M08.06|機器學習管線中的資料處理
從原始資料到模型輸入 — 分散式框架讓大規模資料不再是瓶頸
本講學習重點
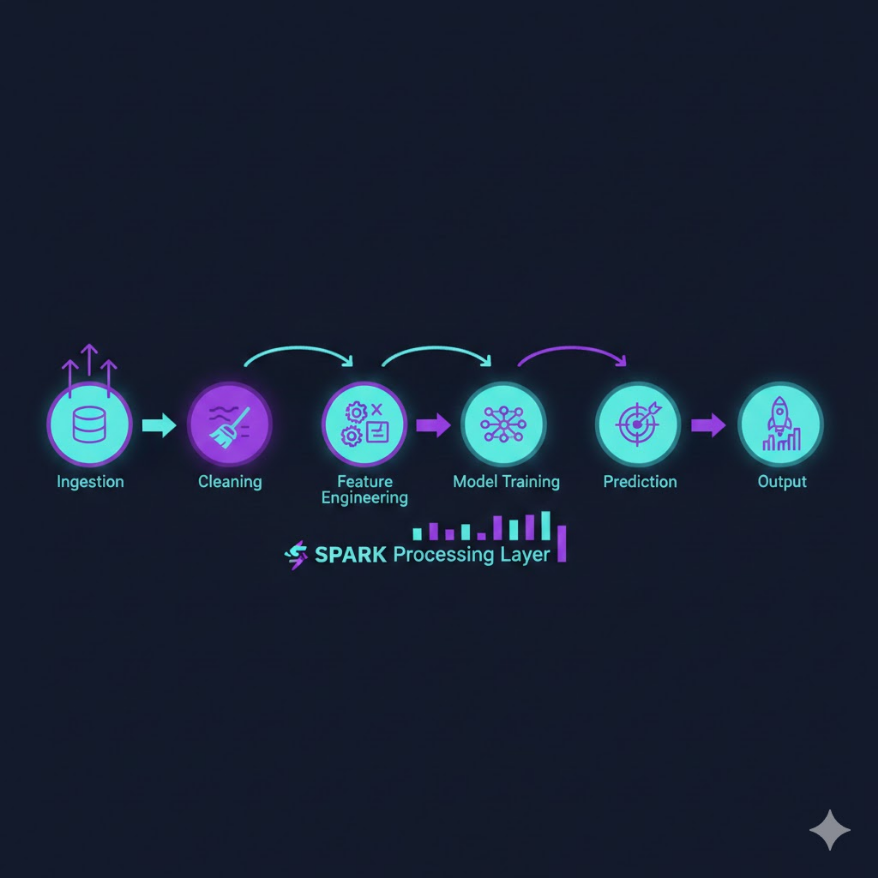
ML 管線 = 資料擷取 → 清洗 → 特徵工程 → 特徵儲存 → 模型訓練/推論,每個步驟必須可重複、可版本控制
Spark:JVM-based,適合 PB 級批次處理,強在 SQL 風格操作;Dask:Python-native,適合 TB 級,API 和 Pandas/NumPy 相容,學習曲線低
特徵工程:標準化(Z-score)、正規化(Min-Max)、類別編碼(One-Hot、Target Encoding)、交叉特徵、時間衍生特徵
Training-Serving Skew:訓練時的特徵轉換邏輯和推論時的不一致,是線上模型表現比離線評估差的最常見原因
特徵儲存(Feature Store):集中管理特徵定義和計算邏輯,確保訓練和推論使用同一份特徵,Feast、Tecton 是主流選擇
資料漂移(Data Drift):輸入資料的統計分佈隨時間變化(如用戶行為改變),是模型效能下降的主因之一
管線自動化工具:Apache Airflow(調度)、MLflow(實驗追蹤)、DVC(資料版本控制)
🎙️ Podcast(中文)
一句話搞懂
機器學習管線(ML Pipeline)是把「原始資料」自動轉換成「模型可以使用的特徵」的流水線——當資料量大到一台電腦裝不下、處理不完時,就需要 Spark 或 Dask 這類分散式框架,把計算工作分攤給數十台甚至數百台機器;管線的核心挑戰不只是速度,而是確保從資料擷取、清洗、特徵計算,到模型訓練和線上推論的每個步驟都完全一致、可重複、可追蹤,因為任何一個環節的不一致都可能導致模型在真實環境中表現遠不如預期。
白話解說
什麼是 ML 管線,為什麼需要它
想像一家銀行要訓練一個信用評分模型,原始資料包括:1 億筆交易紀錄(每筆有時間、金額、商家類別等 20 個欄位)、500 萬個客戶的基本資料、3 年的還款歷史。這些資料光存下來就需要幾十 TB,更不用說要進行清洗、計算衍生特徵(如「最近 30 天的平均消費額」「近半年的拒絕付款次數」),然後才能送進模型訓練。
如果只是一次性地把這些工作在筆電上跑一遍,技術上可行,但問題是:模型要持續更新(每周用新資料重訓)、新客戶要即時評分(幾百毫秒內必須給出分數),這就要求整個資料處理流程必須是自動化的、可重複執行的、線上和離線結果一致的。這就是機器學習管線的核心價值。
ML 管線通常包含以下幾個主要階段:
- 資料擷取(Data Ingestion):從多個資料來源(資料庫、日誌系統、第三方 API)把原始資料拉入統一的資料湖(Data Lake)。
- 資料清洗(Data Cleaning):處理缺失值、異常值、重複資料、格式錯誤。
- 特徵工程(Feature Engineering):把清洗後的原始資料轉換為模型可以直接使用的數值特徵。
- 特徵儲存(Feature Store):把計算好的特徵存入統一的特徵庫,供訓練和推論共用。
- 模型訓練(Model Training):用整理好的特徵訓練模型,記錄實驗參數和評估指標。
- 模型部署與推論(Serving):把模型部署到線上,對新的請求即時(或批次)產生預測結果。
每個步驟都必須版本化(知道用的是哪個版本的資料和程式碼)、可觀測(有日誌和監控)、可觸發(可以手動或自動按排程執行)。
分散式框架:Spark 和 Dask
當資料量超出單機的記憶體和運算能力時,就需要分散式框架把工作分攤給多台機器。Apache Spark 和 Dask 是 ML 管線中最常用的兩種選擇。
Apache Spark 誕生於 2009 年的 UC Berkeley,最初是為了解決 Hadoop MapReduce 每次操作都要寫磁碟的效能問題。Spark 的核心設計是把資料保存在各節點的記憶體中(RDD,Resilient Distributed Dataset),大幅加速了反覆讀取同一份資料的迭代運算(這在機器學習訓練中非常常見)。Spark 的 DataFrame API(和 Spark SQL)提供了類似關聯式資料庫的查詢介面,讓資料工程師可以用熟悉的 SQL 風格操作 PB 級的資料。Spark 的生態系包含 MLlib(機器學習庫)、Spark Streaming(流式處理)和 GraphX(圖計算),是企業大數據平台(Databricks、Azure HDInsight、Amazon EMR)的主流選擇。
PySpark 是 Spark 的 Python API,讓資料科學家可以用 Python 語法操作 Spark:
from pyspark.sql import SparkSession
from pyspark.ml.feature import StandardScaler, VectorAssembler
spark = SparkSession.builder.appName("MLPipeline").getOrCreate()
# 讀取 HDFS 上的大型資料集
df = spark.read.parquet("hdfs://data/transactions/*.parquet")
# 特徵工程:計算每個客戶的 30 日平均消費
from pyspark.sql.functions import avg, col
from pyspark.sql.window import Window
window_30d = Window.partitionBy("customer_id").orderBy("date").rangeBetween(-30, 0)
df = df.withColumn("avg_spend_30d", avg("amount").over(window_30d))
Dask 是一個更年輕(2015 年)、更 Python-native 的分散式框架。它的最大優勢是 API 設計幾乎完全對應 Pandas(DataFrame)和 NumPy(Array),讓原本在本地跑 Pandas 的程式幾乎不需要改動就能擴展到叢集:
import dask.dataframe as dd
# 讀取數百個 CSV 分片,自動並行化
df = dd.read_csv("s3://data/logs/2024-*.csv")
# API 幾乎和 Pandas 相同
result = df.groupby("user_id")["session_duration"].mean().compute()
如何選擇? 規模在 TB 級以上、需要流式處理、或在 Databricks 等 Spark 雲端平台上工作,選 Spark;規模在幾十 GB 到幾個 TB 之間、團隊主要使用 Python/Pandas、或需要把現有 Pandas 程式碼快速擴展,選 Dask。
特徵工程:讓原始資料變成模型的語言
特徵工程是 ML 管線中對最終模型效果影響最大的環節。常見的特徵工程技術包括:
數值特徵處理:
- 標準化(Standardization,Z-score):把每個特徵轉換為均值 0、標準差 1 的分佈。適用於假設正態分佈的模型(如線性回歸、SVM)。
- 正規化(Normalization,Min-Max):把特徵縮放到 [0, 1] 範圍。適用於神經網路和 KNN。
- 冪次轉換(Box-Cox、Log Transform):對高度偏斜的分佈(如收入、商品價格)取對數,讓分佈更接近正態。
類別特徵處理:
- One-Hot 編碼:把「顏色:紅/藍/綠」轉換為三個 0/1 的二元特徵。適用於無序類別,但類別數量多時會造成維度爆炸。
- Target Encoding(目標編碼):用每個類別對應的目標變數平均值替代類別標籤(如「城市」替換為「該城市用戶的平均轉換率」)。緊湊且保留了類別和目標的關聯,但需要防止資料洩漏(必須只用訓練集的統計資訊)。
- Embedding:用低維度連續向量表示高基數類別(如用戶 ID、商品 ID),這是深度學習推薦系統的核心技術。
時間衍生特徵:從時間戳記中提取小時、星期幾、是否為假日、距上次購買的天數等,這些特徵在電商、金融、廣告等場景中往往非常重要。
Training-Serving Skew:最隱蔽的管線問題
ML 管線中最常見、也最難排查的問題是 Training-Serving Skew(訓練-推論偏差):訓練時的特徵計算邏輯和線上推論時的特徵計算邏輯不完全一致,導致模型在離線評估時效果很好,但部署上線後表現明顯下降。
常見的導致 Skew 的原因:
- 訓練時用 Python Pandas 計算特徵,推論時用 Java/C++ 重新實現,邊界條件處理不一致(如空值的處理方式)。
- 訓練時對整個資料集做了全局標準化(用全部數據的均值和標準差),推論時卻用了不同時期的統計參數。
- 訓練時用了「未來資料」計算特徵(資料洩漏),推論時不可能有未來資料,導致線上效果遠差於離線評估。
解決 Skew 的最佳實踐是特徵儲存(Feature Store):統一管理特徵的定義和計算邏輯,讓訓練和推論都從同一個特徵庫讀取相同的特徵值,從根本上消除不一致。Feast、Tecton、Hopsworks 是常見的開源和商業 Feature Store 解決方案。
資料漂移監控:管線不只是一次性的
ML 管線建好並不代表可以「一勞永逸」。現實世界的資料分佈會隨時間改變(用戶行為模式改變、市場環境變化、新的資料來源引入),這種現象稱為資料漂移(Data Drift)。當輸入資料的統計分佈與訓練時期的分佈差異過大,模型效能就會下降,這種情況稱為模型退化(Model Decay)。
監控資料漂移的常用方法:
- PSI(Population Stability Index,族群穩定性指數):衡量特徵分佈的變化程度,PSI > 0.2 通常視為需要重新訓練模型的訊號。
- KS 統計量(Kolmogorov-Smirnov Test):比較兩個分佈的最大差異,用於偵測分佈的系統性偏移。
- Evidently AI、WhyLabs 等工具可以自動化地計算並視覺化每個特徵的漂移程度。
應用場景
| 場景 | 資料規模 | 主要挑戰 | 技術選擇 | 注意事項 |
|---|---|---|---|---|
| 電商推薦系統 | 數十億行為日誌(每日) | 即時特徵 vs 批次特徵的混合 | Spark(批次)+ Redis(即時特徵快取) | 用戶和商品的 Embedding 需要定期更新 |
| 金融風控評分 | 數億交易紀錄 | 資料洩漏防護、監管合規 | Spark + Feature Store(Feast) | 特徵計算必須嚴格按時間順序,禁止使用未來資料 |
| 廣告點擊率預測 | PB 級日誌 | 類別特徵基數極高(億級用戶 ID) | Spark + Embedding 壓縮 | 特徵雜湊(Feature Hashing)控制維度 |
| 醫療影像 AI | TB 級 DICOM 影像 | 非結構化資料、資料標注成本高 | Dask 圖像處理 + GPU 叢集 | 資料增強(Augmentation)必須在管線中統一定義 |
| 工廠設備預測維護 | IoT 感測器(每秒多點) | 流式特徵計算、低延遲 | Apache Kafka + Spark Streaming | 感測器缺失值的插補策略對模型影響很大 |
| 自然語言處理管線 | 數億篇文章/評論 | 文字清洗、多語言處理 | Dask + spaCy/Hugging Face | 分詞和前處理的版本必須和推論時完全一致 |
| 信用評分模型 | 多年歷史交易 + 外部徵信 | 特徵時效性、外部資料整合 | Spark + Tecton Feature Store | 訓練時必須重建「申請當時」的特徵快照,避免資料洩漏 |
常見誤區
誤區 1:「模型訓練比資料處理更重要,花大量時間在特徵工程上不值得」
這是初學者最常有的認知誤差。實際上,業界廣泛認同的經驗是:在大多數實際問題中,特徵工程對最終模型效果的貢獻遠大於模型選擇或超參數調整。一個好的特徵工程配合簡單的線性模型,往往比劣質特徵配合複雜的深度神經網路表現更好。
原因在於:機器學習模型本質上是在學習輸入特徵和輸出目標之間的映射關係。如果輸入特徵本身就已經很好地表達了問題的核心資訊(例如,對於信用風險模型,「最近 6 個月的延遲還款次數」這個特徵直接關聯到目標,比原始的每筆交易明細更有資訊量),模型學習起來就更容易,泛化能力也更強。
反之,如果原始特徵沒有經過適當的工程處理(如高度偏斜的收入分佈沒有取對數、類別特徵沒有適當編碼),即使最強大的模型也很難從中提取有用的模式。許多 Kaggle 競賽冠軍的採訪都指出,他們超過 60-70% 的時間花在探索性分析和特徵工程上,模型調參只佔少數。在實際工作中,這個比例可能更高,因為業務特徵往往需要深度的領域知識來設計(例如,電商的「購物車放棄率趨勢」比「加入購物車次數」更有預測力,而設計這樣的特徵需要對業務場景的深入理解)。
誤區 2:「用 Spark 和 Dask 只是為了讓程式跑更快,邏輯上和 Pandas 一樣」
這個誤解會導致在使用分散式框架時犯下嚴重的正確性錯誤,因為分散式運算有一些本質上和單機運算不同的特性,忽視這些特性會讓程式產生錯誤結果:
全局排序問題:在 Pandas 中,df.sort_values("date") 會對整個 DataFrame 按日期排序,之後的 groupby().apply() 可以按正確的時間順序處理每個組。但在 Spark/Dask 中,資料分散在多台機器上,sort_values 只能在每個分區(partition)內部排序,不同分區之間的順序並不保證。計算時間序列特徵(如「前 N 天的滑動平均」)時,必須使用 Window Function 並明確指定分區鍵和排序欄位,而不是靠排序後的位置索引。
UDF 效能陷阱:Spark 的原生操作(map、filter、groupBy)在 JVM 層面執行,效能極高;但如果對每一行呼叫 Python UDF(User Defined Function),需要把資料序列化傳給 Python 程序再傳回,效能可能比原生 Spark 操作慢 10-100 倍。應盡量使用 Spark 的內建函數(pyspark.sql.functions),只在必要時才用 UDF(並考慮使用 Pandas UDF/Arrow 優化)。
惰性求值(Lazy Evaluation):Dask 的所有操作都是「惰性」的——呼叫 df.groupby(...).mean() 時不會立刻執行,只會建立一個計算圖。只有當你呼叫 .compute() 時才會真正執行。這讓 Dask 可以優化整個計算圖,但也意味著中間的錯誤(如型別不符)往往要到 .compute() 時才會爆出,增加了除錯的難度。
誤區 3:「ML 管線建好之後就不需要再維護,讓它自動跑就好」
ML 管線不是「設定完就能忘記」的基礎設施。現實中,管線需要持續的監控和維護,主要面臨以下三類問題:
資料來源的脆弱性:上游資料來源(資料庫 schema 變更、API 格式更新、第三方資料供應商服務中斷)隨時可能導致管線失敗。Netflix 的資料工程團隊曾分享,他們的 ML 管線在一年內因為上游 schema 變更而中斷的次數超過 50 次。必須建立嚴格的資料品質檢查(如 Great Expectations 框架),在資料進入管線之前就驗證關鍵欄位的型別、範圍、完整性,並設置告警。
資料漂移導致的模型退化:即使管線正常運行、資料沒有技術性錯誤,模型的預測效能也可能因為資料分佈的自然變化而逐漸下降。例如,疫情期間用戶的網購行為發生了根本性改變,所有基於疫情前資料訓練的電商推薦模型都出現了明顯的效能下降。必須建立模型監控(追蹤預測分數的分佈、追蹤線上效果指標),並設置自動重訓的觸發機制。
特徵定義的版本管理:隨著業務演進,特徵的計算邏輯可能需要更新(如「最近 30 天」改為「最近 60 天」)。如果沒有嚴格的版本管理,新舊版本的特徵混用會導致模型行為不可預測。必須把特徵定義視為程式碼,用 Git 進行版本控制,並確保每次模型訓練都記錄了使用的特徵版本號。
小練習
練習 1:識別資料洩漏問題
一個電商平台的資料科學家在訓練「用戶是否會在本次工作階段(Session)完成購買」的預測模型。以下是他設計的部分特徵,請找出哪些特徵存在資料洩漏(Data Leakage),並解釋原因:
- 該用戶過去 30 天的總購買金額
- 本次工作階段中已加入購物車的商品總金額
- 本次工作階段中已完成的頁面瀏覽數(截至預測時刻)
- 本次工作階段中的訂單確認頁面是否被訪問過
- 用戶的會員等級(白金、黃金、一般)
- 本次工作階段的結束時間(工作階段結束後計算的總時長)
練習 2:設計信用風控的特徵工程方案
假設你是一家 P2P 借貸平台的資料科學家,要為「貸款申請人 12 個月內是否會違約」建立預測模型。你手中有以下原始資料:
- 申請表資料:年齡、職業、月收入、月支出、貸款金額、貸款用途
- 銀行帳戶資料(過去 24 個月):每月入帳金額、每月支出金額、最低餘額
- 信用卡資料(過去 12 個月):每月刷卡金額、繳款狀況(全額/最低/逾期)
- 貸款歷史:過去 5 年曾申請或還清的貸款紀錄
請為每個資料來源設計至少 2 個有意義的衍生特徵,並說明為什麼這個特徵對違約預測有幫助。
查看答案
**練習 1:識別資料洩漏** - **特徵 1(過去 30 天總購買金額)**:無洩漏。這是「過去」的歷史資訊,在預測時刻是已知的,可以合法使用。 - **特徵 2(本次工作階段已加入購物車的金額)**:**可能有洩漏**,需要確認時間點。如果是「預測時刻之前」加入購物車的金額,沒有洩漏;如果包含了預測時刻之後(例如本次工作階段結束前)才加入的商品,就存在洩漏。 - **特徵 3(截至預測時刻的頁面瀏覽數)**:無洩漏,明確說明是「截至預測時刻」的資料。 - **特徵 4(訂單確認頁面是否被訪問過)**:**嚴重洩漏**。訂單確認頁面只有在購買完成後才會被訪問,如果目標是「是否完成購買」,那麼「訪問確認頁面」和「完成購買」幾乎是同一件事——這個特徵直接洩漏了答案。 - **特徵 5(會員等級)**:無洩漏。會員等級是用戶當前的靜態屬性,在預測時刻是已知的。 - **特徵 6(工作階段結束時間計算的總時長)**:**嚴重洩漏**。工作階段的「總時長」只有在工作階段結束後才能計算,而工作階段結束的時間點是在「是否購買」事件發生之後。在預測「是否購買」的時刻,工作階段還沒結束,這個特徵根本不可能存在。 **資料洩漏的整體教訓**:設計特徵時,必須嚴格站在「做出預測的那個時刻」的視角,只使用在那個時刻之前已知的資訊。任何需要「知道未來」才能計算的特徵都存在洩漏。 --- **練習 2:信用風控特徵工程方案** **來自申請表資料的衍生特徵**: - **債務收入比(Debt-to-Income Ratio)= 月支出 / 月收入**:月收入 3 萬、月支出 2.7 萬的申請人比月收入 3 萬、月支出 1 萬的申請人風險高得多。這個比率直接衡量申請人的財務壓力程度,是風控模型最重要的特徵之一。 - **貸款金額 / 月收入倍數**:衡量申請人能否負擔這筆貸款的還款壓力。貸款金額等於 20 個月收入的申請人(高槓桿),違約風險遠高於貸款金額等於 3 個月收入的申請人。 **來自銀行帳戶資料的衍生特徵**: - **帳戶餘額波動係數(最近 12 個月餘額的標準差 / 平均值)**:帳戶餘額穩定的申請人(波動小)通常有穩定的收入來源和良好的財務管理習慣,違約風險較低;帳戶餘額大幅波動則可能反映不穩定的收入或衝動消費的模式。 - **收入-支出差額的趨勢**:計算過去 12 個月中每月(入帳 - 支出)的線性回歸斜率。如果每個月的淨現金流在持續下降(斜率為負),說明申請人的財務狀況在惡化,即使當前餘額尚可,未來的還款能力存疑。 **來自信用卡資料的衍生特徵**: - **過去 12 個月中逾期繳款的月份比例**:最直接的違約傾向指標。哪怕只有 1-2 個月逾期繳款,違約率也會顯著提高;如果有 3 個月以上的逾期,違約風險急劇上升。 - **信用卡使用率(刷卡金額 / 信用額度)的 3 個月移動平均**:信用卡使用率持續偏高(>70%)的申請人往往處於財務緊繃狀態,更依賴借貸維持日常開支,這是財務壓力的重要訊號。 **來自貸款歷史的衍生特徵**: - **過去 5 年的貸款還清比例(已還清貸款數 / 曾申請貸款總數)**:衡量申請人的還款紀錄。還清比例高代表有良好的還款習慣。 - **距離上次貸款申請的天數**:短時間內大量申請貸款(「多次信用查詢」)是財務困難的訊號,通常說明申請人在多處尋找資金。練習 2:答案(已包含在上方的 details 區塊中)
請展開上方的「查看答案」閱讀詳細解答。