干擾地流通整個序列。閘門則決定哪些資訊上高速公路、哪些資訊下高速公路。
LSTM 的三個閘門:
遺忘閘(Forget Gate)
問題:舊記憶有哪些需要清除?
遺忘閘根據當前輸入和上一步的隱藏狀態,輸出一個介於 0 到 1 之間的向量,決定記憶細胞中的每個值要保留多少比例(0 = 完全遺忘,1 = 完全保留)。
情境舉例:閱讀文章時
「台北市長王某某今天宣布...」
→ 遺忘閘:清除前段「某某」的資訊
(因為新的主語已出現,前一個主語資訊不再需要)
「...隨後,市議員李某某指出...」
→ 遺忘閘:部分清除「市長王某某」,保留「台北市」的脈絡
輸入閘(Input Gate)
問題:新資訊有哪些值得記住?
輸入閘決定當前時間步的哪些新資訊應該寫入記憶細胞,以及寫入的強度。這個過程分兩步:先用輸入閘決定「更新哪些位置」,再用 tanh 函數產生「候選新內容」,兩者相乘後加入記憶細胞。
情境舉例:股票預測
輸入:「台積電今日成交量創近三個月新高,外資大幅買超」
→ 輸入閘:「成交量創新高」和「外資買超」是重要的新資訊,應強力寫入記憶
→ 「今日」這類時間詞重要性低,寫入強度小
輸出閘(Output Gate)
問題:現在要從記憶中輸出哪些內容?
輸出閘決定記憶細胞中的哪些部分應該作為當前時間步的隱藏狀態輸出,傳給下一層或作為預測依據。同樣的記憶細胞,在不同的任務脈絡下,可能輸出不同的部分。
情境舉例:問答系統
記憶細胞中同時存有「誰、何時、何地、做了什麼」
回答「誰做了這件事?」的問題:
→ 輸出閘:主要輸出「誰」的相關記憶,壓制其他資訊
回答「什麼時候?」的問題:
→ 輸出閘:主要輸出「時間」的相關記憶
三閘門的協同效果:記憶細胞中的資訊受到精確控制——不需要的舊資訊被遺忘閘清除,重要的新資訊被輸入閘寫入,需要的資訊被輸出閘在正確時機輸出。這條受控制的「高速公路」讓梯度可以在長序列中較為完整地傳遞,LSTM 因此能記住數百步前的重要資訊。
GRU:簡化版的 LSTM
2014 年,Cho 等人提出了 GRU(Gated Recurrent Unit,閘控遞迴單元),將 LSTM 的三個閘門簡化為兩個:
重置閘(Reset Gate):決定過去的記憶有多少要「重置」(忽略),控制新的隱藏狀態中舊記憶的比例。 更新閘(Update Gate):決定新隱藏狀態中,舊記憶和新資訊各佔多少比例(類似 LSTM 的遺忘閘和輸入閘的組合)。
| 比較項目 | LSTM | GRU |
|---|---|---|
| 閘門數量 | 3 個(遺忘、輸入、輸出) | 2 個(重置、更新) |
| 記憶機制 | Cell state + Hidden state 分離 | 只有 Hidden state |
| 參數量 | 較多(約 4 倍基礎 RNN) | 較少(約 3 倍基礎 RNN) |
| 訓練速度 | 較慢 | 較快 |
| 長距離依賴 | 通常略優 | 接近 LSTM |
| 適合場景 | 語言模型、機器翻譯 | 較短序列、資源受限時 |
實務選擇原則:若序列較短(< 100 步)或計算資源有限,先試 GRU;若序列很長或任務需要精細的長距離依賴,用 LSTM。在許多實際任務上,兩者差異不大,最終還是要靠實驗比較。
雙向 RNN:同時看過去和未來
標準 RNN 只從序列頭讀到尾(左到右),每個時間步只能看到「過去的脈絡」。但在某些任務中,「後面的字」對理解「當前的字」同樣重要。
雙向 RNN(Bidirectional RNN,BiRNN)的做法:
正向 RNN: 從左到右讀序列 → h_forward
← 兩個方向的輸出合併 →
反向 RNN: 從右到左讀序列 → h_backward
最終輸出 = [h_forward, h_backward](拼接)
為什麼需要雙向?
句子:「他把___放在桌上」
↓
只看前文(正向):他、把 → 「___」可能是很多東西
同時看後文(雙向):他、把、放在、桌上 → 「___」更可能是物品名詞
或者一個更明顯的例子:
句子:「蘋果公司今天發布了新的 iPhone」
↓
只看「蘋果」:水果 or 公司?
看「蘋果」後面的「公司」:確定是企業名稱
雙向 RNN 特別適合文字分類、命名實體識別(NER)、情感分析等任務——因為這些任務需要在讀完整個句子後再下判斷,可以同時利用前後文脈絡。
限制:雙向 RNN 無法用於即時串流預測(因為需要看到整個序列才能從右到左讀),只適合「輸入完整後再分析」的離線任務。
應用場景
台灣股市價格預測與天氣預測
案例一:台股短期走勢預測
某量化投資研究機構使用 LSTM 對台灣加權指數(TAIEX)進行短期預測,輸入特徵包括:
- 過去 60 個交易日的收盤價、開高低收、成交量
- 技術指標(RSI、MACD、布林通道)
- 外資買超/賣超金額
LSTM 架構設計:
輸入序列:60 天 × 15 個特徵
↓
LSTM 層(128 個單元,回傳序列)
↓
Dropout(0.3)防止過擬合
↓
LSTM 層(64 個單元,只回傳最後輸出)
↓
全連接層(1 個輸出):預測次日收盤價漲跌幅(%)
實際表現(回測結果):
- 方向準確率(漲跌方向預測正確):約 58–62%
- 與 ARIMA 等傳統統計模型相比,在趨勢轉折點的反應更快
- 配合停損機制,年化夏普比率約 1.2–1.5
重要注意事項:股市受政治事件、突發消息影響極大,LSTM 可以學習歷史模式,但無法預測「黑天鵝事件」(如 COVID-19 爆發、重大地緣政治衝突)。量化研究員通常把 LSTM 預測作為多因子策略中的一個信號,而非唯一依據。
案例二:中央氣象署降雨量預測
中央氣象署使用 Bidirectional LSTM 進行短期(6–24 小時)降雨量預測,輸入資料包括:
- 多個氣象觀測站的溫度、溼度、氣壓、風速時序資料
- 衛星雲圖特徵
- 雷達回波強度
由於降雨系統從太平洋往台灣移動,雙向 LSTM 能同時捕捉「過去氣象條件的演變趨勢」和「未來一段時間的預計條件(由數值天氣預報提供)」,預測準確度比單向 LSTM 提升約 8–12%。
特別在颱風期間,LSTM 能學習到「颱風眼接近前的氣壓變化模式」,提前 12 小時對豪雨地區發出警告,讓縣市政府有足夠時間做預防措施。
常見誤區
誤區一:把 RNN/LSTM 當成所有序列問題的萬能解法
LSTM 在序列建模上確實強大,但並非所有「有時間戳的資料」都適合用 LSTM。若序列中各時間點是相對獨立的(例如每個月的報表分析,月份之間沒有強烈的時序依賴),用一般的 MLP 或隨機森林反而更簡單有效,且不容易過擬合。真正需要 RNN 的情境是:當前時間點的資訊「確實依賴於」過去若干步的資訊,而且這個依賴關係很複雜,無法簡單用手工特徵(如移動平均)捕捉。
誤區二:LSTM 能記住「無限遠」的過去
LSTM 雖然解決了梯度消失的問題,但並不代表它能完美記住任意長度的序列。在實際訓練中,LSTM 的有效記憶長度通常也只有數百步左右。面對非常長的文件(如幾千字的文章),LSTM 仍然會在早期出現的重要資訊被後來的資訊覆蓋。這正是 Transformer 和注意力機制後來能取代 LSTM 的根本原因之一——Transformer 對序列中任意兩個位置都能直接建立關聯,不受距離限制(詳見 M04-05)。
誤區三:序列的「時間步」等同於「物理時間」
RNN 的「時間步(time step)」只是序列中的位置索引,不一定代表真實的物理時間。RNN 可以處理任何有順序的資料:文字(每個字/詞是一個時間步)、DNA 序列(每個核苷酸是一個時間步)、音訊波形(每個採樣點是一個時間步)。只要資料是有意義的序列,且前後元素有依賴關係,就可以用 RNN 類的架構。不要被「時間」這個名詞誤導,以為 RNN 只能處理有時間戳的感測器資料。
小練習
練習一:RNN 記憶機制的情境分析
以下是一段對話系統的場景,請判斷應該使用哪種 RNN 架構,並說明理由:
場景:一個客服機器人正在即時接收用戶說話的語音串流(用戶說一個字,機器人就要更新理解),並在用戶說完整句話後,判斷這句話是「抱怨」、「查詢」還是「稱讚」。
請問:
- 這個任務應使用單向 RNN 還是雙向 RNN?
- 基礎 RNN 和 LSTM 哪個更適合?為什麼?
- 假設對話系統已知用戶的前 10 句對話紀錄,要讓模型記住前面說過的事情,這個需求對 LSTM 有什麼挑戰?
看解答
**問題 1:單向 RNN vs 雙向 RNN** 這個場景需要分兩個階段思考: - **即時接收語音串流時(邊聽邊更新理解)**:必須用**單向 RNN**。因為用戶說話是即時串流,機器人每收到一個詞就要更新理解,此時根本還沒有「後面的字」可以看。雙向 RNN 需要知道整句話才能從右到左讀,在即時場景下不可行。 - **用戶說完整句話、判斷意圖時**:可以用**雙向 LSTM**。整句話已收到,此時可以同時從前後兩個方向分析,例如句尾的「謝謝」可能改變前面抱怨語氣的整體判斷——「雖然上次有點問題,但這次處理得很好,謝謝」整體應判斷為「稱讚」,而非「抱怨」。雙向架構能捕捉到這種句末資訊對句首解讀的影響。 **問題 2:基礎 RNN vs LSTM** **應使用 LSTM(或 GRU)**,理由: 對話意圖判斷需要捕捉完整句子的語意,包含「轉折詞」(雖然、但是、不過)和情感強化詞(非常、完全、根本)等,這些詞可能出現在距離關鍵情感詞較遠的位置。基礎 RNN 受梯度消失影響,容易遺忘句中早期出現的重要資訊。LSTM 的閘門機制能選擇性地保留關鍵詞(如「非常不滿」中的「非常」修飾效果),跨越中間的無關詞彙,正確影響最終的意圖判斷。 **問題 3:前 10 句對話紀錄的挑戰** 如果要把前 10 句對話(可能共數百個詞)都作為 LSTM 的輸入,這對 LSTM 是一個**長距離依賴挑戰**: - 若用戶在第 1 句說「我想查台北到高雄的火車票」,在第 10 句說「那明天有沒有早班車?」,LSTM 需要在 10 句話之後還記得「台北到高雄」這個目的地。 - LSTM 雖然比基礎 RNN 記憶力強,但數百步後的資訊仍可能被覆蓋。 - 現代對話系統通常採用**Transformer + 注意力機制**(如 BERT 或 GPT)來解決這個問題,它能直接在第 10 句和第 1 句之間建立直接聯繫,不需要梯度穿越所有中間步驟。 這正是為什麼現在的對話 AI(如 ChatGPT)幾乎都改用 Transformer 架構,而不是 LSTM。練習二:LSTM 閘門機制的直覺理解
請閱讀以下情境,判斷 LSTM 的遺忘閘、輸入閘、輸出閘分別應該做什麼動作:
情境:LSTM 正在閱讀一篇新聞,任務是摘取文章的主題實體。當前讀到以下段落:
第一段:「台灣半導體產業龍頭台積電(TSMC)今日宣布,
將在日本熊本設立第二座晶圓廠,預計 2027 年量產。」
第二段:「此舉是台積電全球布局的重要一步。值得注意的是,
日本政府提供了高達 3,500 億日圓的補貼支持。」
第三段:「與此同時,台積電也確認了在美國亞利桑那州的
建廠計畫將如期推進,預計 2028 年開始生產。」
請問:
- 在讀完第一段後,遺忘閘應該清除什麼?保留什麼?
- 在進入第二段時,輸入閘應該重點寫入什麼新資訊?
- 在讀到第三段「亞利桑那州」時,輸出閘應該輸出什麼?