M04.06|反向傳播與梯度下降:AI 怎麼從錯誤中學習
模型答錯了怎麼辦?算出錯多少、往對的方向調整 — 重複幾百萬次
本講學習重點
損失函數(Loss Function):量化模型預測值與真實值之間的差距,是訓練的「評分卡」。 常見損失函數: - 均方誤差(MSE):回歸任務,懲罰大誤差更重 - 交叉熵(Cross-Entropy):分類任務,衡量預測機率分布和真實分布的差距 梯度下降(Gradient Descent): - 梯度 = 損失函數對每個參數的偏微分(斜率方向) - 更新規則:參數 ← 參數 - 學習率 × 梯度 - 梯度指向損失上升最快的方向,「負梯度」指向下降最快的方向 學習率(Learning Rate): - 太大:步伐過大,跳過最優點,甚至發散 - 太小:收斂極慢,可能卡在局部最優 - 實務常用學習率調度(LR Scheduler):從大到小逐漸降低 反向傳播(Backpropagation)= 鏈式法則(Chain Rule)的系統化應用: - 從輸出層的損失出發,利用鏈式法則逐層往回推算每個參數的梯度 - 深度學習框架(PyTorch、TensorFlow)的 autograd 自動完成此過程 SGD vs Adam: - SGD:每次用相同學習率更新,簡單但對學習率敏感 - Adam(Adaptive Moment Estimation):為每個參數自適應調整有效學習率, 結合動量(Momentum)加速收斂 + 自適應(Adaptive)減少震盪 - 實務建議:預設先用 Adam,若需要更好的泛化能力可嘗試 AdamW 或 SGD + Momentum Batch Size 的影響: - 小 Batch(8–32):梯度估計噪音大,訓練速度慢,但有正則化效果(泛化往往更好) - 大 Batch(512–4096):梯度估計穩定,GPU 利用率高,訓練快,但可能收斂到「尖銳」最小值
🎙️ Podcast(中文)
一句話搞懂
神經網路訓練就像一個學生在無限次練習考試:答錯了就量化錯多少(損失函數),算出每道題的哪個概念理解有誤(梯度),往正確方向修正理解(梯度下降更新參數),這個過程透過反向傳播高效地傳遍整個網路,重複幾百萬次後,模型就從「亂猜」學會了「精準預測」。
白話解說
損失函數:給模型的表現打分數
在神經網路訓練前,我們需要先定義一個明確的問題:什麼叫做「答對」,什麼叫做「答錯」,錯了多少算多嚴重?
損失函數(Loss Function) 正是這個「評分卡」,它計算模型預測值和真實答案之間的差距,輸出一個數字:損失值越大,模型答得越差;損失值越小,模型越準確。訓練的目標就是讓損失值越來越小。
常見的兩種損失函數:
均方誤差(Mean Squared Error,MSE)——用於回歸任務
\[\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (\hat{y}_i - y_i)^2\]其中 $\hat{y}_i$ 是模型預測值,$y_i$ 是真實值,$n$ 是樣本數。
為什麼要平方?
- 讓正負誤差都變成正數(不會互相抵消)
- 懲罰大誤差更重:預測差 2 分的懲罰是預測差 1 分的 4 倍(2² = 4 vs 1² = 1)
房價預測範例(單位:萬元):
真實價格 預測價格 誤差 平方誤差
1,500 1,480 -20 400
2,000 1,900 -100 10,000
800 820 20 400
MSE = (400 + 10,000 + 400) / 3 = 3,600 萬²
→ 第二筆(誤差 100 萬)對 MSE 的貢獻遠大於另外兩筆(各差 20 萬)
→ 模型受迫優先改善大誤差的預測,而非把多個小誤差拉到零
交叉熵損失(Cross-Entropy Loss)——用於分類任務
\[\text{CE} = -\sum_{c=1}^{C} y_c \log(\hat{p}_c)\]其中 $y_c$ 是真實標籤的 one-hot 向量(正確類別為 1,其餘為 0),$\hat{p}_c$ 是模型對類別 $c$ 預測的機率。
貓/狗分類範例:
真實類別:貓(one-hot: [1, 0])
模型預測 A:P(貓) = 0.95,P(狗) = 0.05
CE = -(1 × log(0.95) + 0 × log(0.05)) = -log(0.95) ≈ 0.051 ← 損失小
模型預測 B:P(貓) = 0.30,P(狗) = 0.70
CE = -(1 × log(0.30) + 0 × log(0.70)) = -log(0.30) ≈ 1.204 ← 損失大
模型預測 C:P(貓) = 0.05,P(狗) = 0.95
CE = -(1 × log(0.05)) = -log(0.05) ≈ 2.996 ← 損失極大
交叉熵的特性:不只看對錯,還看信心程度。答對但不確定(機率 51%)的懲罰比答對且自信(機率 99%)重;答錯且極度自信(機率 99% 卻選錯)的懲罰遠大於答錯但猶豫(機率 55%),這促使模型學會既要正確又要有根據地自信。
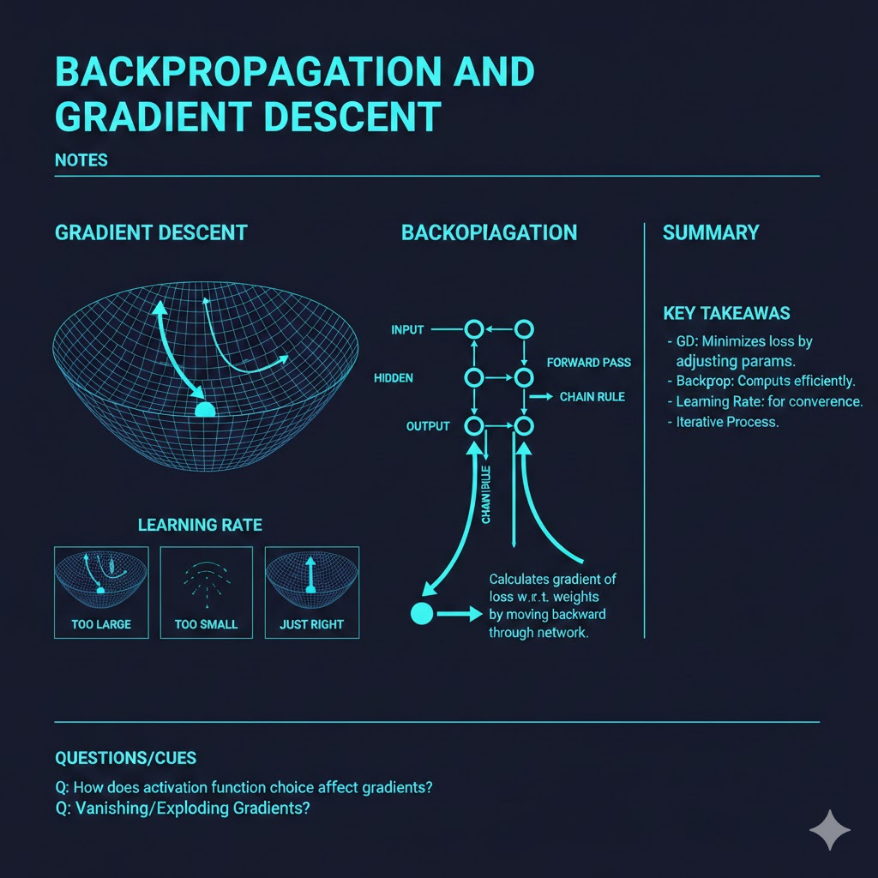
梯度下降:在損失函數的地形中尋找最低點
損失函數可以想象成一個多維的地形圖,每個神經網路參數(權重)對應地形的一個維度,損失值對應「海拔高度」。訓練的目標是找到地形中的最低點(最小損失)。
梯度(Gradient) 是損失函數對每個參數的偏微分,它告訴我們:如果增大這個參數,損失會往哪個方向、以多大的速度變化。
梯度下降的比喻——在濃霧中的山上尋找最低點:
想象你站在一座山上,四周是濃霧,你看不到全局地形,只能感受到「腳下的坡度」(梯度)。你想走到山谷最低點,策略是:感受當前位置的坡度,往坡度往下的方向走一步,然後重新感受,再走一步……重複這個過程,你會逐漸走向山谷。
梯度下降的更新規則:
參數更新 = 當前參數 - 學習率 × 梯度
θ_new = θ_old - η × ∇L(θ)
其中:
θ(theta)= 模型參數(所有的權重和偏差)
η(eta)= 學習率(學習率,每步的大小)
∇L(nabla L)= 損失函數的梯度(坡度方向)
負號(-)= 往梯度「相反」的方向走(梯度指向上坡,我們要走下坡)
視覺化理解:
損失函數地形(簡化為 2D):
損失值
│ ___
│ / \ ← 初始位置(損失高)
│ / \___/\_
│ / \
│_____/ \_____
└─────────────────────────────→ 參數值
↑
最優點(損失最小)
梯度下降過程:
第 1 步:在初始位置,梯度向右(損失在往右增加),更新參數往左
第 2 步:往下走一步,重新計算梯度
...
第 N 步:到達谷底(或附近)
學習率:步伐大小的藝術
學習率(Learning Rate,η)決定每次更新時參數移動多少,是神經網路訓練中最重要、最難調整的超參數之一。
學習率太大:
損失值
│ *
│ * * ← 跳過最優點了!
│ * *
│ * ← 不斷震盪,甚至發散(損失反而越來越大)
└──────────────────→ 迭代次數
類比:下山時每步邁 100 公尺,很容易從這個山坡跨到對面山坡,
在兩個山坡之間來回震盪,永遠到不了谷底。
學習率太小:
損失值
│*
│ *
│ *
│ * ← 每次只移動一點點,收斂極慢
│ *
│ * ...(還需要幾萬步才能到達谷底)
└──────────────────→ 迭代次數
類比:下山時每步只移動 1 公分,方向正確但速度慢到無法接受,
可能幾個月都還沒走到山谷。
學習率剛好:
損失值
│*
│ **
│ ***
│ ****_____ ← 穩定收斂到最低點
└──────────────────→ 迭代次數
實務解決方案——學習率調度(Learning Rate Scheduling):
訓練開始時用較大的學習率(快速接近最優點附近),後期逐漸減小學習率(精細尋找谷底)。常見策略包括:
- Cosine Annealing:學習率按餘弦函數從大到小,現代 LLM 訓練的標配
- Warmup + Decay:先從小學習率線性增大(Warmup),再逐漸衰減,避免訓練初期梯度不穩定時步伐過大
反向傳播:鏈式法則的系統化應用
反向傳播(Backpropagation)是高效計算神經網路所有參數梯度的演算法。其數學基礎是微積分的鏈式法則(Chain Rule)。
鏈式法則的直覺:
假設你的薪水受到多個因素影響:
你的工作表現 → 老闆的滿意度 → 部門業績 → 公司利潤 → 你的薪水
如果薪水受到「工作表現」的影響,可以用鏈式法則計算:
∂薪水/∂工作表現 = (∂薪水/∂公司利潤) × (∂公司利潤/∂部門業績)
× (∂部門業績/∂老闆滿意度) × (∂老闆滿意度/∂工作表現)
每個因素的影響都通過中間鏈條一層層傳遞。
在神經網路中的應用:
輸入層 → 第一層 → 第二層 → ... → 輸出層 → 損失值
前向傳播(Forward Pass):從輸入層到輸出層,計算每個神經元的值
x → W₁x + b₁ → ReLU → W₂(...) + b₂ → ... → ŷ → L(ŷ, y)
反向傳播(Backward Pass):從損失值往回推,計算每個參數的梯度
∂L/∂W₁ = (∂L/∂ŷ) × (∂ŷ/∂...層) × ... × (∂...層/∂W₁)
↑ ↑
輸出層的梯度 第一層參數的梯度
關鍵洞察:反向傳播的計算非常高效,因為它重用了前向傳播時已計算的中間值,只需要一次完整的前後傳播,就能計算所有參數的梯度。若沒有反向傳播,需要對每個參數分別做有限差分(Finite Difference)估計梯度,計算量等於參數量 × 前向傳播次數——對有數十億參數的模型,完全不可行。
深度學習框架的自動微分(Autograd):
現代深度學習框架(PyTorch、TensorFlow、JAX)內建自動微分功能,工程師不需要手動推導梯度公式,框架會追蹤所有計算操作,自動構建計算圖,自動執行反向傳播。
# PyTorch 範例:框架自動計算梯度
import torch
x = torch.tensor([2.0], requires_grad=True)
y = x ** 2 + 3 * x + 1 # y = x² + 3x + 1
y.backward() # 觸發反向傳播
print(x.grad) # ∂y/∂x = 2x + 3 = 2×2 + 3 = 7
# 輸出:tensor([7.]) # 框架自動算出了梯度,工程師不需要手算
SGD vs Adam:優化器的選擇
優化器(Optimizer)決定如何利用梯度來更新參數。不同的優化器有不同的策略,對訓練速度和最終效果影響顯著。
隨機梯度下降(Stochastic Gradient Descent,SGD)
最基礎的優化器。每次從訓練資料中隨機抽取一個 Batch 計算梯度,然後更新參數。
SGD 更新規則:
θ ← θ - η × ∇L(θ; mini-batch)
特點:
+ 原理簡單,記憶體效率高
+ 配合動量(Momentum)可加速收斂、減少震盪
- 對學習率敏感,需要仔細調整
- 在鞍點(Saddle Point)附近收斂慢
SGD + Momentum(帶動量的 SGD):
加入動量(Momentum)後,參數更新時會保留上一步的方向,就像滾球下山積累速度:
v ← β × v_prev + η × ∇L(θ) (β 通常設 0.9)
θ ← θ - v
效果:在持續往同方向的維度上加速,在震盪的維度上減速
就像小球在光滑山坡上積累速度,在崎嶇地形上自然平衡
Adam(Adaptive Moment Estimation)
2014 年 Kingma 和 Ba 提出的優化器,目前是深度學習的事實標準。
Adam 同時引入了兩個機制:
一階動量(First Moment / Momentum):記錄梯度的指數移動平均,讓更新有「慣性」,加速在一致方向上的收斂。
二階動量(Second Moment / Adaptive):記錄梯度平方的指數移動平均,用於自適應調整每個參數的有效學習率——梯度波動大的參數自動降低學習率,梯度穩定的參數自動提高學習率。
Adam 更新規則(簡化版):
m ← β₁ × m_prev + (1 - β₁) × ∇L (一階動量,β₁≈0.9)
v ← β₂ × v_prev + (1 - β₂) × (∇L)² (二階動量,β₂≈0.999)
m̂ = m / (1 - β₁ᵗ) (偏差修正)
v̂ = v / (1 - β₂ᵗ)
θ ← θ - η × m̂ / (√v̂ + ε) (ε≈1e-8 防止除零)
Adam 的直覺比喻:Adam 就像一個自適應的導航系統,它不只看當前的坡度,還記得過去的行進方向(動量),並根據各維度的「道路顛簸程度」(梯度方差)自動調整每個方向的步伐大小——崎嶇的路走慢點(高方差 → 小步伐),平坦的路走快點(低方差 → 大步伐)。
| 比較項目 | SGD | SGD + Momentum | Adam |
|---|---|---|---|
| 學習率靈敏度 | 高(需仔細調整) | 中 | 低(預設值通常夠用) |
| 收斂速度 | 慢 | 中 | 快 |
| 記憶體使用 | 低 | 中 | 較高(需儲存動量和方差) |
| 泛化能力 | 有時優於 Adam | 中 | 有時略差(可能收斂到更「尖銳」的最小值) |
| 適用場景 | 圖像分類(配合調度) | 通用 | 幾乎所有場景的預設選擇 |
實務建議:
- 訓練初期先用 Adam(學習率設 3e-4 或 1e-3),快速確認模型方向
- 若想追求最佳泛化能力(如在標準基準測試上),可嘗試 SGD + Momentum + Cosine LR Scheduling
- 大型語言模型訓練通常使用 AdamW(Adam + Weight Decay 解耦),比標準 Adam 泛化效果更好
Batch Size:每次喂給模型多少資料
Batch Size(批次大小) 決定每次計算梯度時使用多少個訓練樣本。
三種極端情況:
Full Batch(批次 = 整個訓練集):
+ 梯度計算最準確(真實梯度)
+ 收斂路徑平滑
- 記憶體可能不夠(百萬筆資料裝不進 GPU)
- 每次更新需要遍歷所有資料,每個 Epoch 只能更新一次
Stochastic(批次 = 1 筆):
+ 每筆資料都能更新,更新頻繁
+ 梯度噪音有時能幫助跳出局部最優
- 梯度估計極不穩定,收斂路徑像醉漢走路
- GPU 並行效率極低(每次只算一筆太浪費)
Mini-Batch(批次 = 32、64、128...):
✓ 兼顧效率和梯度品質,現代深度學習的標配
✓ GPU 可以同時處理批次內所有樣本(高度並行)
✓ 梯度估計有適度的噪音(可視為正則化,有助泛化)
Batch Size 對訓練的影響(關鍵洞察):
| Batch Size | 梯度估計 | GPU 效率 | 泛化能力 | 需要的學習率 |
|---|---|---|---|---|
| 小(8–32) | 噪音大 | 低 | 往往更好 | 較小 |
| 中(64–256) | 適中 | 高 | 良好 | 中等 |
| 大(1024+) | 穩定 | 最高 | 有時下降 | 需線性放大(Linear Scaling Rule) |
為什麼小 Batch 有時泛化更好?
小 Batch 的梯度噪音讓優化路徑帶有隨機性,這種隨機性讓模型傾向於找到「平坦的」(Flat)最小值——損失函數地形上較寬廣的低谷。平坦的最小值在實際部署時對輸入的小變化更不敏感,泛化能力更強。大 Batch 訓練找到的往往是「尖銳的」(Sharp)最小值——很深但很窄的山谷,在訓練集上損失低,但稍微偏離就損失飆升,泛化能力較差。
應用場景
訓練過程的視覺化——看懂 Loss Curve
訓練日誌和損失曲線(Loss Curve)是模型訓練狀態的晴雨表。以下是台灣某醫療 AI 新創公司在訓練皮膚病變分類模型時的真實訓練紀錄分析:
Epoch 訓練損失 驗證損失 訓練準確率 驗證準確率
1 2.302 2.298 21.3% 20.8%
5 1.543 1.562 48.6% 47.1%
10 0.892 0.934 72.4% 70.1%
20 0.421 0.488 86.1% 83.7%
30 0.261 0.402 92.3% 87.2% ← 開始過擬合跡象
40 0.163 0.471 95.8% 86.4% ← 明顯過擬合
50 0.089 0.623 98.1% 84.0% ← 嚴重過擬合
讀取訓練曲線的方法:
Epoch 1–20:訓練損失和驗證損失同步下降,兩者差距小,模型在正常學習。
Epoch 30 開始:訓練損失繼續下降,但驗證損失開始上升,兩條曲線開始分叉——這是過擬合(Overfitting)的信號:模型開始「記住」訓練資料的特定細節,而非學習通用規律。
工程師的決策:在 Epoch 20 附近儲存模型(Early Stopping)。繼續訓練不會帶來更好的測試集效果,反而會讓模型越來越只會「背答案」。
診斷訓練問題的常見模式:
問題一:損失不降(兩條曲線都平坦)
→ 可能:學習率太小,梯度太小,模型容量不足,梯度消失
→ 解法:增大學習率,更換優化器,加深/加寬網路
問題二:損失劇烈震盪(上下劇烈波動)
→ 可能:學習率太大,Batch Size 太小,梯度爆炸(Gradient Explosion)
→ 解法:降低學習率,增加 Batch Size,加入 Gradient Clipping(梯度裁剪)
問題三:訓練損失極低但驗證損失高(兩條曲線分叉)
→ 過擬合。解法:Dropout、L2 正則化、Data Augmentation、提前停止
問題四:訓練損失和驗證損失都高(兩條曲線都在高位)
→ 欠擬合(Underfitting)。解法:加深模型、訓練更多 Epoch、降低正則化強度
常見誤區
誤區一:損失降低就等於模型變好
許多初學者把「訓練損失下降」等同於「模型越來越好」。但訓練損失只衡量模型在「已看過的資料」上的表現;真正重要的是驗證損失——在「沒看過的資料」上的表現。當訓練損失持續下降、但驗證損失開始上升,代表模型開始過擬合,此時繼續訓練反而讓模型越來越無用。正確的做法是同時監控訓練損失和驗證損失,以驗證損失作為早停(Early Stopping)的依據,儲存驗證損失最低時的模型參數,而非最終 Epoch 的參數。
誤區二:梯度下降一定能找到「全局最優解」(Global Optimum)
梯度下降是「局部搜尋」演算法——它根據當前位置的坡度往下走,但它看不到全局地形,可能卡在局部最低點(Local Minimum)或鞍點(Saddle Point)而非全局最優點。不過,在深度學習的實踐中,這個問題並不如理論上嚴重:深度神經網路的損失函數地形有大量的局部最優點,但研究發現這些局部最優點的損失值通常差異不大(都接近全局最優),且隨機梯度的噪音有助於跳出「品質差的」局部最優點。現代 LLM 的訓練通常在「足夠好的」局部最優點停下,而非等到真正的全局最優,但訓練結果仍然非常實用。追求全局最優是理論問題,實務上通常不必執著。
誤區三:Adam 永遠優於 SGD,不需要再用 SGD
Adam 在大多數深度學習任務(特別是 NLP、LLM)上確實是首選優化器,收斂更快、對學習率選擇不敏感。但在某些場景中,SGD + Momentum + 精細調整的學習率調度,反而能讓模型達到更好的泛化能力:這在 ImageNet 圖像分類競賽中已被多次驗證。原因在於 Adam 有時收斂到「尖銳的」局部最優點,而 SGD 的噪音引導更傾向找到泛化更好的「平坦」最優點。實務建議:先用 Adam 快速驗證模型可行性,若需要在特定資料集上榨出最後幾個百分點的準確率,可嘗試切換至 SGD + Momentum 並配合 Cosine Annealing 學習率調度。兩種優化器各有其最適用場景,而非有絕對的優劣之分。
小練習
練習一:診斷訓練問題
以下是某工程師訓練一個台灣電商評論情感分析模型(正面/負面分類)時記錄的訓練日誌:
設定:學習率 = 0.1,Batch Size = 32,Adam 優化器
訓練資料:10 萬筆評論
Epoch 訓練損失 驗證損失
1 0.693 0.691 (基線:隨機猜測的交叉熵約為 ln(2) ≈ 0.693)
10 0.682 0.685
30 0.678 0.681
100 0.671 0.674 ← 100 個 Epoch 後,損失幾乎沒有下降
請回答:
- 這個訓練日誌顯示了什麼問題?
- 提出至少三個可能的原因。
- 如果是「學習率問題」,損失曲線通常看起來如何?
- 建議下一步如何診斷和修復?
看解答
**問題 1:訓練日誌的問題診斷** 這是典型的**欠擬合(Underfitting)/ 訓練不收斂**情況: 100 個 Epoch 後,損失仍接近隨機猜測的基線(0.693)。正常的二元分類訓練,在 10 萬筆資料上應該能在 10–20 個 Epoch 內將訓練損失降到 0.3 以下。此模型幾乎沒有在學習任何有用的規律。 **問題 2:可能的原因(至少三個)** **原因一:學習率異常** 學習率 0.1 配合 Adam 優化器**非常大**(Adam 的推薦學習率通常是 1e-3 到 3e-4,即 0.001 到 0.0003)。學習率 0.1 可能讓參數更新過大,在最優點附近劇烈震盪,看起來損失不降反而穩定在高位(因為每次步伐太大都跳過去了)。 **原因二:資料問題——標籤錯誤或不平衡** 若訓練資料中正面/負面標籤嚴重不平衡(如 95% 正面,5% 負面),或標籤本身有大量錯誤(人工標記品質差),模型可能學到「永遠猜多數類別」的策略,損失一直維持在不平衡資料的基線附近。 **原因三:模型容量問題——架構太簡單** 若使用過於簡單的架構(如只有一個隱藏層的 MLP)處理電商評論這種需要語意理解的任務,模型可能根本沒有足夠的表達能力捕捉情感特徵,不管怎麼訓練都學不到有用的規律。 **其他可能原因:** - **特徵工程問題**:輸入的文字表示方式不對(如 one-hot 詞袋模型沒有語意資訊) - **梯度消失**:若網路很深且沒有適當的正規化(Batch Normalization、殘差連接),梯度可能根本沒有傳到早期層 - **資料前處理錯誤**:如繁體中文沒有正確切詞,或 tokenizer 設定錯誤 **問題 3:學習率問題的損失曲線特徵** - **學習率太大**:損失在最初幾個 Epoch 可能先急速下降,然後開始劇烈震盪(上下起伏大),或直接在初始損失附近停滯不動甚至上升(發散) - **學習率太小(另一種情況)**:損失會下降,但極其緩慢,斜率幾乎為零,需要幾千個 Epoch 才能到達合理的損失值 本題的情況(損失幾乎不動而非震盪)更像是學習率太大導致在高損失區域震盪,或者是資料/架構問題。 **問題 4:診斷和修復步驟** 第一步:**降低學習率**,從 0.1 改為 3e-4(0.0003),這是 Adam 的推薦起始學習率,訓練 30 個 Epoch 觀察是否有改善。 第二步:**檢查資料**。隨機抽樣 100 筆訓練資料,人工核實標籤是否正確;計算正負面樣本比例,若嚴重不平衡則採用類別加權損失(Class-Weighted Loss)。 第三步:**確認模型能過擬合一個小資料集**。取 100 筆訓練資料,強制讓模型過擬合(訓練損失趨近 0)。若模型連 100 筆也學不起來,說明架構或實作有根本問題。若能過擬合,說明架構 OK,問題在資料量或正則化設定。 第四步:**考慮使用預訓練模型**。對於中文情感分析,從 BERT(如 bert-base-chinese)開始微調,遠比從頭訓練效率更高,且準確率通常也更好。練習二:優化器和 Batch Size 的選擇
你正在為台灣某連鎖便利商店的庫存管理系統訓練一個銷售預測模型。目標是預測未來 7 天每個商品的每日銷售量(回歸任務)。
訓練設定:
- 訓練資料:全台 6,000 家門市,過去 5 年,共約 1 億筆每日商品銷售紀錄
- 模型:LSTM + 全連接層,總參數量約 500 萬
- 硬體:4 張 NVIDIA V100(16GB VRAM 各),可以使用資料並行(Data Parallel)
請回答以下問題:
- 應選擇 SGD 還是 Adam 作為優化器?理由是什麼?
- Batch Size 應該怎麼設定?考量因素有哪些?
- 損失函數應選 MSE 還是交叉熵?
- 若你的同事說「我把 Batch Size 從 64 加大到 2048,訓練速度提升了 10 倍,但驗證集 MSE 卻比原來差了 15%」,請解釋原因並提出一個可能的修復方案。