M04.05|Transformer 架構:AI 革命的核心引擎
Attention Is All You Need — 一篇論文改變了整個 AI 產業
本講學習重點
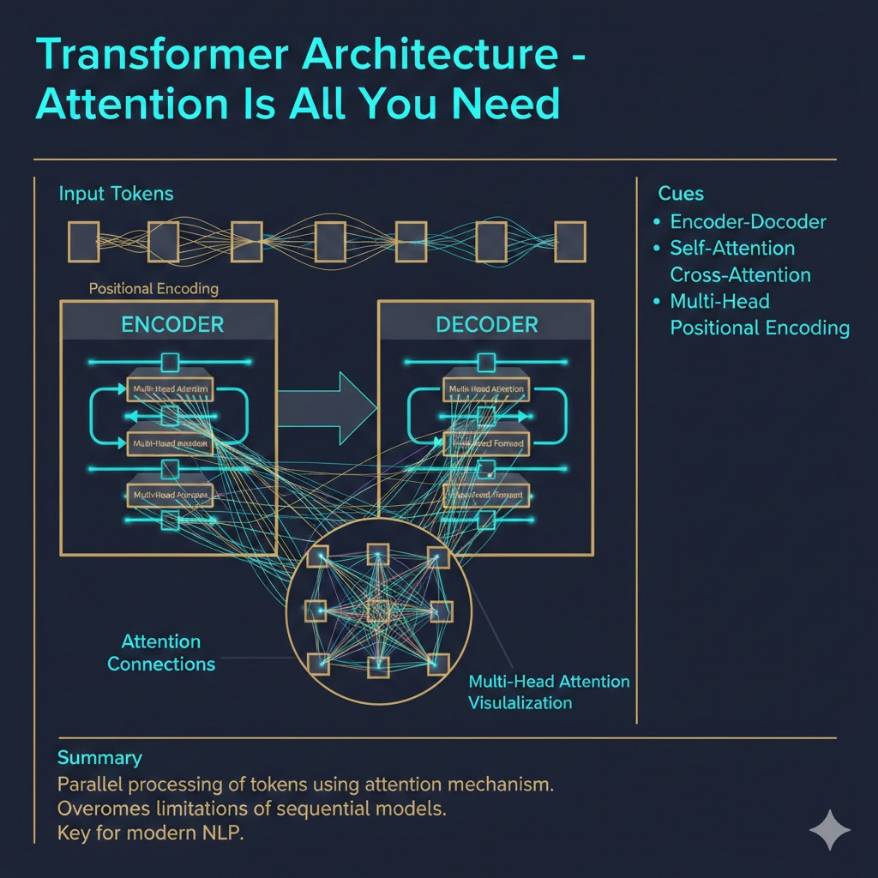
Transformer 是 2017 年 Google 提出的架構(論文「Attention Is All You Need」), 完全拋棄了 RNN 的遞迴結構,改用純注意力機制(Attention Mechanism)處理序列。 Self-Attention(自注意力)核心機制: - 序列中每個元素都能「直接注意到」其他任意元素,不受距離限制 - 計算方式:每個 token 生成 Q(查詢)、K(鍵)、V(值)三個向量 - Attention Score = softmax(QKᵀ / √d_k),再與 V 加權求和 Multi-Head Attention(多頭注意力): - 同時運行多組 Q、K、V 投影(多個「注意力頭」) - 每個頭學習不同類型的關係(語法、語意、位置等) - 結果拼接後用線性層整合 Positional Encoding(位置編碼): - Attention 本身沒有位置概念(是集合運算,不是序列運算) - 需要手動加入位置資訊(sin/cos 函數或可學習的嵌入) Encoder-Decoder 結構: - Encoder:將輸入序列編碼為上下文向量(BERT 類型) - Decoder:根據上下文和已生成的輸出,自回歸地生成序列(GPT 類型) 為什麼 Transformer 勝過 RNN: - 並行化訓練(RNN 必須逐步計算,無法並行) - 任意兩個位置直接交互,無距離限制(RNN 需逐步傳遞) - 更容易擴展到更大模型和更大資料集
🎙️ Podcast(中文)
一句話搞懂
Transformer 是一種神經網路架構,它讓序列中的每個詞都能「直接看到」其他任何詞——不管相隔多遠——並根據相關性決定要注意哪些詞,這個「選擇性注意」的機制讓 AI 第一次真正理解了長距離的語意關係,並催生了 GPT、BERT 等所有現代大型語言模型。
白話解說
一篇論文如何改變 AI 產業
2017 年 6 月,Google Brain 的研究團隊發表了一篇論文,標題霸氣直白:“Attention Is All You Need”(注意力就是你所需要的一切)。
這篇論文提出了 Transformer 架構,從根本上顛覆了序列建模的方式。六年後,這個架構成為了 GPT-4、Claude、Gemini、BERT 等幾乎所有頂尖 AI 模型的核心引擎。
為什麼這篇論文這麼重要?
在 Transformer 之前,處理語言的最佳工具是 LSTM(長短期記憶網路)。LSTM 雖然強大,但有兩個根本瓶頸:
- 順序計算:必須從序列頭讀到尾,第 100 個詞的計算必須等第 99 個詞完成,無法並行,訓練速度慢。
- 距離限制:即使是 LSTM,對幾百步前的資訊仍會逐漸遺忘,難以捕捉長文件中的長距離依賴。
Transformer 同時解決了這兩個問題,讓 AI 研究者第一次有了能夠高效訓練於數兆個詞語的架構,從而催生了「大語言模型(LLM)」時代。
Self-Attention:讓每個詞都能直接「注意」其他詞
Transformer 的核心創新是自注意力機制(Self-Attention)。
直覺理解——閱讀一個句子時你的大腦在做什麼:
考慮這個句子:「它走進銀行,拿出存摺,辦理了定期存款。」
當你讀到「銀行」這個詞時,你的大腦會:
- 注意到後面有「存摺」和「定期存款」→ 確認這是「金融機構」的銀行,而非「河岸」的銀行
- 相對忽略「走進」這個一般性動詞,因為它對消除歧義沒有幫助
當你讀到「它」這個代詞時,你的大腦會回頭搜尋:這個「它」指的是前文中的哪個名詞?
這種根據當前詞的需要,有選擇性地注意句子中其他詞的能力,就是 Self-Attention 在做的事情。
Self-Attention 的計算方式:
對句子中的每個詞,Self-Attention 計算它與句子中其他所有詞的「相關程度」,然後根據相關程度對所有詞的資訊做加權求和,得到這個詞的新表示(包含了脈絡資訊)。
輸入句子:「台積電 宣布 在 日本 設廠」
計算「台積電」對其他每個詞的注意力分數:
台積電 → 台積電:1.0(自身)
台積電 → 宣布:0.3(相關:主詞對動詞有語法依賴)
台積電 → 在:0.1(相關性低)
台積電 → 日本:0.4(相關:公司和地點有語意關聯)
台積電 → 設廠:0.5(相關:公司和行動是主要事件)
「台積電」的新表示 =
1.0 × 台積電的原始資訊
+ 0.3 × 宣布的原始資訊
+ 0.1 × 在的原始資訊
+ 0.4 × 日本的原始資訊
+ 0.5 × 設廠的原始資訊
→ 得到一個富含上下文的「台積電」向量
這個過程同時對句子中每個詞並行執行,因此可以完全並行化計算——這是 Transformer 訓練速度遠超 RNN 的關鍵。
Query、Key、Value:用搜尋引擎來理解
Self-Attention 的實際計算使用三個向量:Q(Query,查詢)、K(Key,鍵)、V(Value,值)。
最直覺的比喻——把它想成搜尋引擎:
你在 Google 搜尋「台積電財報」:
- Query(Q)= 你的搜尋詞「台積電財報」,代表你「正在問的問題」、「需要什麼資訊」
- Key(K)= 每個網頁的標題/標籤,代表每個資訊來源「宣稱自己是關於什麼的」
- Value(V)= 每個網頁的實際內容,代表每個資訊來源「真正包含的資訊」
搜尋引擎計算你的 Query 和每個網頁的 Key 的相符程度(注意力分數),排名高的網頁(分數高)的 Value 被優先展示給你。
在 Self-Attention 中:
每個詞在處理自己的時候,會生成三個角色:
- 用自己的 Q(我在問什麼?) 去搜尋其他詞
- 用自己的 K(我能提供什麼資訊?) 回應其他詞的搜尋
- 用自己的 V(我的實際資訊是什麼?) 在被選中時提供內容
具體計算步驟:
1. 每個詞 → 線性投影 → 生成 Q、K、V 三個向量
2. 計算注意力分數(Attention Score):
Score(i, j) = Qᵢ · Kⱼ / √d_k
(d_k 是向量維度,除以 √d_k 防止分數過大導致梯度消失)
3. 用 softmax 正規化分數(讓所有分數加總為 1,轉成「注意力權重」):
Weight(i, j) = softmax(Score(i, j))
4. 加權求和得到新表示:
Output(i) = Σⱼ Weight(i, j) × Vⱼ
Multi-Head Attention:從多個角度同時分析
單組 Q、K、V 只能學習一種「關注模式」。但語言中的關係是多維度的:
- 句法關係(主語和動詞)
- 語意關係(地點和動作)
- 指代關係(代詞和其所指的名詞)
- 修飾關係(形容詞和名詞)
Multi-Head Attention(多頭注意力) 的做法是:同時運行多組獨立的 Q、K、V 投影(每一組叫一個「頭」),每個頭學習不同類型的關係,最後把所有頭的輸出拼接起來,用一個線性層整合。
輸入 → 分成 8 個頭(以 8 頭為例):
頭 1(可能學到:主詞-動詞語法關係)
頭 2(可能學到:代詞指代關係)
頭 3(可能學到:情感詞和主體的關係)
頭 4(可能學到:時間詞和事件的關係)
...
頭 8(可能學到:某種組合關係)
↓
8 個頭的輸出 → 拼接 → 線性投影 → 最終輸出
為什麼這樣有效?
語言理解需要同時考慮多種維度的關係。單頭注意力被迫把所有類型的關係壓縮到一種注意力模式中;多頭注意力讓每個頭專注於一種關係類型,分工合作,再由線性層整合成完整的理解。
GPT-3 使用了 96 個注意力頭;GPT-4 的具體架構雖未公開,但估計注意力頭數更多。
Positional Encoding:告訴模型詞語的位置
Self-Attention 有一個特殊之處:它計算的是詞與詞之間的關係,完全不考慮「詞在句子中的位置」。
這意味著對 Self-Attention 來說,「我愛你」和「你愛我」是完全一樣的——因為詞語集合相同,只是順序不同。但這兩句話意思截然相反!
Positional Encoding(位置編碼) 解決了這個問題:在把詞語嵌入向量(Embedding)輸入 Transformer 之前,先加入一個「位置向量」,告訴模型「這個詞是序列中的第幾個」。
原始 Transformer 論文使用 sin/cos 函數生成位置向量:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
其中 pos 是位置索引(0, 1, 2, ...),i 是向量的維度索引
這個設計的優點是:不同距離的詞語之間,位置向量的差值有固定的模式,讓模型能推算出相對距離。現代 LLM 通常使用「可學習的位置嵌入(Learned Positional Embedding)」或更先進的 RoPE(旋轉位置嵌入),但核心思想一致:補足 Self-Attention 缺失的位置感。
Encoder-Decoder 結構
完整的 Transformer 由兩個部分組成:
Encoder(編碼器):
- 接收輸入序列(例如中文句子)
- 每個 token 都能注意到序列中所有其他 token(雙向)
- 輸出:每個 token 富含上下文資訊的向量表示(Context Vector)
Decoder(解碼器):
- 接收目標序列(例如英文翻譯),但有一個限制:生成第 i 個 token 時,只能看到前 i-1 個已生成的 token,不能看到未來(稱為 Masked Self-Attention)
- 同時透過 Cross-Attention,注意 Encoder 的輸出
- 自回歸(Autoregressive)地逐步生成輸出序列
機器翻譯流程:
輸入(中文):「台灣半導體產業舉足輕重」
↓ Encoder(雙向注意力)
上下文向量:[v₁, v₂, v₃, v₄, v₅]
↓ Decoder(單向生成 + Cross-Attention)
逐步生成(英文):
Taiwan → Taiwan's → Taiwan's semiconductor → ... → Taiwan's semiconductor industry is pivotal
不同任務,不同使用方式:
| 架構變體 | 代表模型 | 適用任務 |
|---|---|---|
| 只用 Encoder | BERT | 文字理解、分類、問答(需要理解整個輸入) |
| 只用 Decoder | GPT 系列 | 文字生成(自回歸,逐詞生成) |
| 完整 Encoder-Decoder | 原始 Transformer、T5 | 機器翻譯、摘要(序列到序列) |
為什麼 Transformer 能打敗 RNN
兩種架構的根本差異:
| 比較維度 | RNN / LSTM | Transformer |
|---|---|---|
| 訓練並行化 | 不可以(必須逐步計算) | 完全可以並行 |
| 長距離依賴 | 梯度消失限制(實際有效 ~數百步) | 任意距離直接建立關聯 |
| 序列長度 | 效率隨長度線性下降 | 計算量隨長度平方增長(但可並行) |
| 擴展性 | 難以擴展到數十億參數 | 可擴展至數千億參數 |
| 訓練資料需求 | 中等 | 需要大量資料才能發揮優勢 |
| 推論時記憶體 | 僅需保留 hidden state | 需要 KV Cache(隨上下文長度增長) |
並行化是決定性優勢:LSTM 訓練一句 100 個詞的句子,需要序列地執行 100 步計算;Transformer 的 100 個詞可以同時計算所有的注意力關係,訓練速度提升了幾十倍。這讓 AI 實驗室第一次可以把模型規模和訓練資料規模擴展到前所未有的量級,最終導致了 GPT-3、ChatGPT 等突破性模型的誕生。
應用場景
GPT、BERT 與 Vision Transformer
GPT 系列(OpenAI):只用 Decoder 的語言生成
GPT(Generative Pre-trained Transformer)使用純 Decoder 架構,透過預測「下一個詞」的任務進行預訓練,核心特點是自回歸生成。
GPT 生成「台灣 AI 產業的發展方向是」之後:
輸入「台灣 AI 產業的發展方向是」
→ 預測最可能的下一個詞(例如「硬體」)
→ 輸入「台灣 AI 產業的發展方向是硬體」
→ 預測下一個詞(例如「與」)
→ 持續循環,直到生成結束符號
GPT 參數規模演進:GPT-1(1.17億)→ GPT-2(15億)→ GPT-3(1750億)→ GPT-4(估計數兆,混合專家架構)。參數規模的成長帶來了「湧現能力(Emergent Abilities)」——模型超過某個規模閾值後,突然能做到未曾專門訓練的任務(如數學推理、程式撰寫)。
BERT(Google):雙向 Encoder 的理解能力
BERT(Bidirectional Encoder Representations from Transformers)使用純 Encoder 架構,預訓練任務是「克漏字(Masked Language Model)」:隨機遮蔽 15% 的 token,讓模型預測被遮蔽的詞。
由於 BERT 的 Encoder 是雙向的,它能同時看到被預測詞的前文和後文,建立更豐富的語意理解。BERT 在台灣的應用場景包括:
- 中文 BERT / RoBERTa:政府公文分類、法院判決書分析、新聞情感分析
- 繁體中文 BERT(如 CKIP-BERT):中央研究院開發,針對繁體中文優化,用於台灣學術和公部門的 NLP 任務
- 金融 BERT:台灣銀行業用於財報文字分析和客服問答系統
Vision Transformer(ViT):把圖片當成句子來讀
2020 年,Google 的研究者發現:如果把圖片切成一個個 16×16 的小方塊(Patch),每個 Patch 展平成向量,就可以把它們當成「視覺詞語(Visual Tokens)」輸入 Transformer,效果超越了 CNN。
224×224 圖片 → 切成 14×14 = 196 個 Patch(每個 16×16 像素)
196 個 Patch → 每個 Patch 展平並線性投影 → 196 個向量
加入 [CLS] token + 位置編碼
輸入 Transformer Encoder → 用 [CLS] token 的輸出做圖片分類
ViT 的關鍵發現:注意力機制可以捕捉圖片中任意兩個位置的關係,不像 CNN 的卷積只能看局部鄰域,ViT 從第一層就能建立全局關係。
台灣半導體產業的應用:台積電等晶圓廠使用 ViT 類架構進行晶圓瑕疵偵測,模型能注意到不同尺度的瑕疵特徵(從單個晶粒的微觀缺陷到整片晶圓的分布模式),檢測準確率達到 99.5% 以上。
常見誤區
誤區一:Transformer 是因為「更聰明」才打敗 RNN
許多人以為 Transformer 取代 RNN 是因為 Self-Attention 比 LSTM 在理論上更優雅或更「智慧」。實際上,更關鍵的原因是工程可擴展性。Transformer 可以完全並行訓練,讓研究者能夠把模型規模從數億擴展到數千億參數,並使用海量的預訓練資料。LSTM 在相同規模下訓練時間是不可接受的。換句話說,即使在概念上 Self-Attention 和 LSTM 的表達能力差不多,Transformer 的並行化優勢讓它能用更多資源、更多資料進行訓練,從而取得更好的效果。這是工程實用性的勝利,而非純粹理論的勝利。
誤區二:Attention Weight(注意力權重)代表模型「真正理解」了詞語關係
Transformer 的注意力權重有時被視覺化為「模型理解了哪個詞對哪個詞重要」,進而被當作可解釋性的工具。但研究顯示,注意力權重和模型的最終決策之間的關係非常複雜——高注意力權重不一定代表那個詞對最終答案貢獻大,低注意力權重的詞可能通過其他路徑間接影響輸出。更嚴謹的可解釋性方法(如 SHAP、梯度歸因法 Integrated Gradients)在解釋 Transformer 決策時比直接看注意力圖更可靠。將注意力視覺化作為教學工具是合理的,但不應誤以為它等同於模型真實的「思考過程」。
誤區三:Transformer 解決了所有 NLP 問題,學 RNN 已經沒有價值
Transformer 確實在大多數基準測試上超越了 LSTM,但 RNN 並未完全退場。在以下情境中,RNN 類架構仍有競爭力:(1) 資源受限的邊緣裝置:Transformer 的 KV Cache 和注意力計算在長序列時記憶體佔用很高,LSTM/GRU 的記憶體使用是常數級,適合低功耗嵌入式系統;(2) 即時串流資料處理:RNN 是天生的「online」模型,每來一個新資料點就更新狀態,而 Transformer 必須一次處理完整輸入;(3) 超長序列:Self-Attention 的計算量是序列長度的平方,處理幾萬步的序列時即使是 Transformer 也會遇到效率瓶頸(雖然有 Flash Attention、Sparse Attention 等優化方案)。了解 RNN 的工作原理,是理解 Transformer 優勢和限制的必要背景知識。
小練習
練習一:Self-Attention 的直覺應用
閱讀以下兩個句子,預測 Self-Attention 機制應該在哪些詞對之間分配「高注意力權重」,並說明理由:
句子 A:「中央銀行今天決定維持利率不變,台股隨即上漲。」
句子 B:「他說他不喜歡它,但後來他又買了一個。」
請回答:
- 在句子 A 中,「台股」這個詞應該對哪些詞分配最高的注意力,才能理解「台股為什麼上漲」?
- 在句子 B 中,「它」這個詞的 Self-Attention 面臨什麼挑戰?這反映了 Transformer 的什麼能力和限制?
看解答
**問題 1:「台股」的注意力分配** 在句子 A 中,「台股」要理解「隨即上漲」的因果關係,Self-Attention 應該在以下詞對上分配高權重: - **「台股」→「利率不變」**:高注意力。「利率」是影響股市的核心經濟指標,這是直接因果關係。BERT 類模型在訓練大量財經文字後,會學到「利率穩定 → 市場正面反應」的語意關聯。 - **「台股」→「上漲」**:高注意力。「上漲」是「台股」的謂語,語法上主詞和動詞的依賴關係非常強。 - **「台股」→「中央銀行」**:中等注意力。雖然中央銀行是決策主體,但對「台股」的直接語意關聯略低於「利率不變」。 - **「台股」→「今天」「隨即」**:低注意力。這些時間副詞對理解「台股為什麼上漲」貢獻很小。 關鍵點:Transformer 透過 Multi-Head Attention,可以用一個頭捕捉「台股-上漲」的語法依賴,同時用另一個頭捕捉「台股-利率」的語意關聯,兩種資訊都被整合進「台股」的上下文向量中。 **問題 2:句子 B 中「它」的挑戰** 句子 B:「他說他不喜歡它,但後來他又買了一個。」 **挑戰:代詞消解(Coreference Resolution)** - 第一個「他」、第二個「他」、第三個「他」是否指同一個人?(如果前文有多個男性角色,很難確定) - 「它」指代什麼?句子中只有「一個」可能是指代對象,但「一個」本身是數量詞,其所指物件在這個孤立句子中根本沒有出現——可能在更前面的段落。 - 「他又買了一個」中的「一個」是否和「它」指同一個東西? **Transformer 的能力和限制:** 能力:在這個孤立句子中,Self-Attention 可以建立「它」和「他不喜歡」、「他又買了一個」之間的語法關聯,推斷「它」是某個被他不喜歡卻又購買的物件,並且「一個」可能和「它」指同類事物。這種句子內部的指代推斷,Transformer 做得相當好。 限制:如果「它」所指的對象在更早的段落(甚至另一個對話輪次),Transformer 必須依賴上下文視窗(Context Window)。若上下文視窗不夠長,或前文的指代實體距離太遠,模型可能無法正確消解代詞。 這個例子說明了為什麼「長上下文視窗」是現代 LLM 的重要競爭指標——GPT-4 Turbo 支援 128k tokens 的上下文,Claude 3 支援 200k tokens,就是為了讓模型能夠處理更遠距離的指代和依賴關係。練習二:Encoder-Only vs Decoder-Only 的選擇
以下是三個台灣企業的 AI 應用需求,請判斷每個需求應使用 Encoder-only(如 BERT 類)、Decoder-only(如 GPT 類)還是完整 Encoder-Decoder(如 T5 類)架構,並說明理由:
需求 A:台灣某法律科技公司要建立一個「合約風險條款偵測系統」:輸入一份完整的合約文件(通常 3,000–10,000 字),輸出每個條款的風險評級(高/中/低)和風險類型標籤。
需求 B:某家媒體集團要建立一個「新聞摘要生成系統」:輸入完整的新聞文章(500–2,000 字),輸出一段精簡的 3–5 句摘要。
需求 C:一個即時客服系統,用戶輸入問題(通常 20–50 字),系統需要根據已有的 FAQ 知識庫生成自然語言的回答(50–200 字)。