M07.07|OCR 與文件理解:讓 AI 讀懂紙本文件
發票、合約、手寫表單 — AI 把紙上的字變成可搜尋的資料
本講學習重點
OCR(光學字元辨識):把圖片中的文字轉換成可編輯的數位文字
文件理解(Document Understanding):在 OCR 之上,進一步理解文件的結構和語意
傳統樣板式 OCR:依靠固定版面位置擷取文字,版面改變就失效
深度學習 OCR:用 CNN+RNN 或 Transformer 直接端對端辨識,對版面變化更魯棒
PaddleOCR(百度):目前對繁體中文支援最好的開源 OCR 框架之一
LayoutLM(微軟):結合文字 token、位置資訊、視覺特徵的多模態 Transformer
鍵值擷取:從文件中找出「欄位名稱:值」的配對(如「發票號碼:AB12345678」)
表格擷取:辨識表格的行列結構,正確對應儲存格內容
手寫辨識挑戰:筆跡個人化、連筆、潦草、混合印刷手寫
繁體中文挑戰:字形複雜、簡繁混用、直書橫書、標點位置、台灣用字習慣
🎙️ Podcast(中文)
一句話搞懂
OCR(光學字元辨識)就是讓 AI「看」一張圖片並把裡面的字「抄」下來;但現代文件 AI 的目標遠不止抄字——它要看懂一份發票、知道哪個數字是「金額」、哪段文字是「賣方名稱」、表格的第三列第二欄是什麼、甚至讀懂草草填寫的手寫表單,把一堆「圖片」變成結構化的可用資料。
白話解說
紙本文件為什麼還是問題
在數位化辦公喊了三十年之後,台灣各行各業仍然充斥著大量的紙本文件——醫院的紙本病歷和手寫醫囑、政府機關的申請表格、銀行的開戶表單、公司的紙本發票和收據、法院的判決書掃描檔、以及數十年前的檔案文件。即使是「電子文件」,許多也只是掃描的 PDF——外表是數位檔,但裡面是圖片,電腦無法搜尋、無法複製文字、無法做任何結構化處理。
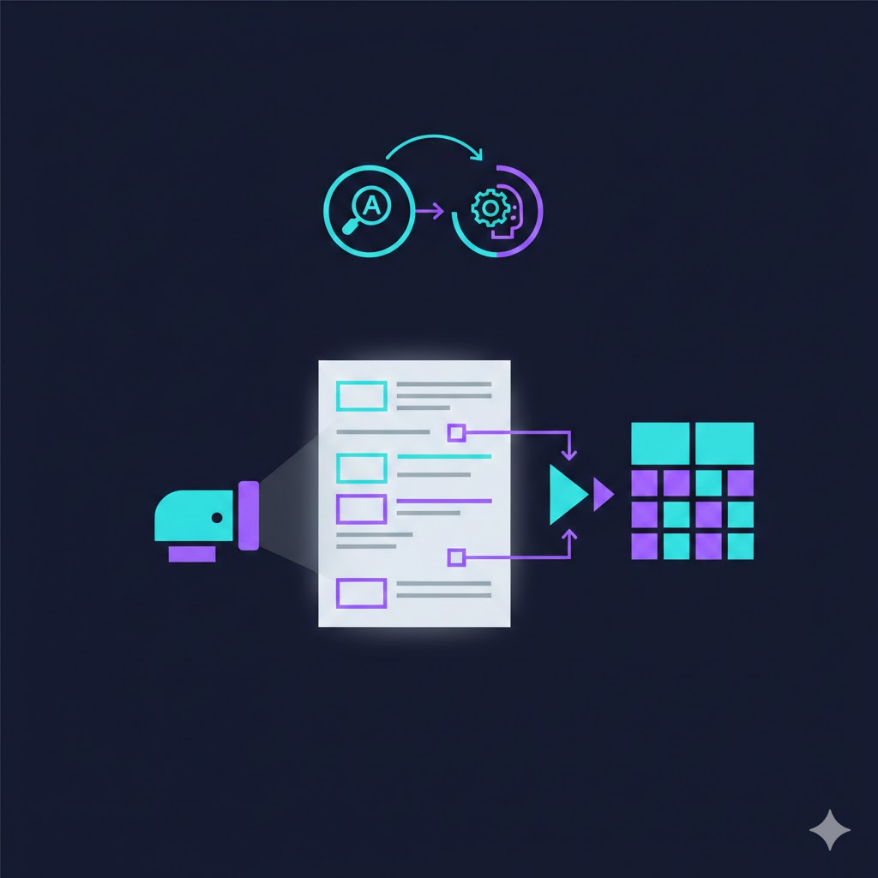
這些「數位外殼、紙本本質」的文件,是企業資料數位化的最大瓶頸。一個企業可能每天收到數千張發票,需要人工逐張鍵入金額、日期、廠商名稱到 ERP 系統;一家保險公司的理賠部門要審核大量手寫的理賠申請表;一個法律事務所要在數百頁合約掃描檔中找出特定條款。光學字元辨識(OCR, Optical Character Recognition) 以及更進一步的文件理解(Document Understanding) 技術,就是解決這個問題的關鍵工具。
OCR 的目標是把圖片中的文字還原成可編輯的數位文字(例如把一張發票的 JPEG 圖片,轉成 TXT 文字檔)。文件理解的目標更進一步:不只「抄字」,還要理解文件的結構和語意——知道「統一編號」後面那串數字是公司的稅號、「應付金額」後面的數字是這張發票要付的錢、表格第二欄的數字是單價而非總價。這種從非結構化文件中提取結構化資訊的能力,是現代文件 AI 的核心價值。
OCR 技術演進:從模板到深度學習
OCR 技術的歷史可以分為三個清晰的世代,每個世代的彈性和準確率都有顯著提升。
第一代:樣板式 OCR(Template-based OCR,1980s–2000s)。早期商用 OCR 的運作方式是:先建立一個「字元模板庫」,把每個字母或數字的標準外觀儲存起來,然後把圖片切割成單個字元後,和模板逐一比對,找出相似度最高的字元。這種方法在字型固定、版面規則的文件上(如早期印表機列印的英文文件)效果不錯,但對複雜字型、手寫、傾斜、或版面不規則的文件則幾乎完全失效。最廣為人知的開源 OCR 引擎 Tesseract(最初由 HP 開發,後由 Google 接手)就是這個世代的代表,但後續版本已加入了深度學習元件。
第二代:機器學習輔助 OCR(2000s–2015s)。引入了 SVM、隨機森林等機器學習分類器,在字元分類上比純模板比對更有彈性,同時引入了語言模型(N-gram)來修正辨識結果(例如把「鏡」辨識成形狀相近的「境」後,語言模型根據上下文判斷更可能是「鏡子」而非「環境」,把結果修正回「鏡」)。對版面分析(把文件分割成段落、標題、表格、圖片等區域)的自動化也在這個時期逐步成熟。
第三代:深度學習 OCR(2015s至今)。Convolutional Neural Network(CNN)用於特徵提取,Recurrent Neural Network(RNN/LSTM)處理序列輸出,兩者結合搭配 CTC(Connectionist Temporal Classification) 損失函數,可以不需要字元級別的分割就直接辨識一整行文字——這是端對端 OCR 的核心突破。後來進一步引入 Transformer Attention 機制,辨識精度和對複雜版面的容錯性大幅提升。PaddleOCR(百度開源)是目前對繁體中文支援最好的開源 OCR 框架之一,整合了版面分析、文字偵測(Text Detection)、文字辨識(Text Recognition)三個模組,在繁體中文文件上的表現明顯優於舊版 Tesseract。
文件理解:OCR 之後的智慧提取
拿到 OCR 輸出的原始文字還不夠——一份發票的 OCR 結果可能是:「統一發票 2B00000001 日期 113/03/15 買受人 某某有限公司 統一編號 12345678 品名 電腦週邊設備 數量 5 單價 1,200 金額 6,000 稅額 300 總計 6,300」,這是一串平面文字,要讓電腦自動知道「6,300 是應付總額」、「12345678 是買受人統編」,就需要文件理解技術。
LayoutLM(微軟,2020)是這個領域的重要里程碑:它是一個基於 BERT 的 Transformer 模型,但在訓練時把每個文字 token 的版面位置(Bounding Box:左上角 x/y 座標、寬、高)也作為輸入特徵加進去,同時可選擇加入從文件圖片提取的視覺特徵(字型大小、粗細、是否在邊框內)。LayoutLM 的核心洞察是:在文件理解中,一個詞的位置和它的內容同樣重要——「6,300」這個數字如果緊跟在「總計」右側,和如果緊跟在「數量」右側,語意完全不同。後續版本 LayoutLMv2 和 LayoutLMv3 進一步整合了圖文視覺特徵,成為企業文件 AI 解決方案的標準骨幹。
鍵值擷取(Key-Value Extraction) 是文件理解最常見的任務:從文件中自動找出「欄位名稱-欄位值」的配對。例如從一張掃描的報稅申報書中,自動擷取「申報人姓名:王小明、身分證字號:A123456789、所得總額:850,000」。這需要模型同時理解文字內容(「申報人姓名」是一個欄位標籤)和版面關係(它右邊或下方的文字是對應的值)。
表格擷取(Table Extraction) 是另一個關鍵但技術上更困難的任務:識別文件中的表格,正確對應行列結構,把每個儲存格的內容提取出來。困難之處在於:表格可能有合併儲存格、無邊框(靠對齊暗示結構)、跨頁延續,以及儲存格內有換行等複雜情況。
手寫辨識與台灣特有挑戰
手寫辨識(Handwriting Recognition) 比印刷文字辨識難度更高,因為每個人的筆跡都是獨特的個人語言,沒有固定字型。主要挑戰包括:連筆(幾個字母或筆劃連在一起,邊界難以分割)、潦草(字形偏離標準,多種寫法都合理)、個人習慣(有些人的「7」和「1」幾乎一樣)、以及混合印刷與手寫(表格的欄位標題是印刷,填寫內容是手寫)。深度學習讓手寫辨識有了長足進步,但對醫師處方箋那種「藝術性潦草」,準確率仍然有限。
台灣的繁體中文 OCR 有幾個特殊挑戰值得重視:字形複雜——繁體中文常用字約 4,800 個,但含罕用字的全字庫超過 7 萬字,每個字的筆劃複雜度遠超英文;簡繁混用——台灣文件中有時混有簡體中文(網路複製貼上的內容、中國廠商的文件),OCR 需要能正確辨識而不把繁體「關」辨識成簡體「关」;直書版面——傳統書信、廟宇文件、部分法律文書採用直書(從右到左、從上到下),版面分析需要支援;特殊標點位置——繁體中文的全形標點(。,「」【】)和半形標點混用,以及特殊符號(§、○、◎)在 OCR 後的編碼一致性問題;台灣特有用字——如「臺灣」和「台灣」、「羣」和「群」的正字和通用字差異,需要後處理標準化。
應用場景
| 場景 | 技術需求 | 業務價值 | 主要挑戰 |
|---|---|---|---|
| 電子發票驗真與入帳自動化 | 發票 OCR + 鍵值擷取 | 從每張發票的人工鍵入改為自動化,節省大量人力 | 發票版面多樣(紙本/電子/收銀紙),格式不統一 |
| 銀行開戶表單數位化 | 手寫辨識 + 表單欄位擷取 | 客戶填寫的紙本表單自動轉數位,減少人工鍵入錯誤 | 手寫品質差異大,身分證字號、姓名的容錯率要求高 |
| 合約審查與條款擷取 | OCR + NLP 文件理解 | 從數百頁合約中自動定位風險條款(違約金、排他條款) | 法律語言複雜,跨頁段落、引用其他條款 |
| 醫院病歷數位化 | 手寫辨識 + 醫療術語 NLP | 舊紙本病歷轉數位,支援電子健康記錄系統 | 醫師手寫潦草、醫學縮寫、跨科室格式不統一 |
| 政府公文檔案搜尋 | 掃描 PDF OCR + 全文索引 | 讓數十年的公文檔案可全文搜尋,提升行政效率 | 老舊文件掃描品質差、繁體字罕用字多 |
| 海關報關文件處理 | 多語言 OCR + 鍵值擷取 | 自動讀取進口報單資訊,加速通關作業 | 多國語言混用、各國格式不同、貨品名稱縮寫 |
| 保險理賠表單審核 | 手寫表單 OCR + 欄位驗證 | 加速理賠初審,自動標記填寫不完整的欄位 | 手寫金額辨識(阿拉伯數字/中文大寫數字)準確率要求高 |
常見誤區
誤區 1:「OCR 的準確率已經夠高,抄下來的文字直接就能用」
現代深度學習 OCR 在乾淨的印刷文件上,字元準確率(Character Accuracy)確實可達 99% 以上。但「99% 準確率」意味著每 100 個字就有 1 個錯——一份 10,000 字的合約,預期有 100 個字元錯誤。這在搜尋和全文瀏覽的應用可能可以接受,但在需要精確資料的應用(如擷取金額、帳號、身分證字號)則完全不行。更重要的是,OCR 錯誤往往不均勻分布:印刷部分 99.9% 準確,但表格邊框附近的文字、傾斜的手寫部分、低解析度區域可能只有 80% 準確,而偏偏關鍵欄位(如帳號、金額)就在這些難辨識的地方。實際部署 OCR 系統時,必須針對關鍵欄位設計後驗證(Post-validation)步驟:如統一編號要符合 8 位數字加上驗證碼算法、發票號碼要符合財政部的格式規則、日期要能解析為合法日期——這些規則驗證能攔截大多數 OCR 錯誤,顯著提升最終資料品質。
誤區 2:「用通用 OCR 模型就能處理所有文件類型」
通用 OCR 模型在「把文字抄下來」這個層次或許夠用,但文件理解的精度嚴重依賴領域特化。一份醫院的病歷表有固定的欄位結構(主訴、病史、體格檢查、診斷、處置)和特定的醫學縮寫習慣,一份海關報單有關務署規定的固定格式,一份法院判決書有特定的段落結構(事實、理由、主文、宣告)。針對特定文件類型微調的 LayoutLM 模型,在鍵值擷取準確率上往往比通用模型高 20–40 個百分點。因此,文件 AI 專案的成功關鍵之一是蒐集足夠的領域標注資料(至少幾百份有人工標注欄位的同類型文件),進行領域特化訓練或微調,而不是天真地期待一個通用模型能理解所有類型的業務文件。
誤區 3:「文件 AI 可以完全取代人工審核,達成全自動化」
文件 AI 的最佳定位是加速和輔助,而非完全替代人工。對於格式規範、字跡清晰的標準文件,全自動化可以達到 95% 以上的準確率,大幅節省人力。但以下情況仍需人工介入:低品質輸入(嚴重折皺、污漬、褪色的舊文件)、手寫潦草(模型信心分數低的欄位)、格式例外(不符合預期樣式的特殊文件)、以及高風險決策(涉及大額金融交易、醫療處置的文件)。實務上最好的架構是人機協作:AI 自動處理信心分數高的欄位,對信心低的欄位標記出來提交人工確認,這樣既保住了大量節省人力的效益,又不犧牲關鍵欄位的準確性。台灣勞動部也要求涉及勞工權益的自動化決策需有人工複核機制,法遵面同樣支持這種人機協作的設計。
小練習
練習 1:評估 OCR 後處理需求
你接到一個任務:幫一家中型貿易公司建立「進口報關發票自動錄入系統」。每天大約有 200 張進口商業發票(Invoice),來自不同國家的供應商,格式各不相同,包含:發票號碼、日期、買方/賣方名稱與地址、貨品描述、數量、單價、總金額、幣別、付款條件。
請回答:
- 這個任務中,OCR 本身可以解決什麼?文件理解需要解決什麼?
- 列出三個你會在後處理階段加入的驗證規則(具體說明格式規則)。
- 這個系統有哪個欄位辨識錯誤的後果最嚴重?你會如何設計這個欄位的安全機制?
查看答案
**1. OCR 解決的問題 vs 文件理解解決的問題:** OCR 解決的問題:把每張發票圖片(JPG/PDF 掃描)轉成機器可讀的文字,包含發票上所有可見的文字、數字、符號。OCR 輸出的是一堆原始文字,不知道哪個是「發票號碼」、哪個是「金額」。 文件理解解決的問題:在 OCR 文字的基礎上,根據欄位標籤(Invoice No.、Amount Due 等)和版面位置,把文字正確分配到對應的資料欄位,輸出結構化的 JSON 資料(`{"invoice_no": "INV-20240315-001", "total_amount": 15000, "currency": "USD", ...}`)。版面多樣(每家供應商格式不同)是最大挑戰,需要能泛化到未見過版面的模型。 **2. 三個具體後處理驗證規則:** - **日期格式驗證**:OCR 可能把 「03/15/2024」讀成「O3/15/2O24」(把數字0讀成英文O),需要用正規表示式驗證日期格式(`\d{2}/\d{2}/\d{4}` 或 `\d{4}-\d{2}-\d{2}` 等常見格式),並嘗試解析為合法日期。無法解析的日期標記為「需人工確認」。 - **金額一致性驗證**:單價 × 數量 = 小計,小計加總 + 稅額 = 總金額。系統計算一次,若與 OCR 讀到的數字偏差超過 1 元(容許捨入誤差),標記為「金額不一致,需人工確認」。這能攔截金額欄位的 OCR 誤讀(如把「15,000」讀成「1,500」)。 - **幣別有效性驗證**:幣別代碼必須是 ISO 4217 標準的三碼英文(USD、EUR、JPY、TWD 等),若 OCR 讀到非三碼英文的字串(可能是版面相鄰的其他文字被誤讀進來),標記為異常。 **3. 最嚴重的欄位 + 安全機制設計:** 最嚴重的欄位是**「總金額」加上「幣別」的組合**。金額辨識錯誤(如少讀一個零:1,500,000 變成 150,000)搭配幣別錯誤(USD 變成 JPY),可能導致匯款金額錯誤幾十萬新台幣的財務損失,且追討跨國貨款的成本和時間極高。 安全機制設計: 1. 對「總金額」欄位設定信心分數門檻:OCR 引擎信心低於 95% 的,強制轉人工審核(不允許自動提交)。 2. 加入「合理範圍驗證」:根據歷史交易資料,設定每家供應商的「正常交易金額範圍」(如供應商 A 過去的發票金額在 5,000–500,000 USD 之間),超出範圍的自動標記警示,由主管審核。 3. 在 ERP 系統填入前,顯示「系統擷取結果與原始發票對照畫面」,要求操作人員目視確認關鍵欄位(總金額、幣別),點擊確認後才送出。練習 2:台灣情境下的 OCR 挑戰分析
以下是四種在台灣常見的文件處理場景,請分析每個場景的主要 OCR/文件理解挑戰,並提出至少一個具體的應對策略:
| 場景 | 主要挑戰(列出 2 個) | 應對策略 |
|---|---|---|
| A. 數位化 1970–1990 年代的法院判決書紙本存檔(泛黃、褪色、直書、繁體) | ? | ? |
| B. 自動辨識民眾填寫的戶籍謄本申請書(手寫姓名、地址、身分證字號) | ? | ? |
| C. 從台灣電商平台的商品圖片中擷取商品規格文字(各品牌圖片風格不同,文字有時是設計字體) | ? | ? |
| D. 讀取台灣健保特約醫院的住院費用明細單(含表格、金額、醫療代碼) | ? | ? |