共 10 講
M09.01
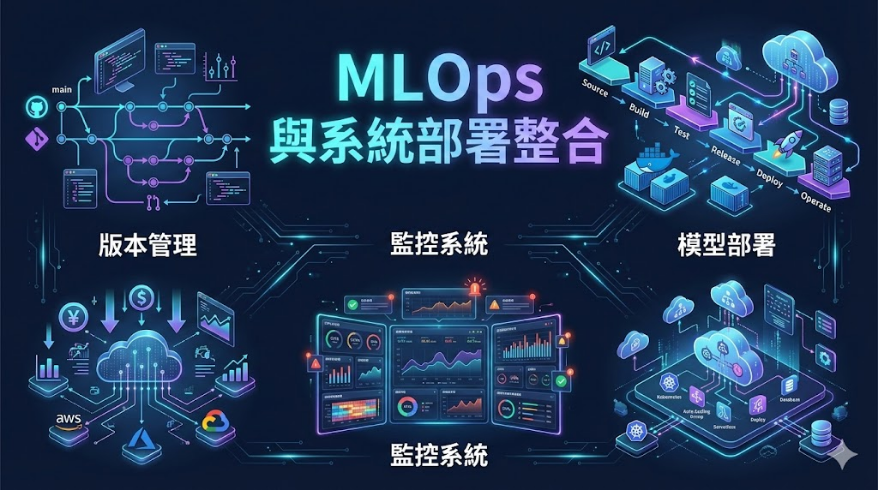
MLOps 概覽:從實驗到產品的橋樑
訓練出一個好模型只是起點 — 讓它在真實世界穩定運作才是挑戰的開始
M09.02
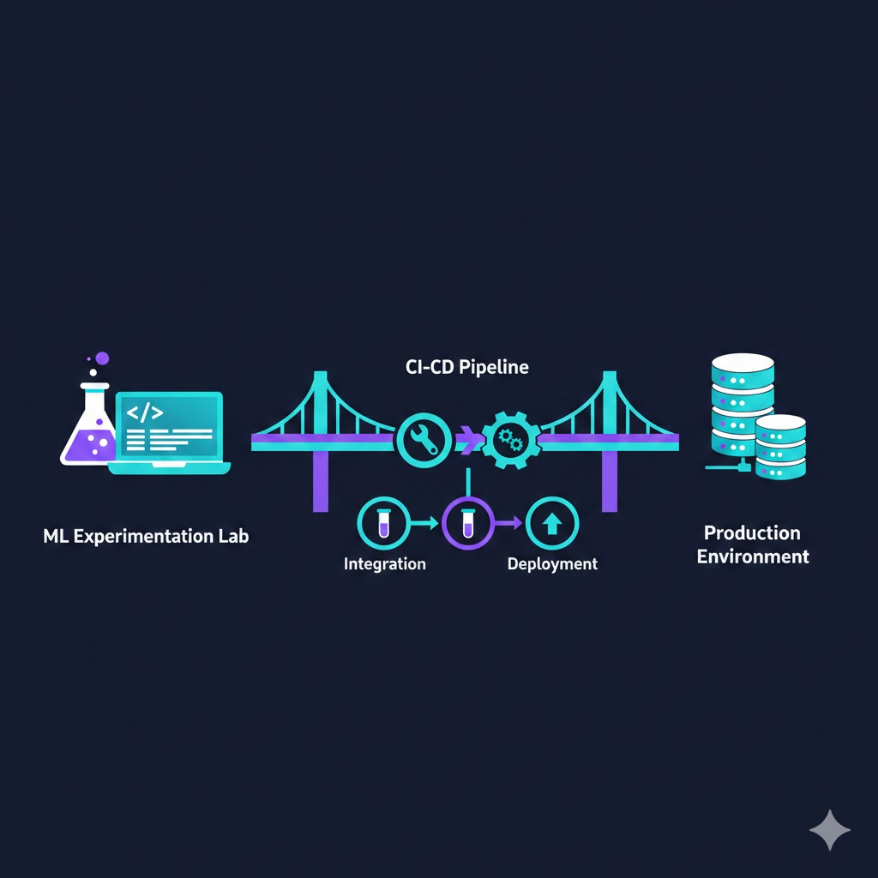
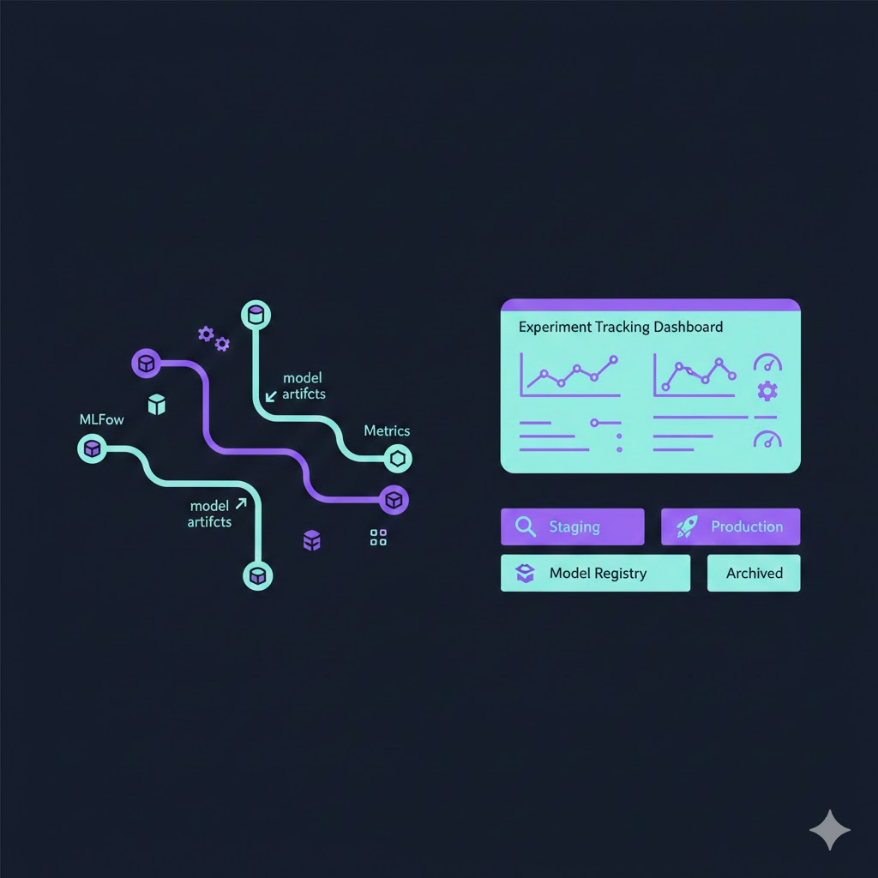
模型版本管理:讓實驗可重現、讓部署有憑有據
你還在用 model_v2_final_REALLY_FINAL.pkl 命名嗎?是時候認真對待模型版本管理了
M09.03
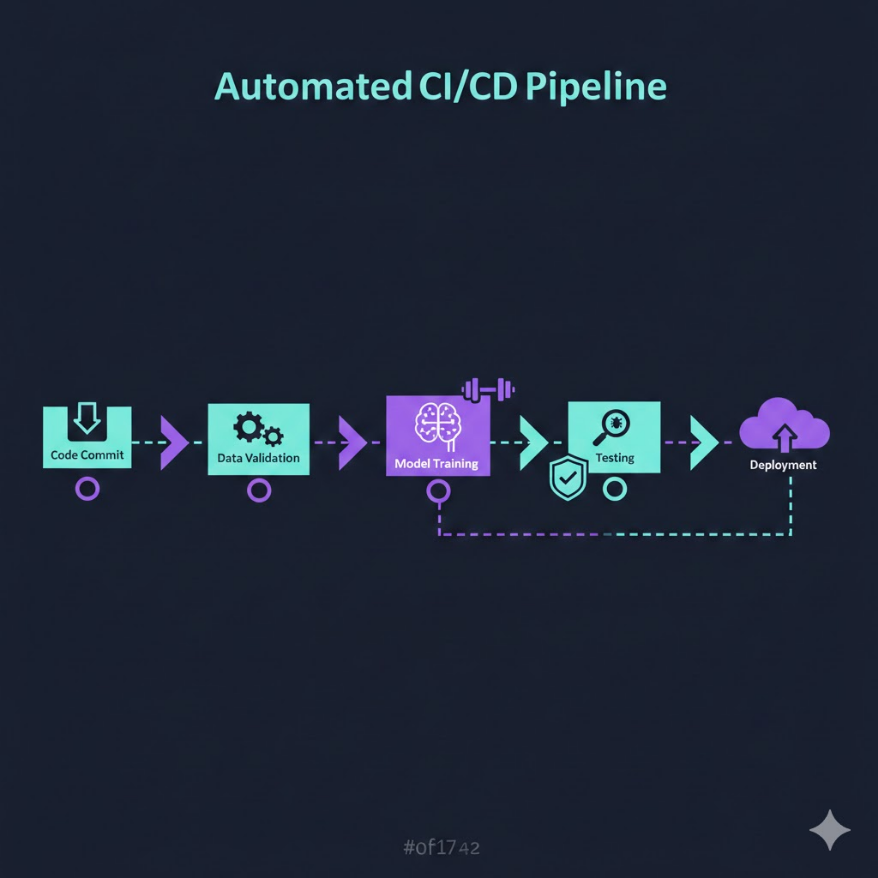
CI/CD for ML:讓模型更新像軟體發布一樣可靠
自動化不只是懶人的工具 — 在 ML 系統中,它是確保品質和可重現性的唯一方式
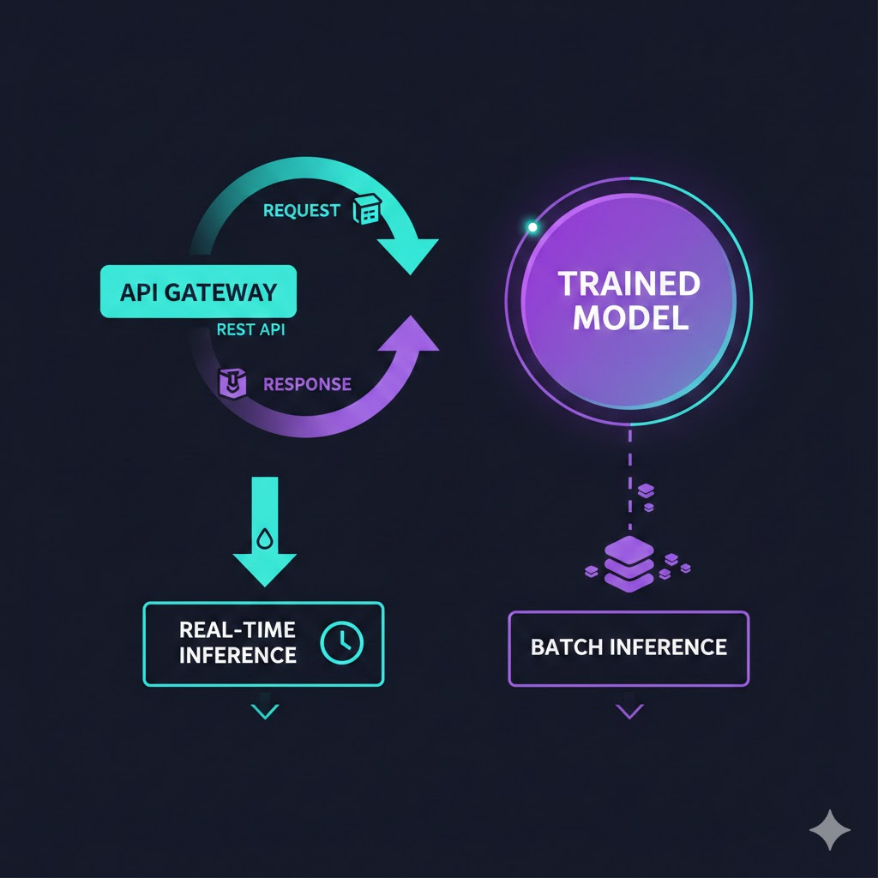
M09.04
模型服務化:讓 AI 模型變成可呼叫的服務
訓練好的模型如果沒辦法被其他系統使用,它就只是一個孤立的 .pkl 檔

M09.05
容器化與雲端部署:讓模型在任何地方都能跑
『在我的電腦上可以跑』已經不夠了 — 容器化讓環境一致,雲端讓規模彈性
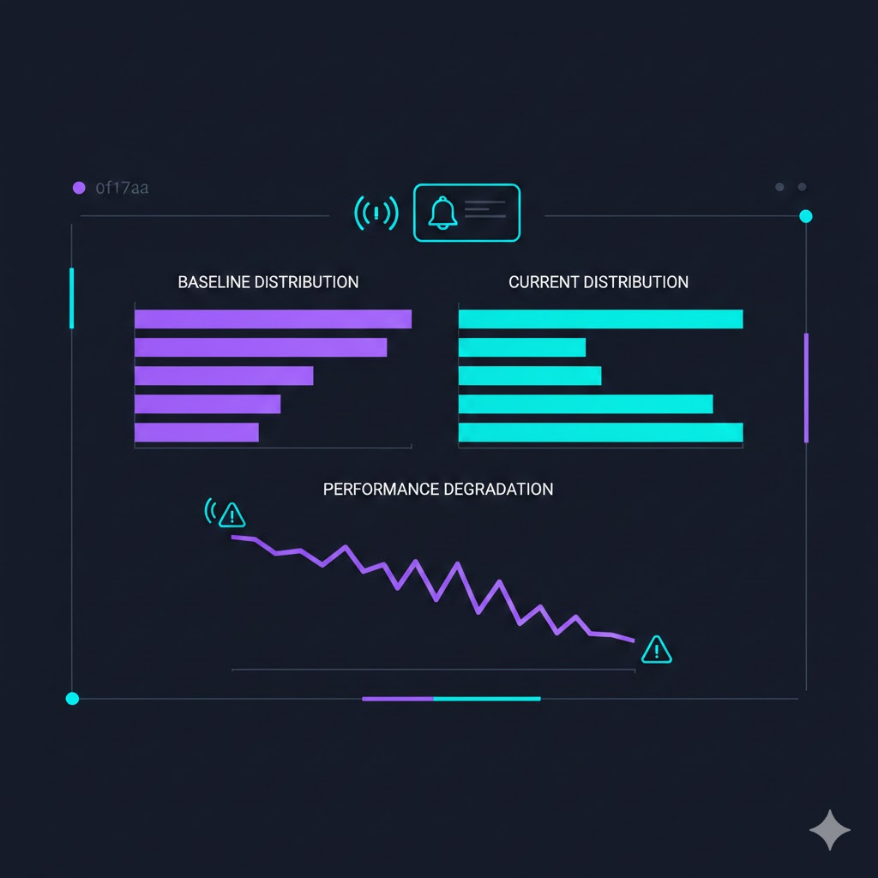
M09.06
模型監控與觀測:讓 AI 系統持續健康運作
部署只是開始 — 真正的挑戰是確保模型在真實世界不悄悄變差
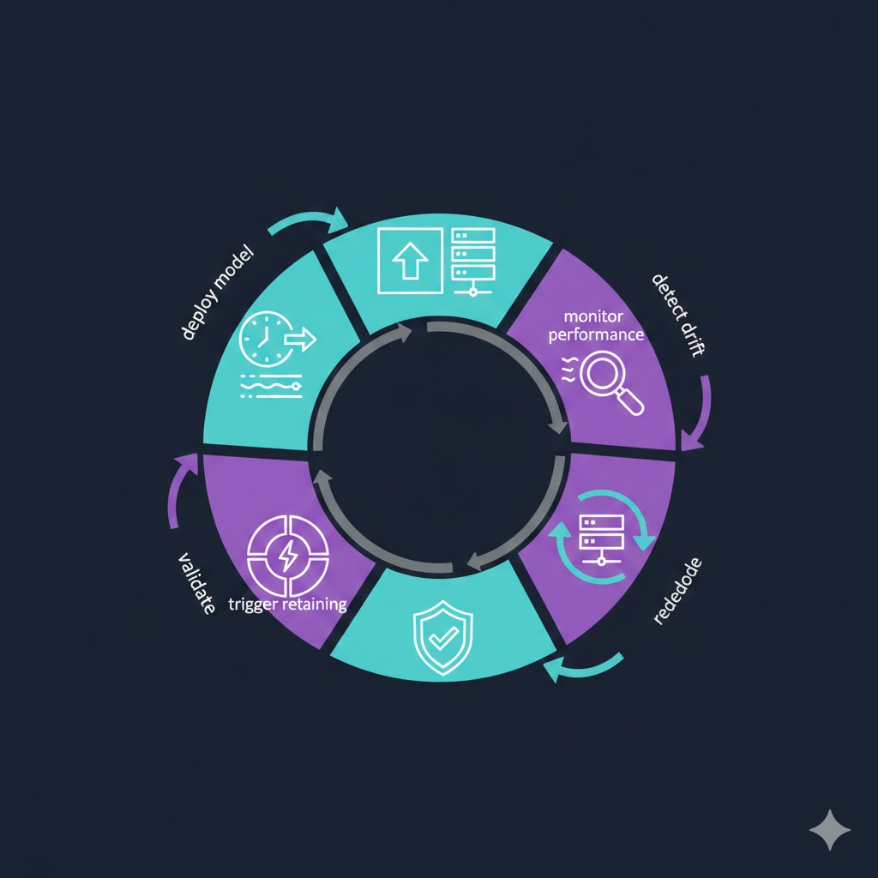
M09.07
模型重訓練策略:讓 AI 系統跟上世界的腳步
不是訓練一次就永遠好用 — 聰明的重訓練策略才是長期競爭力

M09.08
Edge AI 與端側部署:讓 AI 在裝置上跑起來
不是所有 AI 都需要雲端 — 在裝置端跑 AI 才是真正改變世界的方式
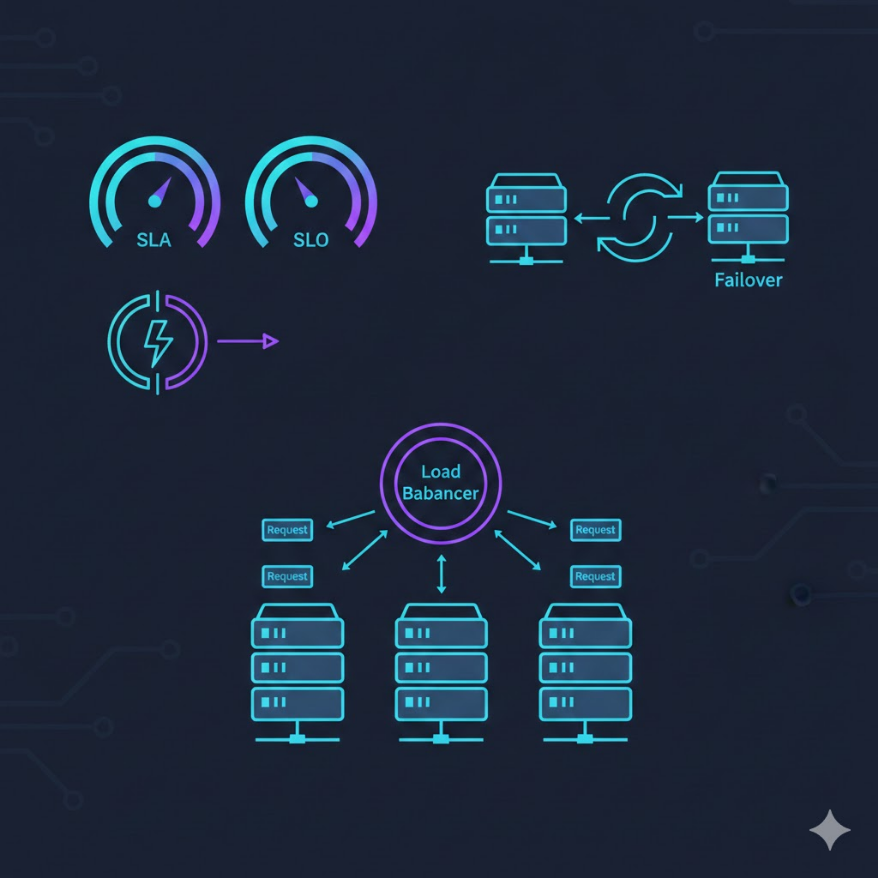
M09.09
AI 系統的可靠性工程:讓 AI 服務穩如磐石
準確率 99% 但掛掉 10% 的時間 — 可靠性才是 AI 上線的真正門檻
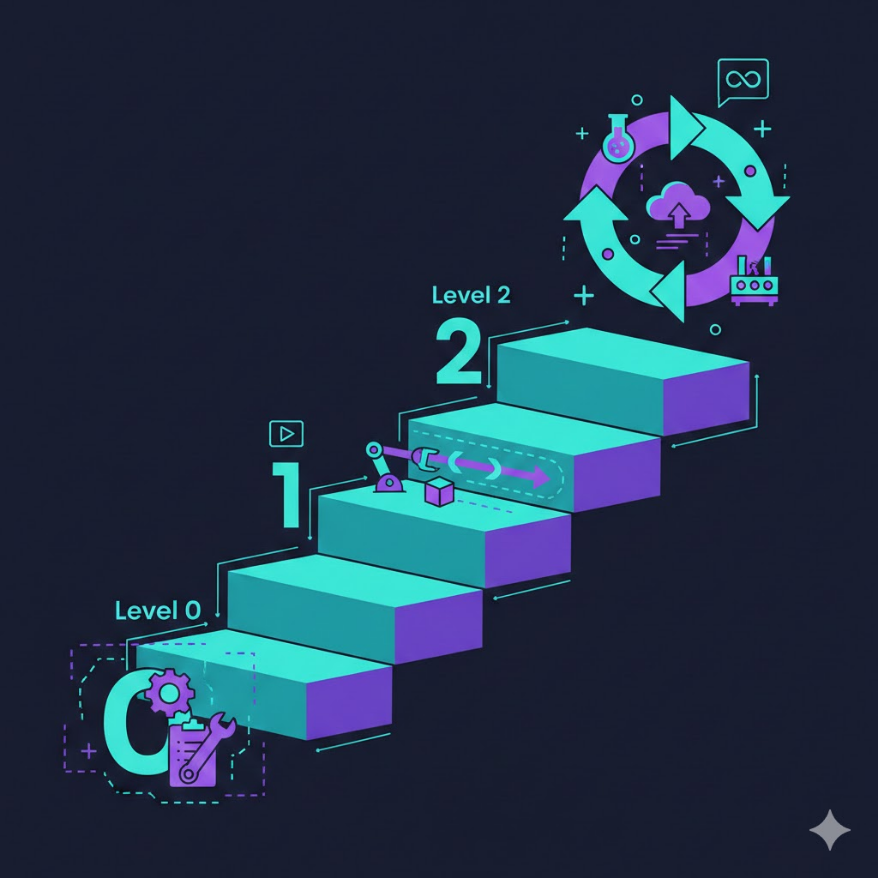
M09.10
MLOps 成熟度模型:從「跑得動」到「跑得好」的組織旅程
一個模型上線不難 — 難的是讓整個組織持續、可靠、有效率地做 AI