M07.03|電腦視覺 CV 概覽:讓 AI 學會看世界
對人類來說看一眼就懂的照片,AI 需要分析幾百萬個像素才能理解
本講學習重點
圖像表示:每個像素是 0–255 的整數;彩色圖像有 R/G/B 三個通道
CNN 卷積核:小型濾波器在圖像上滑動,提取局部特徵(邊緣、紋理、形狀)
池化層(Pooling):縮小特徵圖尺寸,保留主要特徵,減少計算量
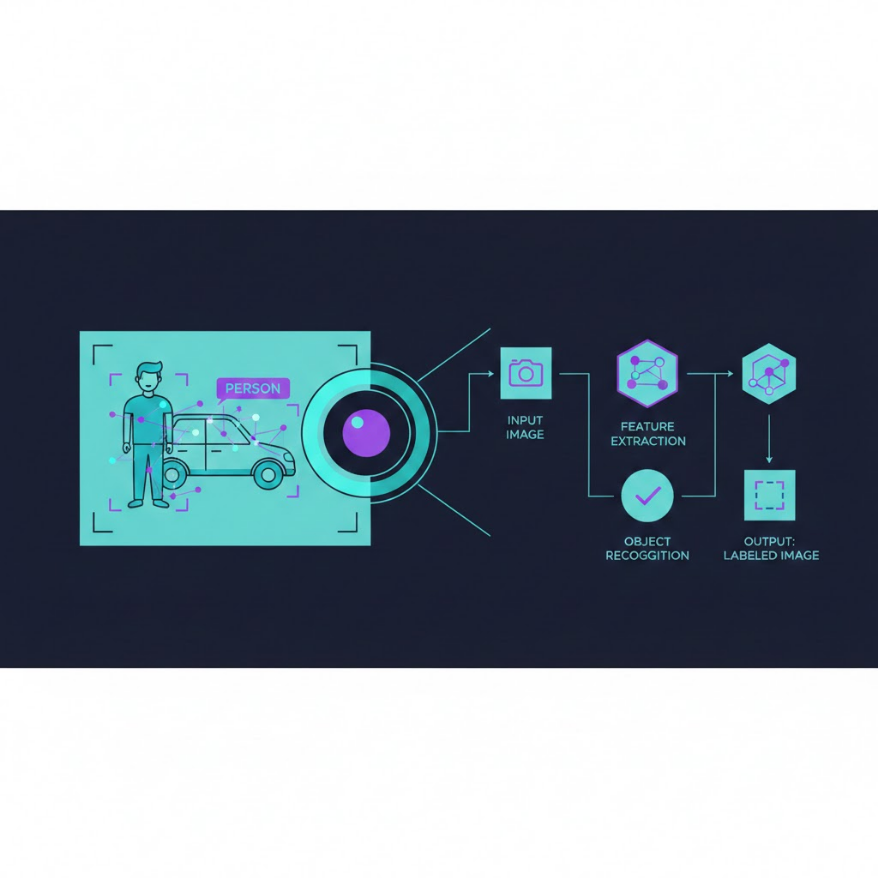
分類:圖像屬於哪個類別;偵測:哪裡有什麼;分割:每個像素屬於什麼
YOLO:單一網路一次前向傳播同時預測類別和位置,速度極快
Faster R-CNN:先用 RPN 找候選框,再分類,精度高但較慢
U-Net:編碼器-解碼器 + 跳躍連接,適合小資料集的精細分割
🎙️ Podcast(中文)
一句話搞懂
電腦視覺就是讓 AI 把圖像或影片中的幾百萬個數字(像素值)轉換成有意義的語意理解——不只說「圖裡有什麼」,還能告訴你「在哪裡」、「邊界在哪」、甚至「它在動向哪裡」。
白話解說
人類「看懂」一張圖,有多不可思議
你花不到一秒鐘就能看懂一張交通事故現場的照片:道路上有兩輛車、左邊那輛是紅色的轎車、右邊是白色貨車、它們在路口碰撞、地面有玻璃碎片、旁邊有一個人正在打電話。這一切理解,你是在幾乎不費力氣的狀況下完成的。
電腦「看到」同一張圖片時,它面對的是一個二維數字矩陣:對一張 1920×1080 的彩色圖片,電腦處理的是超過 600 萬個 0 到 255 之間的整數(每個像素有紅、綠、藍三個通道的數值)。如何從這堆數字中「理解」圖片的語意——這就是電腦視覺(Computer Vision, CV)要解決的問題。
人類視覺系統花了數億年演化才達到今天的效率。電腦視覺的研究者們用了約六十年,到 2012 年深度學習突破後,才開始讓電腦在特定視覺任務上接近甚至超越人類水準。
圖像在電腦眼中是什麼
理解電腦視覺,首先要理解電腦如何「看」圖像。一張灰階圖像是一個 H×W 的二維矩陣,H 是高度(像素行數),W 是寬度(像素列數),每個元素的值從 0(全黑)到 255(全白)。一張彩色圖像(RGB)則是一個 H×W×3 的三維張量(Tensor),有紅、綠、藍三個通道,每個通道是一個 H×W 的灰階矩陣。
這意味著一張 224×224 像素的彩色圖像(ImageNet 常用的輸入尺寸),在輸入給神經網路之前,實際上是一個包含 224×224×3 = 150,528 個數字的向量。CV 模型的任務,就是從這 15 萬個數字中學習出有意義的特徵。
早期的電腦視覺依賴手工設計特徵(Hand-crafted Features),如 SIFT、HOG 等算法,由人類設計針對邊緣、梯度、紋理的檢測器。這些方法在特定任務上有效,但靈活性差,遇到光線變化、視角變換、遮擋等情況就容易失效。
CNN:電腦視覺的核心引擎
卷積神經網路(Convolutional Neural Network, CNN) 是現代電腦視覺的技術基石。CNN 的核心操作是卷積(Convolution):用一個小型的「濾波器(Filter / Kernel)」——通常是 3×3 或 5×5 的數字矩陣——在圖像上逐步滑動,計算每個位置的加權和,生成一個特徵圖(Feature Map)。不同的濾波器提取不同類型的特徵:有些濾波器會對水平邊緣有強響應、有些對垂直邊緣、有些對特定紋理圖案。
CNN 的精妙之處在於:這些濾波器的參數不是人工設計的,而是透過訓練自動學習出來的。網路在看過大量標注圖像後,自動學到哪些視覺特徵對分類任務最有用。CNN 的結構通常是多個卷積層堆疊,越深的層提取越抽象的特徵:淺層學到邊緣和顏色、中層學到局部形狀(眼睛、車輪)、深層學到整體概念(人臉、汽車)。
池化層(Pooling Layer) 通常穿插在卷積層之間,其作用是縮小特徵圖的空間尺寸(例如取每個 2×2 區域的最大值,稱為 Max Pooling),減少計算量的同時保留最顯著的特徵,也讓模型對輕微的平移和縮放更具魯棒性。
代表性架構的演進:AlexNet(2012)首次在 ImageNet 大賽中用深度 CNN 大幅超越傳統方法,開啟了深度學習革命;VGG(2014)用簡單的 3×3 卷積堆疊更深的網路;ResNet(2015)引入殘差連接(Residual Connection),解決了深層網路難以訓練的梯度消失問題,可以訓練 152 層以上的網路;EfficientNet(2019)自動搜索深度、寬度和分辨率的最佳組合,達到在更少參數量下更高精度的效果。
視覺任務的四個層次
電腦視覺的任務依照理解的粒度由粗到細分為四個層次:
影像分類(Image Classification):給定一張圖像,輸出這張圖像屬於哪個類別(或類別的機率分布)。例如:「這是一隻貓」、「這是一張發票」。任務簡單清晰,輸出只有一個(或幾個)類別標籤。代表資料集:ImageNet(1000 類)。
物件偵測(Object Detection):在圖像中找出所有感興趣的物件,對每個物件輸出其類別和位置(以邊界框 Bounding Box 表示:x, y, 寬, 高)。例如:「這張圖像中有三人、兩輛車、一頭狗,它們的位置分別在哪裡」。比分類難,因為物件數量不定、大小不一、可能互相遮擋。代表框架:YOLO 系列、Faster R-CNN。
語義分割(Semantic Segmentation):對圖像中的每一個像素分類,輸出與原圖等尺寸的標籤圖。例如:這個像素屬於「道路」、那個像素屬於「天空」、那些像素屬於「行人」。與物件偵測不同,語義分割知道每個像素的類別,但無法區分同類物體中的不同個體(兩個「人」的像素都標記為「人」,不知道哪些屬於哪個人)。代表架構:U-Net、DeepLab。
實例分割(Instance Segmentation):結合物件偵測和語義分割的精細度——不只知道每個像素的類別,還知道它屬於哪個具體實例。圖中三個人的像素會被分別標記為「人 1」「人 2」「人 3」。這是最細緻也最難的視覺任務,代表模型:Mask R-CNN。
應用場景
| 行業 | 具體應用 | 使用的 CV 任務 | 代表架構 |
|---|---|---|---|
| 製造業 | PCB 板缺陷檢測、焊點品質檢查 | 影像分類 / 語義分割 | ResNet + 異常偵測 |
| 醫療影像 | X 光/CT 腫瘤定位、病灶分割、病理切片分析 | 物件偵測 / 語義分割 | U-Net、Mask R-CNN |
| 自駕車 | 行人、車輛、號誌即時偵測與追蹤 | 物件偵測 + 追蹤 | YOLO、Faster R-CNN |
| 零售 | 無人商店商品辨識、貨架庫存監控 | 影像分類 / 物件偵測 | EfficientNet、YOLOv8 |
| 農業 | 無人機空拍辨識作物病害、評估作物生長狀況 | 語義分割 | U-Net + 衛星影像 |
| 安全監控 | 人臉辨識門禁、異常行為偵測、人群密度估算 | 人臉偵測 / 姿態估計 | MTCNN、OpenPose |
| 金融 | 支票和發票的 OCR 辨識、行員證件核驗 | 文字偵測 + OCR | CRAFT + TrOCR |
常見誤區
誤區 1:「只要資料夠多,CNN 就一定能學好」
資料量是重要的,但不是唯一的決定因素。資料的品質、標注的準確性、以及訓練資料和測試場景的一致性(資料分布),對模型效果的影響往往遠超過純資料量。常見的陷阱包括:工廠缺陷偵測模型用標準光源下的樣本訓練,部署到光線條件不同的產線後大幅失準;醫療影像模型用單一醫院的 CT 機訓練,換了不同品牌的機器後效果下降。這個現象稱為資料集偏差(Dataset Bias)或領域偏移(Domain Shift)。在準備訓練資料時,必須確保涵蓋生產環境中可能遇到的各種變化:不同光線、角度、解析度、設備品牌。此外,100 張精準標注的缺陷圖片,往往比 10,000 張標注不一致的圖片更有訓練價值。
誤區 2:「CNN 和人類的視覺理解方式是相同的」
CNN 在特定任務上的準確率已超越人類,但它的「理解」和人類有本質差異。人類看到一隻貓,會整合形狀、材質、動作、語境等多種線索,並且有豐富的語意背景知識。CNN 更多是在學習像素統計模式,這讓它容易被對抗樣本(Adversarial Examples)欺騙:在圖像上添加人眼幾乎看不見的微小像素擾動,CNN 就可能以 99% 的信心把一隻熊貓分類成長臂猿。此外,CNN 缺乏「常識」:它無法理解「這張圖片裡的人看起來很痛苦,因為手被夾在門縫裡」,它只是在模式匹配。因此,雖然 CV 在工業檢測等重複性任務上表現卓越,但在需要語意理解和常識推理的任務上,仍需要與 NLP 或知識圖譜結合,才能達到更高層次的理解。
誤區 3:「電腦視覺模型的評估,看測試集準確率就夠了」
測試集準確率是必要但不充分的評估指標。幾個容易被忽略的面向:首先是推理速度和計算成本——一個在伺服器上需要 200 毫秒的模型,無法部署在需要即時(30 FPS)響應的生產線相機上;其次是邊緣案例的魯棒性——一個整體準確率 99% 的模型,可能在某類特殊樣本(如殘缺品、罕見缺陷形態)上的準確率只有 60%,而恰恰這些邊緣案例才是生產中最需要被正確偵測的;第三是模型的可解釋性——在醫療影像判讀的場景中,FDA 等監管機構要求模型能解釋「為什麼判斷這裡有腫瘤」,單靠準確率指標無法滿足合規需求。完整的 CV 系統評估應包含:精準度(Precision)、召回率(Recall)、推理延遲(Latency)、模型大小、以及在不同子群組上的公平性評估。
小練習
練習 1:選擇正確的 CV 任務類型
一家台灣的半導體廠商正在規劃 AI 視覺檢測系統,以下是四個具體需求,請為每個需求選擇最合適的電腦視覺任務類型(影像分類、物件偵測、語義分割、實例分割),並說明原因:
| 需求描述 | 最佳 CV 任務 |
|---|---|
| A. 判斷這片晶圓是否通過品管(只需要 Pass/Fail 結果) | ? |
| B. 在晶圓表面找出所有缺陷的位置(可能有多個不同類型的缺陷) | ? |
| C. 精確標出晶圓上的電路佈線區域和空白區域的分界(需要像素級精度) | ? |
| D. 在生產線影片中追蹤每一顆晶片的移動路徑 | ? |
查看答案
**A. 影像分類(Image Classification)** 需求只要求「通過/失敗」的二元輸出,不需要知道缺陷的位置。這正是影像分類最適合的場景:給定輸入圖像,輸出一個類別標籤。這也是計算成本最低的任務,適合高速產線的即時判斷。可使用 EfficientNet 或 ResNet 微調,通常幾百張標注樣本就能達到不錯的效果。 **B. 物件偵測(Object Detection)** 需求是「找出所有缺陷的位置和類型」,需要輸出每個缺陷的邊界框(位置)和類別(如:劃痕、凹坑、污染物)。這是物件偵測的標準場景:圖像中有多個感興趣物件,每個都需要定位和分類。YOLO 系列因其速度優勢常被用於工業即時偵測,Faster R-CNN 則在精度要求更高時使用。 **C. 語義分割(Semantic Segmentation)** 需求是「像素級的區域分界」——知道每個像素屬於電路區還是空白區,這是語義分割的核心任務。U-Net 因其在醫療和工業精細分割上的出色表現(尤其是在小資料集上),是此類需求的首選架構。分割結果可以精確計算電路覆蓋率、佈線均勻性等指標。 **D. 物件偵測 + 目標追蹤(Object Detection + Tracking)** 在影片中追蹤每顆晶片的移動路徑,需要在每一幀中偵測到每顆晶片的位置(物件偵測),然後跨幀建立同一顆晶片在不同時間點的對應關係(目標追蹤)。常用的組合是 YOLOv8 偵測 + ByteTrack 或 DeepSORT 追蹤算法。這個任務對即時性要求高(產線速度快),因此偵測器的推理速度是關鍵考量。練習 2:CNN 特徵學習的直覺理解
假設你要訓練一個 CNN 模型區分「台灣黑熊」和「貓熊」,模型的三個卷積層組分別學習什麼層次的特徵?如果兩種動物的訓練資料量差異很大(台灣黑熊樣本 500 張 vs. 貓熊樣本 5,000 張),你預期會出現什麼問題?應如何改善?