M04.08|GPU 與深度學習硬體:為什麼訓練 AI 需要顯示卡
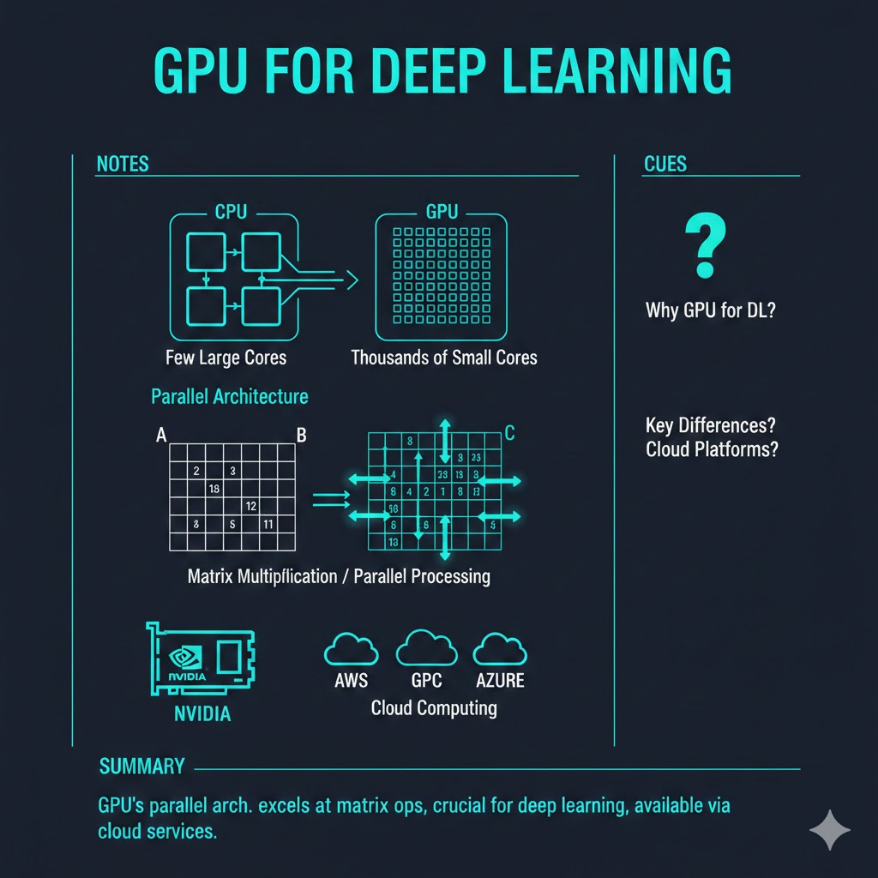
CPU 是全才教授,GPU 是千人工廠 — 矩陣運算要的是人海戰術
本講學習重點
CPU vs GPU 核心差異: - CPU:少量高性能核心(4–64 核),擅長複雜邏輯分支、串行任務、低延遲 - GPU:大量中低性能核心(數千到數萬個 CUDA Core),擅長同時執行大量相同運算 矩陣乘法與 GPU 的完美搭配: - 矩陣乘法(C = AB):每個輸出元素 c_ij 的計算完全獨立 - 獨立性 = 可以同時並行計算,正是 GPU 的強項 - 深度學習的前向傳播、反向傳播本質上都是矩陣乘法的組合 NVIDIA 生態系: - CUDA(Compute Unified Device Architecture):GPU 通用運算平台,2006 年推出 - cuDNN(CUDA Deep Neural Network library):針對深度學習優化的高效核函數 - 深度學習框架(PyTorch/TensorFlow)→ 呼叫 cuDNN → 呼叫 CUDA → 執行於 GPU 硬體 GPU 記憶體(VRAM)是關鍵瓶頸: - 模型參數(權重)+ 梯度 + 優化器狀態 + Batch 資料 都要放在 VRAM - 典型需求:1B 參數模型,float32 訓練大約需要 16GB VRAM - 消費級:RTX 4090(24GB)、RTX 3090(24GB) - 專業級:A100(40GB/80GB)、H100(80GB) 雲端選擇: - AWS:p3(V100)、p4d(A100)、g4dn(T4,性價比高) - GCP:A100、H100、TPU v4(適合 TensorFlow) - Azure:NC 系列(T4/V100) 其他硬體: - TPU:Google 自研,矩陣乘法極快,但只支援 JAX/TensorFlow,生態較封閉 - Apple Silicon(M 系列):CPU/GPU/Neural Engine 共享統一記憶體,省空間, MPS 後端支援 PyTorch,適合本地推論但不適合大規模訓練
🎙️ Podcast(中文)
一句話搞懂
深度學習訓練的核心運算是矩陣乘法,矩陣乘法的每個輸出元素可以完全獨立計算,GPU 的數千個核心正好可以同時並行處理這些獨立計算——就像工廠流水線同時生產數千個零件,遠比一位全才工程師逐一生產來得快。
白話解說
CPU vs GPU:思考方式根本不同
要理解為什麼深度學習需要 GPU,必須先了解 CPU 和 GPU 在設計哲學上的根本差異。
CPU(Central Processing Unit)——全才教授
CPU 被設計為「通用計算」的核心。它需要能夠處理各種複雜的邏輯:作業系統的任務排程、資料庫的索引查詢、網頁伺服器的 HTTP 請求處理、視訊播放的解碼……每種工作的特性截然不同,CPU 必須應付所有這些場景。
為了做到這一點,CPU 的設計重點是「讓每一個核心都盡可能快」:
- 高時脈頻率(3–5 GHz)
- 大量快取記憶體(L1/L2/L3 Cache)加速資料存取
- 分支預測、超執行緒、亂序執行等複雜電路,讓串行代碼跑得更快
- 核心數相對少(消費級 4–24 核,伺服器級最多 128 核)
一個核心的比喻:CPU 的每個核心是一位經驗豐富的教授,能獨立解決複雜的問題,每秒可以處理數十億個多步驟的複雜指令。
GPU(Graphics Processing Unit)——千人流水線工廠
GPU 最初是為了處理遊戲圖形而設計的。在 3D 遊戲渲染時,需要對螢幕上的每個像素同時做幾乎相同的計算(著色、光照計算),這是「大量相同、相互獨立的計算」。
GPU 的設計哲學是「讓數千個核心同時工作」:
- 核心數極多(RTX 4090 有 16,384 個 CUDA Core)
- 每個核心的個別性能遠低於 CPU 核心(時脈頻率低、快取小、邏輯簡單)
- 但數千個核心可以完全同步地、並行地執行同一個操作
任務:把 1,000 個數字各自乘以 2
CPU(8 核)的做法:
核心 1 處理第 1–125 個數字(串行)
核心 2 處理第 126–250 個數字(串行)
...
核心 8 處理第 876–1000 個數字(串行)
需要 1000/8 = 125 個「步驟」
GPU(1000 個 CUDA Core)的做法:
同時啟動 1000 個 CUDA Core,每個 Core 只處理一個數字
全部 1000 個乘法在同一個「步驟」完成
需要 1 個「步驟」
關鍵限制:GPU 的這種優勢只在「大量相同、相互獨立的計算」時才能發揮。如果任務有複雜的條件分支(if-else 邏輯)、前一步的結果影響下一步的計算(串行依賴),GPU 的優勢就大幅縮減,有時甚至不如 CPU。
為什麼矩陣乘法天生適合 GPU
深度學習的本質運算是矩陣乘法(Matrix Multiplication)。
神經網路的前向傳播,無論多複雜,在數學上都可以分解為: 「輸入向量/矩陣 × 權重矩陣 + 偏差向量,通過激活函數,重複 N 層」
矩陣乘法的計算特性:
考慮一個簡單的矩陣乘法 C = A × B,其中 A 是 m×k 矩陣,B 是 k×n 矩陣,C 是 m×n 矩陣:
c_ij = 第 i 行的 a_i1, a_i2, ..., a_ik
與第 j 列的 b_1j, b_2j, ..., b_kj 的內積
c_11 c_12 ... c_1n 每一個 c_ij 的計算
c_21 c_22 ... c_2n ← 完全獨立,互不影響!
...
c_m1 c_m2 ... c_mn → 所有 m×n 個輸出元素可以同時並行計算
如果 m=1024, n=1024,那麼有 1,048,576 個輸出元素可以同時並行計算。RTX 4090 的 16,384 個 CUDA Core 可以在幾個「波次」內完成整個矩陣乘法,而 CPU 串行計算同樣的矩陣乘法可能需要數百倍的時間。
深度學習的計算量有多龐大?
GPT-3(1750 億參數)一次前向傳播(推論)的矩陣乘法數量估算:
96 個 Transformer Block
每個 Block 的 Self-Attention:多次 768×768 等規模矩陣乘法
每個 Block 的 Feed-Forward Network:768×3072 的矩陣乘法
總計:約 3.5 × 10^23 次浮點運算(FLOP)
比較:
RTX 4090 的運算能力:~82.6 TFLOPS(fp16)= 8.26 × 10^13 次/秒
訓練 GPT-3 在 A100 GPU 上估計需要 355 GPU 年
→ OpenAI 使用 1,024 張 A100 連續訓練約 34 天(並行計算)
這個數字說明了為什麼深度學習必須依靠 GPU 的並行計算能力:沒有 GPU,訓練大型模型在工程上完全不可行。
NVIDIA 的生態系:CUDA 和 cuDNN
NVIDIA 的主導地位不僅在於其 GPU 硬體性能,更在於它構建了一套幾乎無法繞開的軟體生態系。
CUDA(Compute Unified Device Architecture)
CUDA 是 NVIDIA 在 2006 年推出的 GPU 通用運算平台,它讓開發者不需要學習圖形學知識,就能用類 C/C++ 語言(CUDA C)撰寫在 GPU 上並行執行的程式(稱為 Kernel)。
傳統 GPU 使用流程(CUDA 之前):
想用 GPU 算矩陣乘法?→ 必須偽裝成「渲染材質貼圖」的計算
→ 極度麻煩,只有圖形學專家能用
CUDA 之後:
撰寫普通的 C 函數,加上 __global__ 關鍵字宣告為 GPU Kernel
呼叫時指定執行緒格(Thread Grid)和執行緒塊(Thread Block)的尺寸
CUDA 自動排程到 GPU 上並行執行
→ 所有人都能用 GPU 做通用運算
cuDNN(CUDA Deep Neural Network library)
cuDNN 是 NVIDIA 在 CUDA 之上提供的高階函式庫,針對深度學習的核心運算做了極致的優化:
- 卷積計算(Conv2D)的多種高效演算法(Winograd、FFT、implicit GEMM)
- 批次正規化(Batch Normalization)的融合運算
- 各種激活函數(ReLU、GELU、Sigmoid)的 GPU 最佳化實作
- RNN/LSTM 的高效 GPU 實作
- Transformer 中的 Multi-Head Attention 融合核心
深度學習計算的呼叫鏈:
PyTorch / TensorFlow 代碼(Python)
↓ 調用
cuDNN(C/C++,高度優化的深度學習核心函數)
↓ 調用
CUDA(GPU 通用運算 API)
↓ 執行於
NVIDIA GPU 硬體(CUDA Core / Tensor Core)
每一層都對上層隱藏了下層的複雜性。
工程師只需要寫 PyTorch 代碼,CUDA 和 cuDNN 自動處理所有 GPU 細節。
Tensor Core:矩陣乘法的專用加速電路
從 Volta 架構(2017 年)開始,NVIDIA 在 GPU 中加入了 Tensor Core,這是專門為矩陣乘法設計的硬體電路,比 CUDA Core 更快執行混合精度(FP16/BF16/INT8)的矩陣乘法。
RTX 4090(Ada Lovelace 架構)的計算能力:
CUDA Core(FP32):82.6 TFLOPS
Tensor Core(FP16 稀疏):1,321 TOPS
Tensor Core 在深度學習訓練/推論中的加速比:
相同精度任務:約快 4–8 倍(比純 CUDA Core)
混合精度訓練(AMP):約快 2–4 倍(因為部分運算仍需 FP32)
為什麼難以擺脫 NVIDIA 生態?
CUDA 生態的護城河非常深:20 年的積累讓幾乎所有深度學習框架(PyTorch、TensorFlow、JAX)的底層優化都依賴 CUDA/cuDNN;大量研究代碼假設 NVIDIA GPU 的存在;除錯工具(Nsight)、性能分析工具(nvprof)也都是 NVIDIA 獨有的。AMD 的 ROCm 和 Intel 的 OneAPI 雖然在追趕,但截至 2026 年,生態成熟度仍與 NVIDIA 有顯著差距。
GPU 規格的關鍵指標
選購 GPU 做深度學習,不是只看「CUDA Core 數量」那麼簡單,以下幾個指標同等重要:
VRAM(顯示記憶體)——最常見的瓶頸
深度學習訓練時,GPU 顯示記憶體(VRAM)需要同時儲存:
VRAM 佔用 = 模型參數 + 梯度 + 優化器狀態 + 啟動值 + 批次資料
以 FP32 訓練 1B 參數模型為例:
模型參數:1B × 4 bytes = 4 GB
梯度:4 GB(同參數量)
Adam 優化器狀態(m, v):8 GB(兩倍參數量)
啟動值:視架構和 Batch Size 而定(約 2–8 GB)
合計:約 18–24 GB VRAM
記憶體頻寬(Memory Bandwidth)
GPU 計算速度很快,但如果從 VRAM 讀取資料的速度跟不上計算速度,GPU 就會「飢餓等待」,記憶體頻寬成為瓶頸。
常見 GPU 的記憶體頻寬比較:
RTX 4090:1,008 GB/s
A100(HBM2e 80GB 版):2,039 GB/s(約 2 倍)
H100(HBM3):3,350 GB/s(約 3.3 倍)
→ 這也是為什麼 A100/H100 訓練大型模型時效能遠超消費級 GPU,
不只是 TFLOPS 的差距,更是記憶體頻寬的差距。
NVLink(多 GPU 互聯)
單張 GPU 的 VRAM 不夠用時,需要多張 GPU 並行訓練。GPU 之間的通訊速度至關重要:
- PCIe 連接(消費級):~32 GB/s 雙向頻寬
- NVLink 3.0(A100):~600 GB/s 雙向頻寬(約 19 倍)
- NVSwitch(DGX 系統,8 張 A100):~4.8 TB/s 全交換
消費級 GPU(RTX 4090)沒有 NVLink,多卡訓練只能透過較慢的 PCIe,在需要頻繁同步梯度的訓練場景中效率大打折扣。
雲端 GPU 選擇:AWS、GCP、Azure
對大多數台灣企業而言,自建 GPU 伺服器成本高、維護複雜,雲端 GPU 是更靈活的選擇。
主要雲端平台的 GPU 選項(2026 年初的參考規格):
| 雲端平台 | 實例類型 | GPU | VRAM | 適用場景 |
|---|---|---|---|---|
| AWS | g4dn.xlarge | T4(1張) | 16 GB | 推論、小型微調 |
| AWS | p3.2xlarge | V100(1張) | 16 GB | 中型訓練 |
| AWS | p4d.24xlarge | A100(8張) | 320 GB | 大型模型訓練 |
| GCP | n1 + T4 | T4(1–4張) | 16–64 GB | 推論、小型訓練 |
| GCP | a2-highgpu | A100(1–16張) | 40–640 GB | 大型訓練 |
| Azure | NC6s_v3 | V100(1張) | 16 GB | 中型訓練 |
| Azure | ND A100 v4 | A100(8張) | 320 GB | 大型訓練 |
選型考量:
- 短期小型任務(微調 BERT、訓練 YOLOv8):AWS g4dn.xlarge 或 GCP T4 性價比高,按小時計費
- 中型訓練(從頭訓練視覺模型、訓練中型 LLM):AWS p3/p4 或 GCP A100,注意 Spot/搶佔式實例可降低成本 60–70%
- 超大型訓練(GPT-3 規模):需要 A100/H100 叢集,通常需要簽訂長期合約,或使用 CoreWeave、Lambda Labs 等 GPU 雲端
Google Colab 和 Kaggle:對台灣的學生、研究者和 AI 入門者,Google Colab Pro(T4/A100)和 Kaggle(T4/P100,每週 30 小時免費)是最容易取得的 GPU 資源,適合學習和中小型實驗。
TPU 和 Apple Silicon:其他選項
TPU(Tensor Processing Unit)——Google 自研加速器
TPU 是 Google 針對深度學習的矩陣乘法運算設計的特殊應用積體電路(ASIC),核心是被稱為「脈動陣列(Systolic Array)」的矩陣乘法硬體。
TPU 的優勢:
+ 矩陣乘法速度極快(TPU v4 Pod:~1 exaFLOP)
+ 在 TensorFlow/JAX 生態中與 GCP 深度整合
+ 適合大型 Transformer 模型的預訓練
TPU 的限制:
- 只支援 TensorFlow 和 JAX,不支援 PyTorch(需要特殊橋接器)
- 大量研究代碼和開源模型是 PyTorch 寫的,遷移成本高
- 除錯工具和生態工具鏈不如 NVIDIA 成熟
- 無法自購,只能通過 Google Cloud 租用(或參與 TRC 研究計畫)
Apple Silicon(M 系列晶片)——統一記憶體架構
Apple M1/M2/M3/M4 系列採用統一記憶體架構(Unified Memory Architecture),CPU、GPU 和 Neural Engine 共享同一塊記憶體(最高 192 GB on M2 Ultra),不需要在 CPU 和 GPU 之間複製資料。
Apple Silicon 的優勢:
+ 本地部署/推論效能優秀(功耗極低)
+ 統一記憶體讓大型模型可以在本地運行(如 70B LLaMA 用 192 GB 記憶體)
+ PyTorch 的 MPS(Metal Performance Shaders)後端支援 GPU 加速
+ 在台灣本地開發、測試、小型微調很方便
Apple Silicon 的限制:
- GPU 算力仍遠低於 NVIDIA(M4 Max GPU:約 14 TFLOPS,vs RTX 4090 的 82 TFLOPS)
- 不支援 CUDA,現有的 CUDA 優化代碼無法直接用
- 大規模並行訓練不適合(沒有 NVLink、不支援 InfiniBand 叢集)
- 部分 PyTorch 操作的 MPS 後端仍不完整,偶有功能缺失
實務定位:Apple Silicon 是台灣開發者進行本地開發、測試 prompt、小型推論的理想工具;需要正式訓練時,仍需上雲端 NVIDIA GPU。
應用場景
台灣企業的 GPU 基礎設施決策
一家台灣的中型電商公司(年營收約 20 億台幣),AI 團隊有 8 名工程師,正在規劃以下 AI 應用:
需求清單:
- 商品圖片的類別自動標注(推論,每日處理 50,000 張圖片)
- 用戶評論的情感分析(推論,每日處理 200,000 筆評論)
- 每季一次的推薦系統模型更新(訓練,使用 6 個月的交易資料)
- 即時的商品搜尋排名優化(推論,P99 延遲需低於 100ms)
選型分析:
需求 1:商品圖片分類推論
資料量:50,000 張/日,每張約 200ms 推論時間
總時間:50,000 × 200ms = 2.78 小時/日(一張 GPU 可以勝任)
推薦:雲端 AWS g4dn.xlarge(T4,16GB),按需或 Spot 實例,
批次在非尖峰時段執行,每月成本估算約 USD 500–1,000
需求 2:評論情感分析推論
模型:微調後的 BERT-base(1.1億參數,推論快)
200,000 筆 × 20ms/筆 = 1.11 小時/日
推薦:與需求 1 共用雲端 GPU 實例,不需要另外購置
需求 3:推薦系統模型訓練(每季一次)
訓練時間估算:RTX 3090 約需 48–72 小時 × 每季一次
方案 A(自購):RTX 3090(24GB VRAM),硬體成本約 45,000 台幣,
可在辦公室機器上運行,無需額外費用
方案 B(雲端):AWS p3.2xlarge(V100)× 72 小時 × 每季,
費用約 USD 720/季 ≈ 約 23,000 台幣/年
→ 若 5 年內至少 20 次以上的訓練任務,自購 RTX 3090 更划算
需求 4:即時商品搜尋排名(P99 < 100ms)
推論延遲要求嚴苛
方案:在地端部署輕量化模型(如量化後的 BERT-tiny),
使用 ONNX Runtime 的 CUDA 後端,部署在 AWS g4dn.xlarge 固定實例
(不用 Spot,避免中斷),確保延遲穩定
最終建議:
| 用途 | 硬體方案 | 估算成本(年) |
|---|---|---|
| 批次推論(需求 1+2) | AWS g4dn.xlarge Spot 實例 | USD 6,000–8,000 |
| 季度訓練(需求 3) | 辦公室自購 RTX 3090 工作站 | 硬體 NT$ 45,000(一次性) |
| 即時推論(需求 4) | AWS g4dn.xlarge 固定實例 | USD 7,000–9,000 |
不建議在這個規模採購 A100 或 H100:過度規格,成本遠超實際需求。
常見誤區
誤區一:GPU 的 CUDA Core 數量越多,訓練速度一定越快
CUDA Core 數量是 GPU 算力的一個指標,但訓練速度受多個瓶頸同時影響。最常見的瓶頸不是計算速度不夠,而是記憶體頻寬不夠:GPU 的計算單元跑得很快,但從 VRAM 搬運資料的速度跟不上,導致計算單元空閒等待(Memory Bandwidth Bound)。這也是為什麼 A100 在大型模型訓練上的實際速度遠超 RTX 4090,儘管兩者的理論 TFLOPS 差距沒有那麼懸殊——A100 的記憶體頻寬(2,039 GB/s)是 RTX 4090(1,008 GB/s)的兩倍,且 A100 的 NVLink 讓多卡通訊效率遠高於消費級 GPU 的 PCIe 連接。選擇 GPU 時,VRAM 容量和記憶體頻寬往往比 CUDA Core 數量更關鍵。
誤區二:用多張 GPU 訓練速度可以完美線性提升(2 張 GPU = 2 倍速度)
理論上,N 張 GPU 並行訓練的加速比是 N 倍,但實際上存在「阿姆達爾定律(Amdahl’s Law)」的限制和通訊開銷。在資料並行(Data Parallel)訓練中,每個梯度更新步驟結束後,所有 GPU 必須同步梯度(All-Reduce 操作),這個通訊時間不能被計算時間掩蓋。對於較小的模型或較大的 Batch Size,實際多卡加速效率通常在 70–90%;對於通訊密集的場景(如大型語言模型的模型並行),加速效率可能更低。在規劃多 GPU 基礎設施時,不能假設線性擴展;實際基準測試(Benchmark)是最可靠的規劃依據。
誤區三:用最新最強的 GPU 一定最划算
H100 是目前最強的訓練 GPU,但它的成本極高(每張約 3–4 萬美元,租用約每小時 3–5 美元),並非所有任務都需要這個等級。對台灣大多數企業的 AI 應用場景(微調 BERT、訓練 YOLOv8 物件偵測、推論服務),T4(16GB VRAM,約每小時 0.5 美元)或 RTX 3090(自購約 45,000 台幣)已經完全勝任,且性價比遠高於 H100。H100 的優勢在超大型模型的預訓練(GPT-3 規模以上)和需要極高吞吐量的推論服務。把工作負載和算力需求確實評估後再選型,避免「用最強工具解決最小問題」的資源浪費。
小練習
練習一:GPU 選型決策
台灣某家製造業公司的 AI 研究部門,正在規劃以下三個專案,預算各自獨立:
專案 A:晶圓外觀瑕疵偵測,需要訓練一個 YOLOv8 物件偵測模型。訓練資料:80,000 張高解析度(4K)晶圓圖片。預計每月重新訓練一次(加入新收集的瑕疵資料)。部署在生產線的工業電腦,推論延遲需求 < 50ms。
專案 B:產線設備維護預測,使用 LSTM + Transformer 分析設備感測器資料(每台設備每秒 200 個感測點 × 200 台設備),訓練資料量約 3 年的歷史數據,模型需要每週更新。
專案 C:內部知識庫問答系統,使用 LLaMA-3-70B 模型(700 億參數),部署在公司內部伺服器供全公司使用(不走外部 API,資料保密考量),預計每日並發問答請求約 500 次。
請分析:
- 每個專案應選擇哪個 GPU(消費級 RTX 4090 / 企業級 A100 / 雲端 T4 / Apple Silicon)?
- 專案 C 的 LLaMA-3-70B 模型部署,在 FP16 精度下需要多少 VRAM?如何規劃硬體?
- 若公司決定「一台伺服器解決所有三個專案」,你會怎麼建議配置?
看解答
**問題 1:各專案的 GPU 選擇** **專案 A:YOLOv8 晶圓瑕疵偵測** 推薦:**RTX 4090(消費級,24GB VRAM)× 1 張**,部署推論用 **工業級 NVIDIA T4 或 RTX 4000 Ada**。 理由: - YOLOv8 訓練在 24GB VRAM 下可以使用合理的 Batch Size(如 32–64 張 4K 圖片縮放後) - 每月重新訓練一次,對持續佔用雲端 GPU 不划算,自購 RTX 4090 作為訓練機較合理 - 生產線部署用 NVIDIA T4 Embedded(工業溫度規格、低功耗),支援 TensorRT 加速,可達到 50ms 以內的推論速度 **專案 B:感測器資料 LSTM + Transformer 訓練** 推薦:**雲端 AWS g4dn.2xlarge 或 GCP T4 × 1–2 張**,Spot 實例。 理由: - LSTM + Transformer 在感測器資料上,模型規模通常在數千萬參數以內(相對輕量) - 16GB T4 VRAM 足夠容納模型和 Batch 資料 - 每週更新但每次訓練時間不長(估計 2–6 小時),按需使用雲端 Spot 實例比自購更划算 - 若需要即時推論(實時監控 200 台設備),可在邊緣伺服器部署輕量化版本 **專案 C:LLaMA-3-70B 部署** 推薦:**A100 80GB × 2 張**(或等效的 H100 × 1 張),自購或長期租用。 詳細分析見問題 2。 **問題 2:LLaMA-3-70B 的 VRAM 需求計算** ``` LLaMA-3-70B 模型規格: 參數量:70 × 10⁹(700 億) FP16 精度下的 VRAM 需求: 每個參數佔 2 bytes(FP16 = 16 bits = 2 bytes) 僅模型權重:70B × 2 bytes = 140 GB VRAM 推論時的額外需求: KV Cache(支援 4,096 token 上下文):約 10–20 GB 系統開銷:約 2–4 GB 總計:約 155–165 GB VRAM ``` **硬體規劃方案:** 方案一(FP16 推論):A100 80GB × 2 張(共 160 GB),勉強放得下,但 KV Cache 空間有限,需要壓縮上下文長度。成本高但精度最佳。 方案二(INT4 量化,推薦):使用 bitsandbytes 或 GGUF 量化,每個參數壓縮到 4 bits: ``` INT4 量化:70B × 0.5 bytes = 35 GB VRAM → RTX 4090(24GB)× 2 張(模型分片)可行 → 或單張 A100 40GB 也可放入 精度損失:通常 < 3% 的 benchmark 下降 → 對問答系統場景可接受 ``` 方案三(本地部署,Apple Silicon):若資料安全要求允許使用 Mac,Mac Studio M2 Ultra(192GB 統一記憶體)可以用 Q4 量化載入 70B 模型,成本約 NT$ 150,000,但推論速度遠低於 GPU(每秒約 15–25 tokens,vs A100 的 50–80 tokens)。 **推薦方案**:INT4 量化 + RTX 4090 × 2 張(模型並行),或 A100 40GB × 1 張(單卡放得下 INT4 量化模型)。前者成本較低,後者部署更簡單。 **問題 3:一台伺服器解決三個專案的配置建議** 若公司希望用一台伺服器應對所有需求,以下是合理的配置: **推薦配置:** ``` 伺服器:4U 機架式伺服器(如 Supermicro 4U) CPU:AMD EPYC 9554(64 核),或 Intel Xeon Gold 6438N RAM:512 GB DDR5 ECC(系統記憶體,用於資料預處理) GPU: 訓練槽(PCIe Slot 1–2):RTX 4090 × 2(各 24 GB,模型訓練用) 部署槽(PCIe Slot 3):A100 40 GB × 1(LLaMA-3-70B 推論用) 儲存: 系統碟:NVMe SSD 4 TB 資料集:HDD RAID 48 TB(大量訓練圖片和感測器歷史資料) 網路:雙 25GbE(連接生產線工業電腦和公司內網) 電源:2,000W 冗餘電源(RTX 4090 × 2 + A100 合計 TDP 約 1,200W) ``` **工作負載排程建議:** - 平日白天:A100 專注 LLaMA-3-70B 推論服務(問答系統) - 夜間/週末:RTX 4090 × 2 執行 YOLOv8 每月訓練、LSTM 每週訓練 - 若訓練和推論有衝突,用 NVIDIA MIG(Multi-Instance GPU,僅 A100 支援)將 A100 分割,或設定排程優先級 **預算估算(粗估,2026 年初市場價格):** ``` 伺服器機殼 + 主機板 + CPU + RAM:約 NT$ 150,000 RTX 4090 × 2:約 NT$ 90,000 A100 40GB:約 NT$ 250,000–300,000(二手約 NT$ 150,000) 儲存:約 NT$ 30,000 電源 + 散熱:約 NT$ 20,000 合計:約 NT$ 540,000–600,000 ``` 若 A100 預算超出,可考慮改用 RTX 3090 × 3 張(各 24GB,共 72GB,量化後的 LLaMA-3-70B INT4 可分片放入),成本降至約 NT$ 350,000,但部署複雜度提高。練習二:了解 GPU 計算瓶頸
以下是一位 AI 工程師在使用 RTX 4090 訓練一個圖像分類模型時記錄的性能數據:
模型:EfficientNet-B7(預訓練,全量微調)
Batch Size:32(每張圖片 600×600 像素)
Epoch 時間:18 分鐘(每 Epoch 約 3,200 個 Batch)
GPU 使用率(nvidia-smi 觀察):平均 45%,峰值 95%
GPU 記憶體使用:8.2 GB / 24 GB(VRAM 使用率 34%)
CPU 使用率(工程師的 MacBook Pro M2 跑的是 Ubuntu VM):平均 87%
請回答:
- 這個訓練的瓶頸在哪裡?GPU 使用率 45% 代表什麼?
- 提出至少三個可以提高訓練效率的方案。
- 為什麼 GPU 記憶體只用了 34%,是否可以利用這個剩餘空間加速訓練?