M08.02|描述性統計:用數字說故事的基本功
平均數會騙人、中位數更誠實 — 統計素養是資料分析的地基
本講學習重點
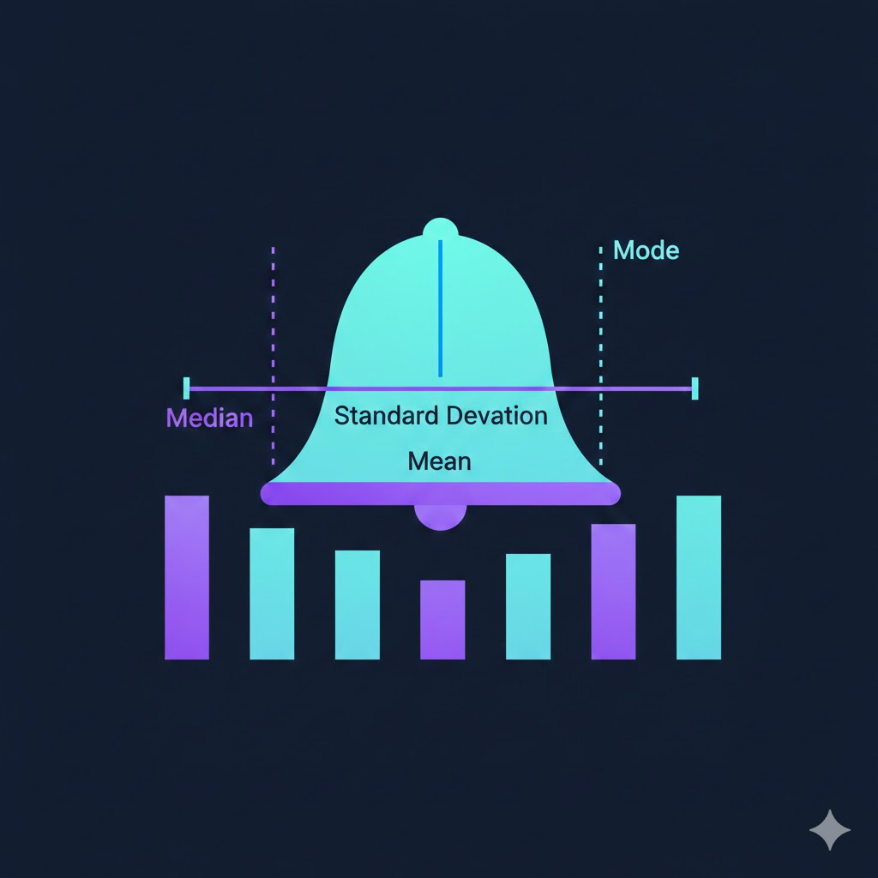
集中趨勢:平均數(受離群值影響大)、中位數(穩健)、眾數(類別資料)
離散程度:標準差(SD)、變異數(Variance)、四分位距(IQR,中位數上下 25% 的範圍)
五數概要:最小值、Q1(25%)、中位數(50%)、Q3(75%)、最大值
偏態(Skewness):右偏(正偏)平均數 > 中位數 > 眾數;左偏(負偏)相反
常態分佈:68% 資料在 ±1σ、95% 在 ±2σ、99.7% 在 ±3σ(68-95-99.7 法則)
離群值識別:IQR 法(超過 Q3+1.5IQR 或低於 Q1-1.5IQR)、Z-score 法(|Z|>3)
描述性統計是 EDA(探索式資料分析)的第一步,先看整體分佈再看細節
🎙️ Podcast(中文)
一句話搞懂
描述性統計是把一大堆數字壓縮成幾個關鍵數字的技術——平均數告訴你中心在哪、標準差告訴你資料多分散、中位數在資料偏斜時比平均數更誠實——這些基本功看似簡單,卻是 AI 資料前處理和業務指標解讀最容易出錯的地方。
白話解說
平均數為何會騙人
假設一家新創公司有十位員工,月薪如下:八位工程師各 6 萬元,一位資深工程師 9 萬元,以及創辦人 60 萬元。把所有薪資加總除以十,平均月薪是 11.7 萬元。如果你是應聘者,看到「平均薪資 11.7 萬元」,你會以為大多數人都拿十幾萬——但現實是八位工程師只拿 6 萬,只有一位創辦人拉高了整體平均。
這就是算術平均數(Arithmetic Mean)最著名的弱點:對離群值(Outlier)極度敏感。一個極端值能把平均數拉到完全失去代表性的位置。在這個例子中,更誠實的指標是中位數(Median)——把十個數字從小排到大,取第五和第六個數字的平均值,結果是 6 萬元,這才是典型員工薪資的真實反映。中位數之所以穩健(Robust),是因為它只看位置、不看數值大小,一個極端的創辦人薪資改變了平均,但對中位數幾乎沒有影響。
在資料分析和 AI 應用中,分辨何時用平均數、何時用中位數,是基本的統計素養。房價、個人收入、網站頁面載入時間、廣告點擊數這類右偏分佈的資料,中位數永遠比平均數更能反映典型使用者的真實體驗。
標準差:衡量「分散程度」的尺
光知道平均或中位數還不夠——同樣是「平均月薪 6 萬」的兩家公司,一家可能所有人都拿 6 萬(非常均等),另一家可能有人拿 3 萬有人拿 9 萬(差異極大)。這時候需要離散程度(Dispersion)的指標。
標準差(Standard Deviation, SD 或 σ)是最常用的離散程度指標。直觀理解:標準差就是「資料點平均距離均值多遠」。如果一班學生數學成績的平均是 70 分,標準差是 5 分,表示大多數人的成績在 65–75 分之間,非常集中;如果標準差是 20 分,表示成績從 50 到 90 分都有,分散程度很大。
68-95-99.7 法則是理解標準差最重要的直覺:對於服從常態分佈(Normal Distribution,也叫高斯分佈)的資料,約 68% 的資料落在均值 ±1 個標準差內(μ±σ),約 95% 落在 ±2σ 內,約 99.7% 落在 ±3σ 內。這個法則在機器學習中無處不在——模型的預測誤差、神經網路的權重初始化、異常偵測的閾值設定,都建立在這個框架上。
四分位距(Interquartile Range, IQR)是另一個衡量離散程度的指標,且和中位數一樣,對離群值有更強的抵抗性:IQR = Q3(第 75 百分位數)- Q1(第 25 百分位數),代表中間 50% 資料的分散範圍。箱形圖(Box Plot)就是把五數概要(最小值、Q1、中位數、Q3、最大值)視覺化的標準工具,是探索式資料分析(EDA)的必備圖表。
偏態:分佈不對稱的世界
真實世界的資料很少是完美對稱的常態分佈,更常見的是各種形狀的偏斜分佈(Skewed Distribution)。
右偏(正偏)分佈:分佈的尾巴在右邊,有少數極大值把均值拉高,使得均值 > 中位數 > 眾數。社會中的財富分佈、企業的營收分佈、城市的房價分佈、網路影片的觀看次數——這些都是典型的右偏分佈。一個影片可能有一億次觀看,但絕大多數影片只有幾百次。在 AI 應用中,右偏資料如果直接用於訓練,模型往往會過度關注那少數的極端值(因為它們的數值大,對均方誤差損失函數的貢獻也大),常見的處理方式是對資料取對數(Log Transformation),把極端的長尾壓縮到更對稱的分佈。
左偏(負偏)分佈:尾巴在左邊,有少數極小值把均值拉低,均值 < 中位數 < 眾數。例如,班級考試成績如果題目太簡單(大多數人接近滿分,少數人考得很差),就會出現左偏分佈。
偏態係數(Skewness)是量化偏斜程度的指標:正值表示右偏,負值表示左偏,接近 0 表示接近對稱。在 AI 資料前處理時,發現偏態係數的絕對值大於 1,通常就需要考慮資料轉換(對數、平方根、Box-Cox 轉換)以改善模型的學習效率。
描述性統計在 AI 中的角色
描述性統計不是只在學術報告裡用的工具——它是機器學習工作流程的第一步,也是發現資料問題最有效的方法。
在資料前處理階段,計算每個特徵(Feature)的描述性統計是標準操作:最大值/最小值可以發現不合理的資料(年齡 = -5 歲,或身高 = 999 cm 這類輸入錯誤);標準差為 0 或接近 0 的特徵表示該欄位對所有樣本幾乎相同,對模型沒有鑑別力,應考慮刪除;缺失值比例決定是否需要插補(Imputation)或直接捨棄該特徵;分佈形狀(偏態)決定是否需要資料轉換,以確保線性迴歸等對分佈有假設的模型能正確運作。
在模型評估階段,描述性統計同樣不可或缺:一個模型在測試集上的平均誤差只是開始,還需要看誤差的標準差(是否穩定)、最大誤差(最壞情況是什麼)、誤差分佈的偏態(是否系統性地高估或低估)。這些統計量共同構成了對模型性能更全面的評估。
應用場景
| 場景 | 使用的統計工具 | 分析目的 | 注意事項 |
|---|---|---|---|
| 電商商品評分分析 | 平均分 vs 中位數 vs 評分分佈圖 | 了解商品整體口碑,識別兩極化評價 | 只看平均分可能掩蓋「好評和差評各半」的兩極化商品 |
| 工廠產品品質管控(SPC) | 均值 + 標準差 + 管制圖 | 監控生產過程是否在統計控制內 | 正態分佈假設是否成立,需要驗證 |
| 用戶使用時長分析 | 中位數 + 百分位數(P75/P90/P99) | 了解典型和極端用戶的體驗 | 右偏分佈中平均時長被重度用戶拉高,不代表一般用戶 |
| 薪資市場調查報告 | 中位數 + 四分位距(IQR)+ 箱形圖 | 呈現薪資分佈,避免高薪者扭曲平均 | 需說明樣本來源和是否具有代表性 |
| 機器學習特徵篩選 | 變異數、相關係數、偏態係數 | 刪除低變異特徵,識別需要轉換的偏斜特徵 | 統計顯著性 ≠ 業務重要性 |
| 網頁伺服器效能監控 | P95/P99 響應時間(百分位數) | 了解極端延遲情況,SLA 合規性判斷 | 平均響應時間良好但 P99 很高表示有嚴重長尾問題 |
| 醫學臨床試驗報告 | 均值±標準差(常態分佈)或中位數±IQR(偏態分佈) | 標準化報告實驗結果 | 必須先檢驗資料是否符合常態分佈,選對指標 |
常見誤區
誤區 1:「報平均數就夠了,不需要其他統計量」
在業務報告中只報平均數是危險的習慣,因為平均數只告訴你一個維度,隱藏了分佈的真實形狀。兩個產品的平均評分都是 4.0 分(滿分 5 分),但一個的評分分佈可能是 80% 給 4 分、20% 給 3-5 分之間(穩定的好評),另一個可能是 40% 給 1 分(非常不滿意)+ 60% 給 5 分(非常喜歡),這種兩極化分佈(Bimodal Distribution)用平均數完全看不出來。在業務分析和 AI 模型評估中,至少要同時報告:代表性的集中趨勢指標(視分佈形狀選擇均值或中位數)+ 代表性的離散指標(標準差或 IQR)+ 分佈的形狀(用直方圖或箱形圖視覺化)。三者合在一起才能講出資料完整的故事。
誤區 2:「離群值一定要刪掉,否則會影響分析」
離群值(Outlier)在統計上的定義通常是「落在 Q1-1.5×IQR 以下或 Q3+1.5×IQR 以上」或「Z-score 絕對值大於 3」的資料點。但「是離群值就必須刪掉」這個直覺是錯誤的。離群值可能是三種情況之一:(1)資料輸入錯誤(應該刪除或修正);(2) 合理的極端值(不應刪除,例如超級大客戶的訂單金額確實是普通客戶的 100 倍,但這是真實的業務現象);(3) 最重要的信號(在詐欺偵測、製造業缺陷檢測、醫療異常診斷中,離群值正是你最想找到的目標)。正確做法是先調查離群值的成因,再決定如何處理——刪除、修正、或保留並特別對待(如分開建模)。盲目刪除離群值可能反而讓模型在真正重要的邊界案例上失效。
誤區 3:「標準差越小,資料品質越好」
這個誤解混淆了資料品質和資料分散程度兩個完全不同的概念。標準差衡量的是資料的變異性,變異性高低本身沒有好壞之分——完全取決於業務背景。一個精密製造的零件,尺寸標準差 0.01 mm 是高品質(公差要求嚴格);但一個使用者行為資料集(如不同用戶的每日登入次數),標準差大反映的是使用者族群的多樣性,這本身是有意義的資料特徵,而不是資料品質問題。資料品質(Veracity)的衡量指標是準確性(數值是否正確)、完整性(缺漏值比例)、一致性(不同系統間的定義是否統一),這些和標準差沒有直接關係。把「標準差小」等同於「資料好」是統計入門者最常見的概念混淆。
小練習
練習 1:選擇正確的統計指標
以下是五個不同業務場景,請為每個場景選擇最適合的集中趨勢指標(平均數/中位數/眾數),並解釋理由:
- 報告台灣 2025 年家庭年收入的「典型水準」
- 計算一批手機電池續航時間測試的「平均表現」(測試條件嚴格控制,數據正態分佈)
- 電商平台統計「最受歡迎的商品尺碼」(S/M/L/XL)
- 分析 AI 客服機器人每次回應的時間延遲(大多數回應在 200ms 內,但偶爾有 10 秒的超時)
- 報告上市公司的「代表性市值」(台積電市值是大多數公司的數千倍)
查看答案
**1. 台灣家庭年收入 → 中位數** 台灣家庭年收入分佈是明顯的右偏分佈(少數高收入家庭拉高平均)。根據主計處資料,台灣家庭年收入平均數長期比中位數高出 20-30%,用平均數會讓大眾誤以為典型家庭收入比實際高。政府政策分析、社會研究報告,以及比較不同國家生活水準,應一律使用中位數家庭收入。 **2. 電池續航測試 → 平均數(算術均值)** 題目已說明測試條件嚴格控制、數據正態分佈,這正是算術平均數最合適的使用情境。正態分佈下,均值 = 中位數 = 眾數,三者一致,使用均值是統計標準做法,也方便後續計算標準差(均值 ± 標準差是正態分佈的標準報告格式)。 **3. 最受歡迎的尺碼 → 眾數** 尺碼(S/M/L/XL)是類別資料(Categorical Data),根本無法計算平均數或中位數(「平均尺碼」是沒有意義的概念)。眾數是類別資料唯一適用的集中趨勢指標。電商的庫存備貨決策,就是根據銷售量的眾數(最多人買的尺碼)來調整備貨比例。 **4. AI 客服回應延遲 → 中位數或 P95(第 95 百分位數)** 描述「典型表現」用中位數(對偶發的 10 秒超時有抵抗性);描述「用戶體驗的最壞情境」用 P95 或 P99(95% 或 99% 的請求在多少毫秒內完成)。只報平均延遲完全無法反映這種高度右偏的延遲分佈——平均可能是 250ms,但 P99 是 8 秒,意味著每 100 個用戶中就有一個人等了 8 秒,這在 SLA(服務等級協議)中是不合格的。 **5. 上市公司代表性市值 → 中位數** 台積電的市值約是台灣多數上市公司的幾千倍,是一個極端的離群值,會嚴重拉高平均市值。如果用平均市值來代表「一家台灣上市公司的典型規模」,99% 的公司都遠低於這個平均值,這個指標完全失去代表性。中位數市值能反映「位居中間的那家公司有多大」,是更有意義的基準點。練習 2:用描述性統計找出資料問題
以下是一份電商平台的「用戶購買金額」資料集的描述性統計摘要,請根據這些數字回答問題:
| 統計量 | 數值 |
|---|---|
| 筆數 | 10,000 |
| 最小值 | -500 元 |
| Q1(25%) | 280 元 |
| 中位數(50%) | 650 元 |
| Q3(75%) | 1,200 元 |
| 最大值 | 9,800,000 元 |
| 平均數 | 4,300 元 |
| 標準差 | 98,500 元 |
- 從這份統計摘要中,你可以發現哪些潛在的資料品質問題?
- 這份資料的偏態方向是?
- 如果要用這份資料訓練一個「預測用戶購買金額」的迴歸模型,在資料前處理上你會做哪些處理?