M09.02|模型版本管理:讓實驗可重現、讓部署有憑有據
你還在用 model_v2_final_REALLY_FINAL.pkl 命名嗎?是時候認真對待模型版本管理了
本講學習重點
DVC = Data Version Control,用 Git 管指針,用物件儲存管大檔案
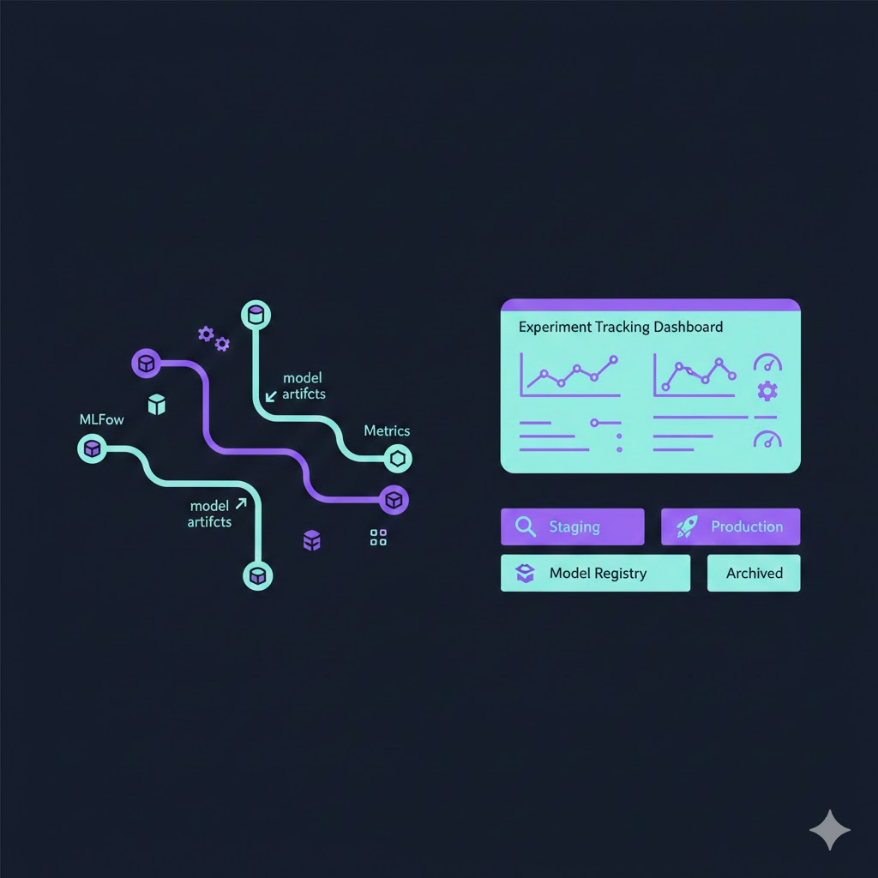
MLflow 四元件:Tracking、Projects、Models、Registry
Model Registry 管模型的生命週期:Staging → Production → Archived
模型血緣追蹤從資料來源到部署模型的完整歷程,確保可審計
W&B 適合深度學習、視覺化豐富;MLflow 適合傳統 ML、自建部署
每次實驗必須記錄:程式碼版本、資料版本、超參數、評估指標
可重現性是 MLOps 的核心價值:6 個月後要能重現任意一次實驗結果
🎙️ Podcast(中文)
一句話搞懂
模型版本管理就是為每一次實驗和每一個部署建立完整的「出生證明」——記錄用了哪些資料、跑了什麼程式、設定了哪些參數、得到了什麼結果,讓你六個月後還能重現當初的模型,也讓團隊知道現在線上跑的模型是從哪裡來的。
白話解說
沒有版本管理的 ML 專案長什麼樣子?
這個場景你或許很熟悉:模型訓練的資料夾裡,躺著一堆這樣的檔案:
model_v1.pkl
model_v2.pkl
model_v2_tuned.pkl
model_v3_final.pkl
model_v3_final2.pkl
model_FINAL.pkl
model_REAL_FINAL.pkl
model_use_this_one.pkl
三個月後,你的主管問:「上線的是哪個版本?」你打開 Slack 找記錄,發現你說了「用 final2」,但同事說他記得最後換成了「REAL_FINAL」。線上的效果比預期差,但你們已經不記得當初用的是哪批訓練資料了。
這就是沒有系統性版本管理的後果:失憶的團隊。每次想要重現或改進,都要從頭來過。
為什麼 ML 的版本管理比一般軟體難?
一般軟體工程師用 Git 就能解決版本控制問題,因為程式碼是純文字,幾 MB 大小,Git 應付得來。
但 ML 系統有三個會同時變動的組件:
程式碼:訓練腳本、預處理邏輯、特徵工程。這個 Git 能管。
資料:訓練資料集、驗證集,動輒幾 GB 甚至幾百 GB。Git 設計上就不適合管大型二進位檔案,推上去會讓 repo 膨脹到無法使用。
模型參數:訓練好的模型檔案,從幾 MB 到幾十 GB 都有。同樣不適合放進 Git。
更麻煩的是,這三者之間有複雜的依賴關係:這個模型是用那批資料、那個版本的程式碼、那組超參數訓練出來的。你需要能追蹤這整個關係圖,這就是模型血緣(Model Lineage)的概念。
DVC:給資料和模型的 Git
DVC(Data Version Control)的設計哲學很聰明:它不直接儲存大型資料或模型檔案,而是用 Git 管理一個輕量的「指針檔案」(.dvc 文件),指向真正存在 S3、GCS 或本地儲存的大型檔案。
實際工作流程大致這樣:
# 初始化 DVC(和 git init 配合)
git init && dvc init
# 把資料加入 DVC 追蹤
dvc add data/train.csv
# Git 只追蹤 .dvc 指針文件,不追蹤資料本身
git add data/train.csv.dvc
git commit -m "add training data v1"
# 把資料推到遠端儲存(S3、GCS、本地 NAS 等)
dvc push
這樣的架構讓你能做到:切換 git 分支的同時,用 dvc checkout 同步切換對應的資料版本。六個月後要重現某次實驗,只要 git checkout <commit> 再 dvc pull,就能還原當時的完整環境。
DVC 也支援建立 pipeline——把資料預處理、特徵工程、訓練、評估串成有向無環圖(DAG),每個步驟記錄輸入輸出,下次執行時自動跳過沒有變動的步驟。
MLflow:實驗追蹤的瑞士刀
MLflow 是目前最廣泛使用的 ML 實驗管理平台,由 Databricks 開源。它有四個主要元件:
MLflow Tracking:記錄每次實驗的參數、指標、模型檔案。只需要在訓練程式碼中加幾行:
import mlflow
with mlflow.start_run():
mlflow.log_param("learning_rate", 0.01)
mlflow.log_param("n_estimators", 100)
# ... 訓練程式碼 ...
mlflow.log_metric("accuracy", 0.923)
mlflow.log_metric("f1_score", 0.891)
mlflow.sklearn.log_model(model, "model")
這幾行程式碼執行後,MLflow UI 就會出現這次實驗的完整記錄,可以和其他實驗對比,看哪組超參數效果最好。
MLflow Projects:定義可重現的執行環境,包含 conda 環境設定或 Docker 容器定義,讓別人能一鍵重現你的訓練流程。
MLflow Models:統一的模型打包格式,讓同一個模型能以多種方式部署(REST API、批次推論、Spark UDF 等),不用為每種部署方式重寫代碼。
MLflow Model Registry:這是最關鍵的元件,管理模型的生命週期。
Model Registry:模型的生命週期管理
Model Registry 就像模型的人事管理系統。每個模型版本都有明確的狀態:
None → Staging(暫存):新訓練好的模型先進入 Staging,進行更嚴格的測試和評估,這時不對外服務,只在測試環境中驗證。
Staging → Production(生產):通過所有測試後,正式晉升為 Production 版本,由此模型對外提供服務。一個模型名稱下只能有一個 Production 版本(或由 Canary 策略分流)。
Production / Staging → Archived(封存):舊版本的模型封存保留,不再使用但紀錄還在,日後可以回滾或稽核。
這個流程讓部署決策有明確的責任人:是誰把哪個版本從 Staging 推到 Production,在什麼時間,原因是什麼,都要有記錄。
W&B vs MLflow:怎麼選?
Weights & Biases(W&B)是另一個流行的實驗追蹤工具,適合深度學習場景:視覺化做得非常好,支援 GPU 使用率監控、梯度直方圖、訓練曲線動態更新,還有「Sweeps」功能自動化超參數搜尋。
MLflow 的優勢在於完整的端對端生命周期管理,可以自建(self-hosted),不需要把資料傳到第三方服務,在資料安全性要求高的場景(醫療、金融)更合適。
一個實用的選擇準則:深度學習研究環境用 W&B,企業內部 ML 平台用 MLflow,兩者並不互斥也可以同時使用。
應用場景
| 場景 | 使用的工具 | 解決的問題 | 注意事項 |
|---|---|---|---|
| 多人協作的模型開發 | MLflow Tracking | 避免實驗結果各自記錄、難以比較 | 要建立統一的指標命名慣例 |
| 大型訓練資料集管理 | DVC + S3/GCS | 資料太大無法放 Git | 需要設定遠端儲存的存取權限 |
| 模型上線的審批流程 | Model Registry | 確保每個上線版本都有紀錄和授權 | 搭配 CI/CD 自動推送 Staging |
| 模型回滾 | Model Registry | 新版本出問題時快速切換回舊版 | 要確保舊版本的服務環境還在 |
| 合規性稽核 | MLflow + DVC | 金融/醫療法規要求模型可追溯 | 要記錄資料來源和處理過程 |
| 超參數搜尋 | W&B Sweeps / Optuna | 系統化比較幾十種超參數組合 | 記錄所有嘗試,不只是最好的 |
| 多個專案的模型共享 | Model Registry | 不同團隊能使用同一個基礎模型 | 要定義版本相容性規範 |
常見誤區
誤區 1:「我每次訓練都記錄在 Excel 就夠了」
手動記錄的問題不是「記錄本身」,而是可靠性和可操作性。當你在 Excel 裡記下「準確率 92%、學習率 0.01」,這份記錄缺少了太多關鍵資訊:用的是哪個版本的訓練程式碼?哪個時間點的資料快照?有沒有做資料擴增?隨機種子是什麼?
更嚴重的問題是,手動記錄非常容易出錯或遺漏。一個典型的場景是:你測試了 30 種超參數組合,只把「最好的那幾個」記進 Excel,那些看起來「失敗」的實驗被丟掉了。但六個月後,你換了一批資料重新實驗,想要從頭開始找最佳超參數,卻發現當初記錄不全,很多搜尋工作要重做。
系統性的實驗追蹤工具(MLflow、W&B)的價值在於:它會自動記錄所有執行,包括「失敗」的實驗,讓你能做全局的比較,也能從失敗中發現規律。
誤區 2:「資料不用做版本控制,反正訓練資料不會變」
「訓練資料不會變」幾乎是不可能的。資料會因為各種原因更新:資料庫新增了記錄、標注工程師修正了標籤錯誤、資料清洗腳本改了一個處理邏輯、某個第三方資料來源更新了欄位格式。
如果你沒有資料版本控制,你根本不知道今天的訓練結果和上次相比,是因為模型改進了,還是因為資料變了。更危險的是,在需要重現某次模型行為(例如監管機關要求解釋某個重要決策)時,如果找不回當時的資料快照,你完全沒辦法重現那個模型的決策過程。
資料版本控制也不一定要複雜。最低限度,你應該記錄每次訓練用的資料集的 hash 值(SHA-256),這樣至少能驗證「我現在拿到的資料和當初用的是不是一樣的」。DVC 幫你把這件事自動化了。
誤區 3:「Model Registry 是大公司才需要的,我們只有兩個模型」
兩個模型、三個工程師的小團隊,同樣會遇到「線上跑的是哪個版本」的問題。Model Registry 不是關於規模,而是關於清晰的責任邊界。
沒有 Registry 的場景:工程師 A 訓練了一個新模型,傳給工程師 B 說「用這個上線」,B 把檔案複製到伺服器。一週後,模型表現異常,沒有人確定現在跑的是 A 傳的那個,還是 B 之前調整過的另一個版本。
有 Registry 的場景:工程師 A 訓練後,把模型推送到 Registry 並標記為 Staging。工程師 B 在 Registry 上確認測試通過後,把版本狀態改為 Production。部署系統自動拉取最新的 Production 版本。整個流程有完整日誌,誰做了什麼、什麼時候做的,都清清楚楚。
小練習
練習 1:設計實驗追蹤規範
假設你的團隊要開始用 MLflow 追蹤實驗,設計一份「實驗記錄規範」,列出每次訓練實驗必須記錄的項目:
- 至少要記錄哪些參數(Parameters)?
- 至少要記錄哪些指標(Metrics)?
- 需要儲存哪些 Artifact(模型、圖表等)?
- 實驗名稱的命名規則是什麼?
練習 2:模型生命週期決策
你的團隊有以下狀況,請決定每個模型版本應該處於 Model Registry 的哪個狀態(None/Staging/Production/Archived),並說明理由:
- 版本 v1.2:上線三個月,最近發現準確率開始下滑,已被 v1.3 取代
- 版本 v1.3:目前線上服務中,表現穩定
- 版本 v2.0:剛用新演算法訓練完,離線評估比 v1.3 高 5%,尚未上線測試
- 版本 v2.0-beta:v2.0 的輕量版,為低資源設備設計,還在測試中