M04.07|遷移學習:站在巨人的肩膀上
不用從零開始 — 用別人訓練好的模型當基底,再微調成你的專家
本講學習重點
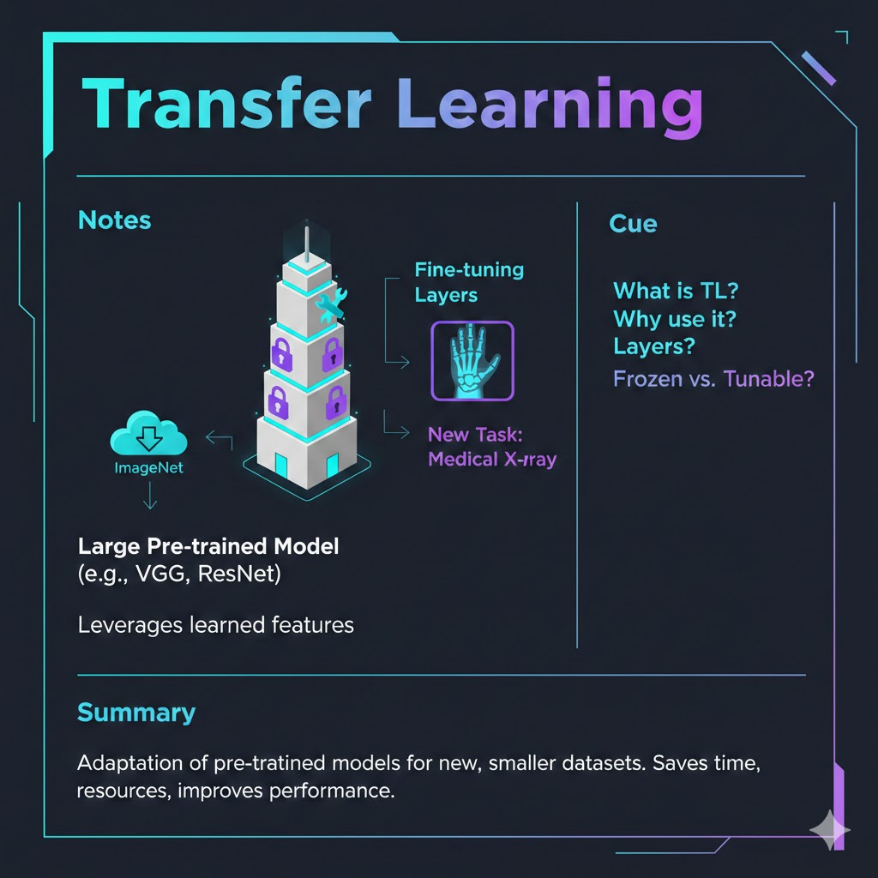
遷移學習(Transfer Learning):把在大型資料集上訓練好的模型作為起點, 遷移到新任務或新領域,而非從隨機初始化的權重開始。 預訓練模型學到的通用知識: - 視覺模型(ImageNet 預訓練):邊緣、紋理、形狀、物件部位等視覺特徵 - 語言模型(BERT、GPT):語法結構、語意關係、世界知識、推理能力 三種主要策略: 1. 特徵提取(Feature Extraction): 凍結所有預訓練層,只訓練新加的分類頭;適合資料極少的場景 2. 部分微調(Partial Fine-tuning): 凍結底層(通用特徵),解凍頂層(任務特定特徵),再訓練 3. 全量微調(Full Fine-tuning): 解凍所有層,用較小的學習率整體更新;適合目標資料集較大且與預訓練資料有差異 層級特徵的直覺: - CNN 底層:邊緣、角點等低階特徵(高度通用) - CNN 中層:紋理、形狀組合(較通用) - CNN 頂層:任務特定的高階語意特徵(需要微調) 學習率設定的關鍵原則: - 微調時學習率應遠小於從頭訓練(通常小 10–100 倍) - 常用「差異化學習率(Discriminative Learning Rates)」: 底層用更小的學習率,頂層用稍大的學習率 領域適應(Domain Adaptation): - 資料分布不同(如自然圖像 → 醫療影像),需要適應 - 常見手段:領域對抗訓練、漸進式解凍、大量資料增強
🎙️ Podcast(中文)
一句話搞懂
遷移學習就像聘用一位已在大醫院工作過十年的醫師來開家診所:他的解剖學知識、診斷邏輯、臨床直覺全部帶過來,你只需要讓他用幾個月的時間熟悉你診所的特殊病人群體和工作流程,而不是重新培訓一位從未見過病人的醫學院畢業生。
白話解說
從零訓練:為什麼代價驚人
要訓練一個有競爭力的深度學習模型,代價有多高?以幾個公開的案例估算:
GPT-3(1750 億參數):
訓練資料:3,000 億 tokens(約 570GB 純文字)
計算成本:約 460 萬 GPU-小時(A100 GPU)
電費估算:約 120 萬美元
碳排放:約 552 噸 CO₂(等同於 120 輛汽車行駛一年)
ResNet-50(2,500 萬參數,ImageNet 預訓練):
訓練資料:ImageNet 約 120 萬張標注圖片
計算時間:4 張 V100 GPU 約 3 天
工程成本:標注 120 萬張圖片需要大量人力
對台灣的中小型企業或研究機構而言,「擁有」這樣規模的資料集和算力幾乎是不可能的。即便是台灣的大型上市公司,要獨立訓練一個 ImageNet 規模的視覺模型或 BERT 規模的語言模型,成本也難以負擔。
而且,從零訓練還有另一個更根本的問題:
大多數企業的專業領域資料量非常有限。一家醫院的 X 光影像資料庫可能有數萬張,但 ImageNet 規模的模型需要百萬量級的資料才能穩定訓練。資料量不足時,從頭訓練的模型往往過擬合嚴重,泛化能力很差。
預訓練模型:凝固的通用知識
預訓練模型(Pre-trained Model)是在大規模、通用資料集上已完成訓練的神經網路,它的權重中凝固了大量可遷移的通用知識。
視覺預訓練模型(如 ResNet、ViT)學到了什麼?
可視化 CNN 各層的濾波器,可以看到不同深度的層學到了截然不同的特徵:
底層(第 1–5 層):通用低階視覺特徵
┌──────────────────────────────────┐
│ // 邊緣(水平、垂直、斜向) │
│ ○ 圓弧、曲線 │
│ ▓ 色塊、漸層紋理 │
└──────────────────────────────────┘
→ 這些特徵在自然界中普遍存在,
對所有視覺任務都有用。
中層(第 6–30 層):通用中階視覺特徵
┌──────────────────────────────────┐
│ 幾何形狀組合(三角形、矩形) │
│ 材質紋理(毛皮、布料、金屬) │
│ 局部結構(眼睛形狀、車輪輪廓) │
└──────────────────────────────────┘
→ 較通用,但開始帶有 ImageNet 任務的偏向。
頂層(最後幾層):任務特定高階語意特徵
┌──────────────────────────────────┐
│ 「這是狗臉」「這是汽車前方」 │
│ 「這是鳥羽毛」「這是食物盤子」 │
└──────────────────────────────────┘
→ 高度任務特定,遷移到醫療影像時需要替換。
語言預訓練模型(如 BERT、GPT)學到了什麼?
語言模型預訓練後,它的參數中隱含著:
- 語法知識:主謂賓結構、時態一致性、句子邊界
- 語意知識:詞語間的語意關係(近義詞、反義詞、上下位詞)
- 世界知識:「台積電是台灣的公司」「太陽從東方升起」等事實
- 推理能力:「A 比 B 大,B 比 C 大,所以 A 比 C 大」之類的基礎推理
這些知識來自模型見過的數千億個文字 token,人類窮極一生也無法讀遍。把這些知識帶入下游任務,是遷移學習最核心的價值。
微調策略:凍結與解凍的藝術
遷移學習有三種主要策略,選擇哪種取決於你的資料量和目標領域與預訓練領域的差距。
策略一:特徵提取(Feature Extraction)
做法:完全凍結預訓練模型的所有層,只在頂端加上新的分類頭(Classification Head),只訓練這個新加的部分。
預訓練模型(全部凍結,權重不更新)
├── 底層:邊緣特徵 [凍結 ❄️]
├── 中層:紋理特徵 [凍結 ❄️]
├── 頂層:高階特徵 [凍結 ❄️]
│
└── 新加的分類頭(只訓練這裡)
├── 全連接層(隱藏層)[訓練 🔥]
└── 輸出層(新任務的類別數)[訓練 🔥]
適用情境:資料量極少(幾百到幾千張/筆),且目標領域和預訓練領域相似(如 ImageNet 預訓練用於商品圖片分類)。
優點:訓練速度快,不容易過擬合,即使 GPU 規格很弱也可以完成。
缺點:若目標領域與預訓練領域差異大(如把 ImageNet 模型直接用於醫療病理切片),頂層特徵可能不夠相關,效果有限。
策略二:部分微調(Partial Fine-tuning)
做法:凍結預訓練模型的底層(保留通用特徵),解凍頂層(允許更新任務特定特徵),配合新的分類頭一起訓練。
預訓練模型
├── 底層:邊緣特徵 [凍結 ❄️] ← 普遍適用,不需要改
├── 中層:紋理特徵 [凍結 ❄️] ← 通常也保留
├── 頂層:高階特徵 [微調 🔥] ← 讓模型適應新任務
│
└── 新加的分類頭(訓練 🔥)
學習率設定:微調時,整體學習率要遠小於從頭訓練(通常是 1/10 到 1/100)。這是因為預訓練模型的權重已經在很「好」的地方,大幅更新會破壞已學到的知識(稱為「災難性遺忘,Catastrophic Forgetting」)。
差異化學習率(Discriminative Learning Rates):
底層(凍結):學習率 = 0
中層(如果解凍):學習率 = 1e-5(極小)
頂層(解凍):學習率 = 1e-4
新分類頭:學習率 = 1e-3(較大,因為是全新參數)
策略三:全量微調(Full Fine-tuning)
做法:解凍所有層,用小學習率讓整個模型在目標任務的資料上繼續訓練。
適用情境:
- 目標資料量足夠多(至少數萬筆有標籤資料)
- 目標領域和預訓練領域差異較大(如自然語言模型微調到繁體中文法律文件)
BERT 系列的標準微調流程:
# 概念示意(非完整程式碼)
from transformers import BertForSequenceClassification, AdamW
# 載入預訓練 BERT(已包含 ImageNet/Wikipedia 等大型資料的知識)
model = BertForSequenceClassification.from_pretrained(
"bert-base-chinese", # 中文 BERT,適合台灣繁體中文任務
num_labels=2 # 新任務:二元分類(如正面/負面評論)
)
# 全量微調:所有參數都會更新
# 學習率遠小於從頭訓練(2e-5 vs 通常的 3e-4)
optimizer = AdamW(model.parameters(), lr=2e-5)
# 訓練數個 Epoch(通常只需要 3–5 個 Epoch,而非從頭訓練的數十個)
for epoch in range(3):
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
領域適應:當資料分布不同
領域適應(Domain Adaptation) 是遷移學習中最具挑戰性的場景:預訓練資料(來源域,Source Domain)和目標資料(目標域,Target Domain)在統計分布上有明顯差異。
最典型的例子就是自然圖像 → 醫療影像:
ImageNet 訓練資料(來源域):
├── 自然光照條件下的 RGB 彩色照片
├── 多樣的場景(戶外、室內、動物、植物)
└── 每個類別有清晰、直覺的外觀差異
醫療 X 光影像(目標域):
├── 灰階影像(不是 RGB 彩色)
├── 解剖結構(肋骨、肺野、縱膈腔)
└── 病灶(腫瘤、結節)可能極小且不明顯
領域差距帶來的問題:ImageNet 預訓練模型的頂層特徵(「這是狗臉」「這是汽車」)與醫療影像任務完全不相關,直接套用效果很差。
常見的領域適應策略:
漸進式解凍(Gradual Unfreezing):先只訓練新分類頭幾個 Epoch,讓分類頭先找到方向;再解凍最頂層微調;再逐漸往下解凍中層、底層。這樣的「溫水煮青蛙」方式能夠減少災難性遺忘。
資料增強(Data Augmentation):醫療影像常見增強手段包括隨機旋轉(影像在旋轉後仍具有醫學意義)、亮度/對比度調整、彈性形變(模擬組織形態變異)。豐富的增強讓有限的醫療影像資料發揮更大的訓練效益。
中間域預訓練(Intermediate Domain Pre-training):若有大量無標籤的醫療影像,可以先在這些無標籤影像上做自監督學習(Self-supervised Learning,如 MAE、SimCLR),讓模型先適應醫療影像的視覺分布,再在有標籤的資料上做監督微調。
應用場景
台灣醫療影像的遷移學習實踐
台灣某大學附屬醫院的放射科與 AI 研究團隊,要開發一個「肺結節偵測輔助系統」:輸入低劑量肺部 CT 掃描,自動標記疑似肺結節的位置,輔助放射科醫師閱片。
挑戰:
- 有標籤的肺結節 CT 影像:約 2,800 筆(含影像科醫師的結節標注)
- 無標籤的肺部 CT 影像:約 15,000 筆(醫院既有的存檔掃描)
- 目標:偵測準確率(Sensitivity)超過 90%,假陽性率低於 3 個/CT
從零訓練的結果(基準):
僅用 2,800 筆標注資料從零訓練 ResNet-50:
Sensitivity(敏感度):71.3%
Specificity(特異度):88.2%
假陽性率:約 6.8 個/CT
結論:無法達到臨床使用標準
遷移學習方案一:ImageNet 預訓練 + 直接微調
起點:ImageNet 預訓練的 ResNet-50
策略:凍結底層 3/5,解凍頂層 2/5 + 新分類頭
訓練資料:2,800 筆標注 CT 影像
學習率:1e-4(頂層)/ 1e-5(中層)
結果:
Sensitivity:82.6%(提升 11.3 個百分點)
Specificity:91.4%
假陽性率:約 4.1 個/CT
結論:有所改善,但仍未達標
遷移學習方案二:中間域預訓練 + 微調
第一階段:在 15,000 筆無標籤肺部 CT 上做自監督預訓練(MAE 遮罩自編碼)
→ 模型先學會「理解 CT 影像的分布」(無需標注,自動進行)
→ 耗時約 2 天(8 張 A100 GPU)
第二階段:用 2,800 筆標注資料做全量微調
→ 耗時約 6 小時
結果:
Sensitivity:91.8%(超過臨床目標 90%)
Specificity:94.1%
假陽性率:約 2.3 個/CT(低於目標 3 個)
結論:通過臨床評估,進入試點部署
關鍵洞察:中間域預訓練(在無標籤的醫療影像上)帶來的收益遠大於直接用 ImageNet 微調,因為模型先適應了 CT 影像的視覺分布(灰階值範圍、Hounsfield 單位、噪點特性),再學習結節識別任務時事半功倍。這個方案讓醫院只需 15,000 筆無標籤影像(無需請醫師標注)和 2,800 筆有標籤影像,就達到了通常需要十萬筆標注資料才能達到的效果。
常見誤區
誤區一:遷移學習只適合圖像任務
很多工程師把遷移學習等同於「ImageNet 預訓練 + 微調 CNN」,以為這是電腦視覺專屬技術。實際上,遷移學習在自然語言處理(NLP)的影響同樣深遠——甚至可以說,現代 NLP 的核心正是遷移學習。BERT 的「預訓練-微調」框架徹底改變了 NLP 的開發方式:現在幾乎所有 NLP 任務(情感分析、命名實體識別、問答、文件分類)都從 BERT 或其變體出發做微調,而非從頭訓練。同樣地,強化學習、語音辨識、蛋白質結構預測(AlphaFold)也都大量應用遷移學習。遷移學習是現代 AI 開發的通用方法論,不限於任何單一模態。
誤區二:微調時解凍越多層效果越好
直覺上「解凍更多層 = 讓更多參數適應新任務 = 效果更好」,但這個邏輯並不總是成立。當目標資料量很小(如只有幾百筆)、且解凍太多層時,模型很容易「過擬合」——把預訓練學到的通用知識「忘掉」,轉而記住這幾百筆訓練樣本的具體細節。正確做法是根據資料量動態調整解凍策略:資料量少就凍結更多層(甚至全凍結只訓練分類頭),資料量多才逐步解凍更多層甚至全量微調。解凍策略應由驗證集的表現決定,而非憑直覺固定。
誤區三:預訓練的資料域越接近目標域越好,所以要找「同領域」的預訓練模型
這個直覺通常是對的,但有一個重要的反例:在資料量非常少的情況下,用超大規模的「通用」預訓練模型(如 ImageNet 21k 的 ViT-L,或 GPT-4 規模的語言模型)微調,往往比用小規模的「領域特定」預訓練模型效果更好。原因是:超大型通用模型學到了極其豐富的特徵表示,即使領域不完全匹配,其強大的特徵提取能力也能彌補領域差距;而小型領域模型雖然領域匹配,但特徵表示能力有限。實務建議:優先嘗試公開可用的大型通用模型(如 HuggingFace 上的 bert-large、microsoft/BiomedNLP-PubMedBERT 等),再評估是否需要領域特定模型。
小練習
練習一:選擇微調策略
一家台灣的工業製造廠商要開發「PCB 電路板瑕疵偵測系統」。系統需要偵測出錫橋(Solder Bridge)、銲球缺失(Missing Solder Ball)、元件偏移(Component Misalignment)三種瑕疵。工廠已收集了以下資料:
| 瑕疵類型 | 有標注的瑕疵圖片 | 無標注的良品圖片 |
|---|---|---|
| 錫橋 | 450 張 | — |
| 銲球缺失 | 280 張 | — |
| 元件偏移 | 610 張 | — |
| 無瑕疵(良品) | 2,000 張 | 50,000 張 |
預算:AWS EC2 g4dn.xlarge(1 張 T4 GPU)可用 72 小時。
請問:
- 應該選擇哪種微調策略(特徵提取、部分微調、全量微調)?理由是什麼?
- 50,000 張無標注的良品圖片可以如何利用?
- 若三個月後瑕疵類型新增了「印刷偏移(Print Offset)」,有 200 張標注圖片,如何在現有模型上更新?
看解答
**問題 1:微調策略選擇** **推薦策略:部分微調(Partial Fine-tuning)**,凍結預訓練模型底層 50–70%,解凍頂層 30–50% 加上新的分類頭。 理由: - 有標注資料量偏少(錫橋 450 張、銲球缺失僅 280 張),若全量微調容易過擬合,若完全凍結(只做特徵提取)則對製造業的特殊外觀(PCB 銲點形態、電路板紋理)適應不足。 - 預訓練模型(如 ImageNet 的 ResNet-50)底層已學會邊緣、紋理等通用特徵,這些在 PCB 圖片中仍然有用;頂層學的是 ImageNet 物件語意(「這是貓」),與 PCB 瑕疵毫無關係,必須解凍重訓。 - 資源有限(T4 GPU,72 小時),部分微調比全量微調節省計算和記憶體,在此約束下更可行。 **具體設定建議**: ``` 起點:ImageNet 預訓練的 EfficientNet-B4(效能和速度均衡) 凍結:底層 60%(Stem + Blocks 1–4) 解凍:頂層 40%(Blocks 5–7)+ 新的 4 分類頭(3 種瑕疵 + 1 種良品) 學習率: 底層(若解凍):1e-5 頂層:5e-5 分類頭:2e-4 Batch Size:32 訓練 Epoch:20(搭配 Early Stopping,驗證集監控 F1 分數) ``` **問題 2:50,000 張無標注良品圖片的用途** 這些無標注圖片非常有價值,可以用於: **用途一:中間域預訓練(自監督學習)** 在 50,000 張無標注的 PCB 圖片上,先做自監督預訓練(如 SimCLR 對比學習或 MAE 遮罩自動編碼),讓模型先學習 PCB 影像的視覺特徵分布(銲點形狀、電路板紋理、光照條件),再用有標注的瑕疵圖片做監督微調。這通常能顯著提升最終的偵測準確率,效益遠超直接從 ImageNet 模型微調。 **用途二:測試時的異常偵測補充** 訓練一個「正常品」的自編碼器(Autoencoder)或 One-Class Classification 模型,學習良品圖片的重建分布。在推論時,如果輸入圖片的重建誤差高(超出正常品的誤差範圍),就觸發「疑似瑕疵」警報,輔助瑕疵分類器。 **用途三:資料增強的基礎** 從良品圖片中學習正常的背景和光照條件,用於合成訓練資料(如把瑕疵貼合到不同背景的良品圖片上),擴充有標注訓練資料的多樣性。 **問題 3:新增瑕疵類型的更新策略** 面對新類別「印刷偏移」(200 張標注圖片),直接重新訓練整個模型(包含原有三種瑕疵的資料)成本高,且舊資料可能已難以重新收集。 **推薦方案:增量微調(Incremental Fine-tuning)+ 資料混合** 步驟一:保留原有模型權重,把輸出層擴充為 5 個類別(3 種原有瑕疵 + 良品 + 印刷偏移)。 步驟二:從原有三種瑕疵資料中各隨機抽取 200 張(與新類別資料量對齊),與 200 張印刷偏移圖片混合,共 1,000 張,進行增量微調。 步驟三:只解凍最頂層的幾層 + 新分類頭,其他層保持凍結(防止「災難性遺忘」舊知識)。 這樣的「資料混合 + 選擇性解凍」策略能在保留舊類別識別能力的同時,有效學習新類別,不需要從頭重訓整個模型。練習二:評估遷移學習效果
你的團隊在台灣某法律科技公司開發「法庭裁判書情感分析系統」,對裁判書中每個段落進行分類(原告有利 / 被告有利 / 中立陳述)。你嘗試了三種方案,得到以下驗證集結果:
| 方案 | 起點 | 策略 | 驗證集 Accuracy | 驗證集 F1(Macro) |
|---|---|---|---|---|
| A | 隨機初始化 | 從頭訓練 LSTM | 68.4% | 0.612 |
| B | bert-base-chinese | 特徵提取(完全凍結) | 79.1% | 0.754 |
| C | bert-base-chinese | 全量微調 | 87.3% | 0.861 |
| D | LEGAL-BERT(法律領域) | 全量微調 | 89.8% | 0.883 |
請回答:
- 從 A→B→C→D 的效果提升,分別說明哪個改變帶來了哪個提升?
- 如果客戶說「我們只有 500 筆有標注裁判書,方案 C 的驗證集表現可信嗎?有沒有過擬合風險?」請分析並提出建議。
- 如果 LEGAL-BERT 是一個英文法律領域的模型,你怎麼評估它是否適合用於繁體中文裁判書?