M07.08|推薦系統:AI 怎麼知道你想看什麼
Netflix 的推薦比你自己選的還準 — 背後是協同過濾和深度學習
本講學習重點
推薦系統:預測使用者對未接觸過的物品的喜好,並按喜好程度排序推薦
使用者基礎 CF(User-based CF):找到與目標使用者喜好相似的鄰居群,推薦他們喜歡的物品
物品基礎 CF(Item-based CF):若使用者喜歡 A,則推薦和 A 相似的物品 B(Amazon 採用)
矩陣分解(Matrix Factorization):把使用者-物品評分矩陣分解為低維潛在因子,解決稀疏性問題
內容式過濾:根據物品的特徵屬性,推薦和使用者過去喜歡的物品屬性相似的物品
隱式回饋(Implicit Feedback):點擊、觀看時長、購買、加購物車等行為,比顯式評分更豐富
冷啟動:新使用者(無行為資料)和新物品(無評分資料)的推薦難題
深度學習推薦:Wide & Deep、DIN、YouTube DNN 等,能捕捉非線性交互特徵
過濾泡泡(Filter Bubble):推薦系統強化既有偏好,使用者只看到同質內容
探索與利用(Exploration vs. Exploitation):已知喜好的推薦(利用)vs 嘗試新領域(探索)
🎙️ Podcast(中文)
一句話搞懂
推薦系統的本質是「預測你對還沒看過的東西的喜好程度」——Netflix 猜你會想看哪部片,蝦皮猜你會買哪個商品,Spotify 猜你會喜歡哪首歌;它的做法是分析你過去的行為(看過什麼、買過什麼、聽過什麼),找出和你「口味相似」的其他人,或找出和你過去喜歡的東西「特性相似」的其他物品,然後把那些東西排序後推給你。
白話解說
推薦系統解決什麼問題
想像你走進一家有一百萬種商品的百貨公司,完全沒有指引。你可能什麼都找不到,或只能瀏覽一小部分。網路上的情況更誇張:Netflix 有超過兩萬部影片,Spotify 有一億首歌曲,蝦皮有數億件商品。選擇太多本身就是個問題——資訊過載讓使用者在決策上消耗大量精力,最終什麼都不選或隨便選了事。
推薦系統要解決的核心問題正是:從數以百萬計的選項中,找出你此刻最可能感興趣的那幾個,並按照喜好程度排序呈現給你。這不只是使用者體驗的問題,也直接影響商業結果:Netflix 的研究顯示,推薦系統每年為其節省約 10 億美元的使用者流失成本;Amazon 估計其 35% 的營業額來自推薦功能。台灣電商和串流平台同樣高度依賴推薦系統來驅動消費和提升留存率。
推薦系統的輸入通常有兩類:顯式回饋(Explicit Feedback)——使用者主動表達的評分(五星評分、按讚/不喜歡)——這類資料品質高,但使用者很少主動留評;隱式回饋(Implicit Feedback)——使用者的行為資料(點擊、觀看時長、購買、加購物車、搜尋)——這類資料量大、自然產生,但噪音多(你可能點了一個影片但只看了 10 秒就關掉)。現代推薦系統大多主要依賴隱式回饋,輔以顯式回饋。
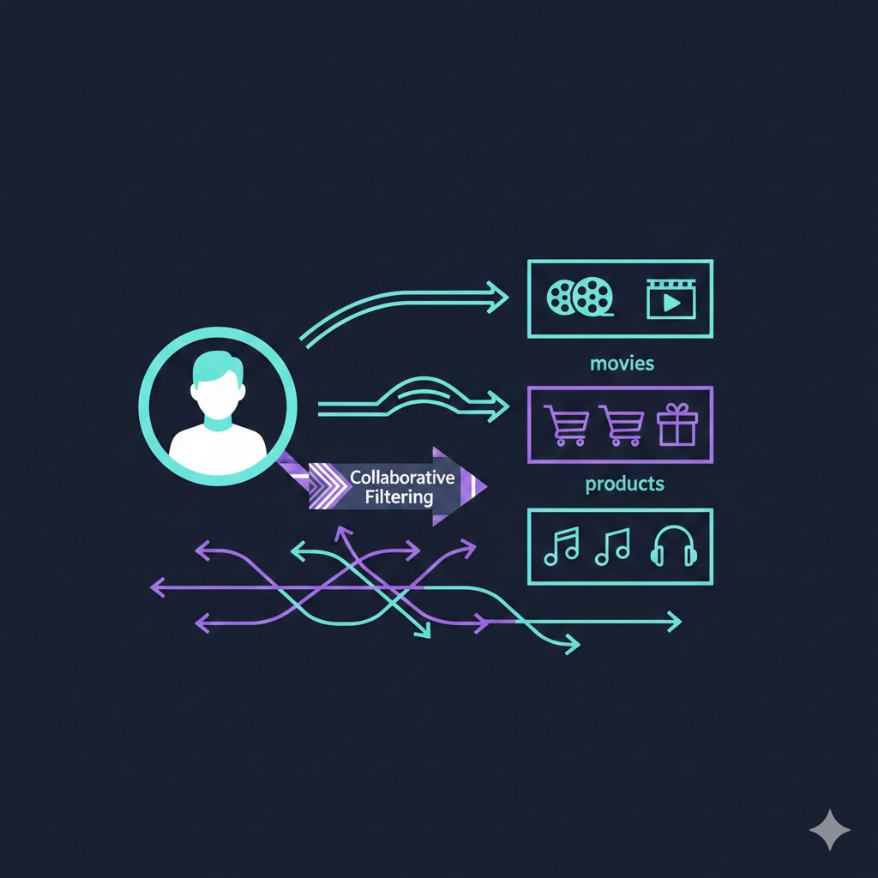
協同過濾:「和你品味相近的人也喜歡…」
協同過濾(Collaborative Filtering, CF) 是推薦系統中最經典、也最直觀的方法,核心思想是:人以群分,你的喜好可以從和你相似的人的喜好來推測。如果使用者甲(你)和使用者乙的評分歷史高度相似(你們都喜歡相同的幾百部電影),那麼乙看過但你還沒看過的電影,就很可能也是你會喜歡的。
使用者基礎協同過濾(User-based CF) 的步驟是:為目標使用者找出一組「最相似的鄰居使用者」(通常用餘弦相似度或皮爾森相關係數衡量兩個使用者評分向量的相似性),然後聚合這些鄰居對未評分物品的評分,生成推薦列表。直觀但有兩個問題:使用者數量很大時,計算全部使用者兩兩之間的相似度計算量龐大(O(n²));更重要的是,使用者的興趣隨時間變化,「鄰居」關係也一直在改變。
物品基礎協同過濾(Item-based CF) 換了一個角度:計算物品之間的相似度(「哪些物品常常被同一批使用者一起評高分?」),然後根據使用者喜歡的物品,推薦和這些物品最相似的其他物品。Amazon 在 2000 年代初期就是靠 Item-based CF 建立了「看了這個也看了那個」的推薦系統。Item-based CF 的優點是物品數量和物品相似度矩陣相對穩定(商品的屬性不會每天變),可以離線預計算,線上推薦時只需要查表,速度快。
協同過濾面臨一個基本挑戰:稀疏性問題(Sparsity Problem)。一個有一百萬使用者和一萬種商品的電商,理論上有 100 億個使用者-商品評分組合,但實際評分通常只有幾千萬筆——稀疏率超過 99%。大多數使用者-商品配對是「空白」的,使得相似度計算不可靠。矩陣分解(Matrix Factorization) 是解決稀疏性的關鍵技術:把原本的使用者-物品評分矩陣分解成兩個低維矩陣(使用者潛在因子矩陣 × 物品潛在因子矩陣),每個使用者和每個物品都用一個低維向量(如 50 維)表示,這個向量捕捉了「潛在喜好維度」(如喜歡動作片的程度、喜歡文藝片的程度……不需要明確定義,讓模型自己學習)。SVD(奇異值分解) 和後來的 ALS(交替最小二乘法) 是矩陣分解的兩種主要訓練方法,Netflix Prize(2009 年)的最高分方案就是基於矩陣分解。
內容式過濾:「因為你喜歡這種類型…」
內容式過濾(Content-based Filtering) 不看其他使用者的行為,只看物品本身的屬性和使用者的偏好歷史。以電影推薦為例:每部電影有屬性向量(類型:動作、喜劇;導演;演員;年代;語言);使用者的「偏好 Profile」是根據其評分歷史計算的加權平均屬性向量;推薦時找出屬性向量和使用者 Profile 最相似的未評分電影。
內容式過濾的優點是不依賴其他使用者的資料——即使這個使用者是平台的第一個使用者,只要他看過幾部電影並有評分,就能推薦類似的電影。這讓它對解決「新使用者冷啟動問題」部分有效(只需要少量行為就能建立偏好 Profile)。缺點是過於狹隘:如果使用者只看過動作片,系統永遠只推薦動作片,無法發現他其實也可能喜歡驚悚片(動作驚悚類型交叉);此外,物品屬性需要人工定義和標注,對複雜內容(音樂的「韻味」、文章的「語氣」)難以用屬性向量完整描述。
深度學習推薦:捕捉複雜的使用者行為
傳統的協同過濾和矩陣分解是線性模型——它們能捕捉「使用者偏好某個潛在因子」和「物品具有該因子」的線性關係,但無法捕捉更複雜的非線性交互(如「在工作日傍晚、在台北、手機上看到這類廣告的使用者,點擊率會顯著提高」)。深度學習的引入讓推薦系統能處理這類複雜特徵。
YouTube DNN(2016):YouTube 在 2016 年公開了其深度推薦系統,第一階段用一個深度神經網路從數百萬影片中召回幾百個候選影片,第二階段用另一個更深的網路對候選影片排序。輸入特徵包括使用者的歷史觀看影片 embedding、搜尋關鍵字 embedding、地理位置、設備類型、當前時間等,輸出是預測的使用者對每部影片的觀看機率。
Wide & Deep(Google, 2016):同時使用「Wide」(線性模型,捕捉記憶效應:使用者過去安裝過 A 類 App,就繼續推 A 類)和「Deep」(深度神經網路,捕捉泛化效應:使用者的潛在興趣模式),兩者聯合訓練,在 Google Play App 推薦上效果優於單獨使用任一種。
DIN(深度興趣網路,阿里, 2018):引入注意力機制,在推薦一個目標物品時,不同等地處理使用者的所有歷史行為,而是動態地根據目標物品,對歷史行為中最相關的那些給予更高注意力權重(推薦運動鞋時,更多關注使用者的運動品類購買歷史,而非護膚品購買歷史)。這讓推薦在「使用者興趣多樣、不同目標物品激活不同興趣」的場景下更精準。
冷啟動與多樣性:推薦系統的設計難題
冷啟動問題(Cold Start Problem) 是所有推薦系統都必須面對的挑戰:新使用者(剛註冊,沒有任何行為資料)和新物品(剛上架,還沒有任何評分)要怎麼推薦?
解決新使用者冷啟動的常見策略:注冊流程問卷(讓使用者在開始時選擇幾個感興趣的類別或代表性物品,建立初始 Profile)、基於人口統計的推薦(年齡、性別、地理位置等人口屬性推斷初始偏好)、熱門物品推薦(先推人氣最高的物品,品質有保證,收集到行為資料後再個人化)。
解決新物品冷啟動的常見策略:內容式推薦橋接(用新物品的屬性向量找到相似的現有物品,利用現有物品的評分歷史推測新物品的受眾)、探索預算(為新物品分配一定比例的曝光機會,即使預測分數低,也要讓它獲得足夠曝光以收集真實的使用者回饋,這是多臂吃角子老虎機 Multi-armed Bandit 思路的應用)。
過濾泡泡(Filter Bubble) 是推薦系統帶來的重要社會議題:當推薦系統越來越精準地「投其所好」,使用者接觸到的內容越來越同質化,政治傾向的人只看到強化自身觀點的新聞,消費者只被推薦特定價格帶的商品。YouTube 的研究和台灣媒體觀察者的報告都指出,演算法推薦有助長「同溫層」效應的風險。負責任的推薦系統設計應引入多樣性機制(Diversity Mechanism):確保推薦列表中包含一定比例的「探索性內容」(使用者未必習慣但可能有興趣的新領域)、提供使用者對推薦演算法的控制(如「不想再看這類內容」)、以及對推薦邏輯保持透明(「因為你上次看了 X,所以推薦 Y」)。
應用場景
| 場景 | 推薦方法 | 核心訊號 | 商業目標 |
|---|---|---|---|
| 串流影音(Netflix、Disney+) | 矩陣分解 + 深度學習排序 | 觀看時長、完播率、明確評分 | 提升留存率、降低流失率 |
| 電商商品推薦(蝦皮、PChome) | Item-based CF + 深度學習 + 廣告競價 | 點擊、加購物車、購買、搜尋詞 | 提升客單價、GMV(交易總額) |
| 音樂串流(Spotify、KKBOX) | 協同過濾 + 音訊特徵內容式過濾 | 播放、跳過、收藏、播放清單 | 探索新歌、留存付費用戶 |
| 新聞和社群媒體動態 | 深度學習 + 即時特徵 | 閱讀時間、分享、留言、點讚 | 增加用戶黏性(需防止泡泡化) |
| 求職平台人才推薦 | 內容式 + 協同過濾混合 | 履歷技能匹配、過去職缺瀏覽 | 提升媒合成功率 |
| 外送平台(UberEats、foodpanda) | 即時情境感知推薦 | 位置、時間、天氣、過去訂單 | 提升轉換率、單次訂單金額 |
| 線上課程(Coursera、Hahow) | 學習路徑推薦 | 完課率、測驗成績、證書目標 | 提升學習完成率和課程購買 |
常見誤區
誤區 1:「推薦系統的目標是讓使用者喜歡推薦的內容,準確率越高越好」
高準確率的推薦不等於好的推薦系統,甚至可能是壞的推薦系統。如果一個使用者每天都看愛情小說,一個「準確率 100%」的推薦系統就會不斷給他推愛情小說——使用者確實不會討厭,但這讓他永遠無法發現自己可能也喜歡的科幻小說或歷史傳記。推薦系統真正的目標應該是長期使用者滿意度和平台整體健康,這需要平衡三個維度:精準性(推薦使用者現在就喜歡的)、多樣性(推薦使用者可能喜歡但尚未接觸的新領域)、新穎性(不要每次都推使用者已經看過類似的東西)。Amazon 的推薦研究發現,加入「意外驚喜(Serendipity)」元素的推薦列表(有一兩個使用者意想不到但實際上喜歡的物品),反而能提升整體使用者滿意度評分,即使個別推薦的「準確率」略低。
誤區 2:「協同過濾只需要使用者評分資料,不需要了解物品本身的內容」
純協同過濾確實不需要物品內容資訊,但在實務中這是重大的系統脆弱性。當物品是新上架時(沒有任何評分),協同過濾完全無法推薦它,這對平台的商業利益傷害極大(新商品、新影片、新歌曲都需要冷啟動曝光機會)。當物品屬性資訊豐富(類型、作者、風格、標籤)時,整合內容資訊的混合推薦(Hybrid Recommendation) 幾乎在所有場景都優於純協同過濾:對老物品用協同過濾(有足夠評分資料),對新物品用內容式過濾(用屬性找類似物品的受眾),根據物品「成熟度」自動切換或混合兩種方法的比例。Spotify 的 Discover Weekly 就是協同過濾(找到口味相似的人喜歡的歌)加上音訊特徵分析(確保推薦的歌在聲音風格上也接近),兩者結合才達到高滿意度。
誤區 3:「推薦系統優化了點擊率,就是對使用者有價值」
點擊率(CTR)是推薦系統最常用的優化指標,但它是一個容易被操縱的短視指標。聳人聽聞的標題、刺激性的圖片、製造好奇的標題黨,都能提升點擊率,但使用者點進去看完之後感到失望(低完播率、低評分、點「不喜歡」)。長期下來,優化 CTR 的推薦系統可能系統性地推薦低品質但高誘惑力的內容,損害使用者對平台的信任。業界已逐漸轉向多目標優化:同時優化點擊率、完播率(Completion Rate)、滿意度評分(Post-watch Satisfaction Survey)、長期留存率(30 天留存、90 天留存)。YouTube 在 2016 年公開報告了從「最大化點擊率」轉向「最大化觀看時間」的推薦策略轉變,後來又進一步轉向包含滿意度調查的多目標優化,以避免推薦系統走向「聳動化」。台灣平台在設計推薦評估指標時,應避免只看短期點擊指標,否則推薦系統可能逐漸「訓練」使用者只關注刺激性內容。
小練習
練習 1:選擇推薦策略
你是一個新創電商平台的 AI 工程師,平台剛上線三個月,目前狀態如下:
- 使用者數量:5,000 名
- 商品數量:200,000 件
- 每個使用者平均購買記錄:3.2 筆(極少數重度使用者有 20+ 筆,大多數只有 1–2 筆)
- 每件商品平均被購買次數:0.13 次(大多數商品從未被購買,即嚴重的長尾效應)
請回答:
- 在這個資料量和稀疏度下,直接套用矩陣分解有什麼問題?
- 你建議採用哪種推薦策略?請說明混合方案及其理由。
- 三個月後,平台成長到 50 萬使用者、購買記錄充足,你的推薦策略應該如何演進?
查看答案
**1. 直接套用矩陣分解的問題:** 矩陣分解需要足夠的評分/購買資料才能學習到有意義的潛在因子。目前 5,000 名使用者 × 200,000 件商品 = 10 億個配對,但只有 5,000 × 3.2 = 16,000 筆購買記錄,稀疏率高達 99.998%。在這麼稀疏的矩陣上,矩陣分解幾乎無法學到有意義的使用者和商品潛在向量——大多數使用者和商品之間根本沒有任何共同購買連結,相似度計算沒有依據。強行套用矩陣分解會產生推薦品質很差(等同於隨機推薦)甚至完全無法收斂的結果。 **2. 早期階段建議的混合策略:** **主力:基於商品屬性的內容式過濾**(因為不依賴使用者互動資料) - 為每件商品建立屬性向量(類別、品牌、價格區間、材質、關鍵詞標籤) - 使用者購買商品 A 後,推薦屬性向量最相近的商品 B、C、D - 優點:不需要大量交易資料,商品上架後立即可推薦 **輔助:熱門商品推薦**(解決新使用者冷啟動) - 對購買記錄少於 3 筆的使用者,加入一定比例(30%–50%)的全站熱銷商品 - 確保推薦有最基本的品質保底(熱銷商品品質通常有保障) **增強:搜尋行為協同過濾**(充分利用稀缺的互動資料) - 購買記錄少,但點擊和搜尋記錄相對豐富,把這些隱式回饋也納入相似度計算 - Item-based CF 基於「同一個使用者看過的商品組合」而非「購買」,降低對顯式評分的依賴 **3. 50 萬使用者後的演進方向:** - 購買資料充足後,引入**矩陣分解或深度學習推薦模型(Wide & Deep 架構)**,能捕捉使用者的潛在個人化偏好,超越單純的商品屬性相似度 - 加入**即時特徵**:使用者當前 Session 的瀏覽行為(過去半小時看了什麼)應該對推薦有更高的即時影響力,而不只依賴歷史購買記錄 - 建立**兩階段系統**(業界標準):第一階段「召回」——從 20 萬件商品快速過濾出幾百件候選(用多個並行的輕量模型:CF 召回、內容式召回、熱門召回);第二階段「精排」——用深度學習模型對幾百件候選品精確預測點擊率和轉換率,輸出最終推薦列表 - 定期 A/B 測試,評估新推薦策略對**GMV、客單價、30 天留存率**的影響,而非只看點擊率練習 2:推薦系統的倫理設計
台灣某大型新聞 App 的推薦系統,長期以最大化「日活躍使用時間(DAU Minutes)」為優化目標。以下是三個觀察到的問題,請為每個問題提出具體的設計修正建議:
| 問題 | 具體現象 | 你的修正建議 |
|---|---|---|
| A. 過濾泡泡加劇 | 使用者 A 在 2024 總統大選前,推薦的新聞 90% 都是支持特定陣營的觀點,另一方觀點從未出現 | ? |
| B. 標題黨惡化 | 推薦系統長期偏好「震驚!」「你不知道的真相!」類標題,有較高點擊率但使用者看後滿意度低 | ? |
| C. 健康使用失衡 | 部分使用者連續使用 App 超過 4 小時,焦慮情緒因不斷推送聳動新聞而上升,但 DAU 指標仍然好看 | ? |