M09.03|CI/CD for ML:讓模型更新像軟體發布一樣可靠
自動化不只是懶人的工具 — 在 ML 系統中,它是確保品質和可重現性的唯一方式
本講學習重點
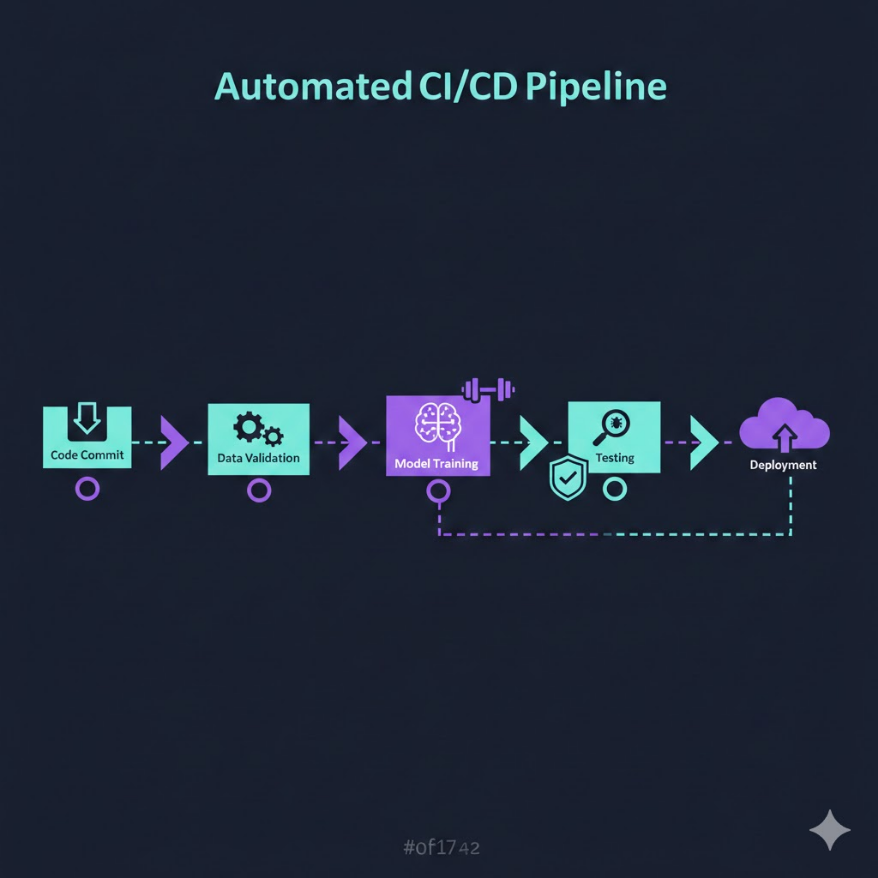
ML CI 多了資料驗證、模型訓練、模型評估三個步驟
模型測試分三層:程式碼測試、模型行為測試、業務指標測試
金絲雀發布 = 先把 5-10% 流量導到新模型,確認沒問題再全量
Great Expectations 可以定義資料的「期望規格」並自動驗證
影子測試 = 新舊模型同時跑,只記錄新模型結果不實際使用
回滾機制要在部署前設計好,不能等出事才想
測試資料要和訓練資料分開管理,避免資料洩漏
🎙️ Podcast(中文)
一句話搞懂
ML 的 CI/CD 就是為模型的「從訓練到上線」這條路設置一系列自動化關卡:程式碼一提交,系統就自動執行資料驗證、模型訓練、品質測試,全部通過才能推進到下一關,不符合標準的模型會被自動攔截,確保每次上線的模型都有基本的品質保障,而不是靠人工肉眼檢查。
白話解說
CI/CD 的基本概念:從軟體世界借來的智慧
在傳統軟體開發中,CI/CD 已經是標準實踐:
持續整合(CI,Continuous Integration):開發者每次把程式碼推到 Git,就自動觸發一系列測試——單元測試、整合測試、靜態分析。如果任何一個測試失敗,這個改動就被「拒絕」,不能合入主分支。目的是讓問題在第一時間被發現,而不是積累到上線前才爆發。
持續交付/部署(CD,Continuous Delivery/Deployment):通過 CI 測試的程式碼,可以自動部署到測試環境,甚至自動推上生產環境。「持續交付」代表可以隨時部署,但需要人工確認;「持續部署」代表完全自動化,通過測試就自動上線。
ML 系統需要這套機制,但挑戰在於:模型不只是程式碼。模型的行為取決於訓練資料和模型參數,單純測試程式碼是否能跑起來,完全不能保證模型的品質。這就是為什麼 ML 的 CI/CD 需要額外的思考。
ML CI/CD 的獨特挑戰
標準軟體的 CI 流程大概是:git push → 執行測試 → 通過 → 可以合入。
ML 系統的 CI 流程要複雜得多,因為中間插入了「訓練」這個耗時且不確定的步驟:
git push
→ 程式碼測試(快,秒級)
→ 資料驗證(確認資料格式、分布是否正常)
→ 模型訓練(慢,可能幾小時)
→ 模型評估(跑測試集、計算指標)
→ 模型品質閾值檢查(準確率是否達標?效能是否符合 SLA?)
→ 通過所有關卡 → 推送到 Model Registry 的 Staging
這個流程帶來幾個特殊問題:
訓練步驟很慢:傳統 CI 測試幾秒到幾分鐘,但模型訓練可能需要幾個小時。這代表 CI 流程的設計要考慮資源調度和費用問題——不能每次 git push 都觸發全量重新訓練。
測試什麼是「通過」?:程式碼測試有明確的通過/失敗。模型評估的結果是個數字(例如 F1 = 0.87),你要設定一個「閾值」(threshold),這個閾值的選擇本身就是業務決策。
訓練的隨機性:ML 訓練帶有隨機性(亂數種子、資料打亂順序),相同的設定訓練兩次,結果可能略有不同。CI 系統要能容忍這種「合理的隨機性」,不能因為指標差了 0.001 就判定失敗。
資料驗證:CI/CD 中最容易被忽略的環節
在 ML 系統中,「垃圾進、垃圾出」(Garbage In, Garbage Out)是鐵律。資料品質問題往往比模型問題更難發現,卻危害更大。
一個完整的資料驗證應該檢查:
Schema 驗證:每個欄位的資料型態是否正確?是否有不應該出現的欄位?欄位數量有沒有改變?
統計分布驗證:各欄位的均值、標準差、最大最小值是否在合理範圍內?類別型變數的類別分布有沒有異常?
資料品質驗證:缺失值比例是否超過閾值?重複記錄比例?異常值比例?
業務規則驗證:例如年齡不能是負數、電話號碼長度要符合格式、時間序列不能有未來的時間戳記。
Great Expectations 是一個廣泛使用的資料驗證框架,你可以用 Python 定義「期望」(Expectations),像是:
# 定義對資料的期望
expect_column_values_to_be_between("age", min_value=0, max_value=120)
expect_column_values_to_not_be_null("customer_id")
expect_column_proportion_of_unique_values_to_be_between("category", 0.001, 0.1)
把這些驗證嵌入 CI pipeline,一旦資料不符合期望,pipeline 就中止,自動通知相關人員。
三層模型測試:從程式碼到業務
完整的 ML 測試應該分三個層次:
第一層:程式碼測試。這和傳統軟體一樣,測試你的訓練腳本、特徵工程函數、預處理邏輯的正確性。例如:測試特徵標準化函數的輸出範圍是否在 [-3, 3] 之間、缺值處理函數是否真的把遺漏值填補了。這層測試快速,幾秒內完成。
第二層:模型行為測試。不只看整體指標,還要測試模型在特定條件下的行為是否符合業務常識。例如:「高收入客戶的信用評分不應該比低收入客戶低太多」、「把所有特徵都設為 0 時,模型不應該 crash 而是要輸出一個合理的預設值」、「對模型輸入做微小擾動(例如把 age=30 改成 30.001),輸出不應該有劇烈跳動」。
第三層:業務指標測試。在保留的測試集上驗證整體的業務指標是否達標。這是「通過/失敗」的最後一道關卡,設定的閾值要和業務方達成共識,例如「F1 score 不低於 0.85,推論延遲不超過 100ms」。
部署策略:如何安全地把新模型推上線
即使通過了所有測試,把新模型推上生產環境還是需要謹慎。幾種常用的部署策略:
藍綠部署(Blue-Green Deployment):同時維護兩個完全相同的生產環境,一個是「藍」(現在的舊版本),一個是「綠」(新版本)。驗證完畢後,把流量一次性從藍切到綠。回滾時只需要把流量切回藍。好處是切換乾淨,壞處是需要兩倍資源。
金絲雀發布(Canary Release):名稱來自礦工帶金絲雀進礦坑探測毒氣的典故——先把一小部分流量(例如 5%)導到新模型,觀察 24-48 小時,確認沒有問題後再逐步增加到 20%、50%、100%。好處是風險可控,萬一新模型有問題,影響的只有少數用戶。
影子測試(Shadow Testing):新舊模型同時接收相同的請求,但只有舊模型的結果會被實際使用,新模型的結果只記錄下來進行比較。這讓你在零風險的情況下,觀察新模型在真實流量下的表現是否和離線評估一致。
A/B 測試:把用戶隨機分成兩組,A 組看舊模型結果,B 組看新模型結果,比較兩組的業務指標(點擊率、轉換率等)差異,確認新模型確實帶來業務改善。
應用場景
| 場景 | 觸發 CI/CD 的事件 | 關鍵測試項目 | 部署策略 |
|---|---|---|---|
| 特徵工程程式碼修改 | git push | 程式碼測試 + 資料驗證 + 全量重訓 | 金絲雀 5% → 逐步擴大 |
| 定期排程重訓(每週) | 排程觸發 | 資料驗證 + 模型評估 + 指標閾值 | 自動晉升 Staging,人工確認 Production |
| 新資料批次到達 | 資料 pipeline 觸發 | 資料 schema 驗證 + 分布驗證 | 增量訓練或全量重訓視場景而定 |
| 上線指標下滑告警 | 監控系統觸發 | 緊急診斷 + 快速回滾或重訓 | 優先考慮回滾穩定版本 |
| 模型架構大改版 | PR 合入主分支 | 完整三層測試 + 影子測試 | 藍綠部署 + 較長觀察期 |
| 超參數自動調優結果 | AutoML 完成觸發 | 評估最優結果是否優於線上版本 | A/B 測試確認業務改善 |
常見誤區
誤區 1:「有了 CI/CD,每次都自動部署就好,不需要人工介入」
全自動化部署(Continuous Deployment)在傳統軟體中是成熟的實踐,但在 ML 系統中需要更謹慎。
原因一:ML 模型的「正確性」很難完全用自動化測試覆蓋。一個模型可能通過所有測試指標,但在某些特定的邊緣案例上有嚴重問題,例如對特定族群的系統性偏差。這類問題需要人工審查和業務常識判斷。
原因二:ML 模型更新有業務風險。如果是推薦系統,一個糟糕的模型可能在幾小時內影響數百萬用戶的體驗;如果是信用評分,錯誤的模型可能造成不公平的拒貸。這些風險需要人工確認,不宜完全自動化。
建議的做法是「持續交付」而非「持續部署」:CI 流程自動把通過測試的模型推到 Staging,但 Production 的最終部署需要工程師或業務負責人確認。這只需要一個按鈕,不是重大障礙,但能大幅降低風險。
誤區 2:「只要監控準確率,就能知道模型是否健康」
準確率(accuracy)是最常見、也最容易被誤用的監控指標。它有幾個嚴重盲點:
首先,準確率的計算需要「真實標籤」,但在很多場景中,真實標籤有延遲。例如信用評分模型,你今天預測的違約率,要等 3-6 個月後才知道客戶是否真的違約。在這段時間內,你無法用準確率來監控模型。
其次,在不平衡資料集上,準確率是誤導性的指標。如果 99% 的樣本是正常,1% 是詐騙,一個「什麼都說正常」的模型準確率高達 99%,但完全沒用。
更完整的監控應該包括:輸入特徵的分布(是否有資料漂移)、預測分布的變化(例如「高風險」類別的比例是否異常上升)、業務指標(轉換率、點擊率、退款率等)。這些指標不依賴真實標籤,可以即時監控。
誤區 3:「測試通過了,就代表模型在所有情境下都好」
測試集的代表性決定了測試的意義。如果你的測試集和訓練集都來自同一個時間段的資料,你的測試只能告訴你「模型對這個時期的資料表現好」,無法保證對未來資料也好(這就是為什麼有「時序切分」這個概念——訓練集用早期資料,測試集用晚期資料)。
另一個常見問題是「數據洩漏」(data leakage):訓練資料中混入了測試時不可能拿到的未來資訊。例如,預測客戶是否會流失,但特徵中包含了「取消訂閱前最後一次登入時間」——這個特徵在預測時根本不存在。洩漏讓模型在測試集上表現虛高,上線後立刻打回原形。
測試應該模擬真實部署條件:測試集來自不同時間段、不同地域、不同用戶群,才能發現泛化能力的問題。
小練習
練習 1:設計 ML CI Pipeline
你正在負責一個「電商商品類別分類器」,根據商品標題自動分類。現在要設計這個模型的 CI pipeline。請列出:
- 觸發條件:什麼情況下應該觸發 CI?(至少 3 種)
- 每個階段的工作:從 git push 到最終確認,應該有哪些自動化步驟?
- 通過/失敗條件:每個階段的「通過標準」是什麼?
練習 2:選擇部署策略
以下是三個不同的場景,請為每個場景選擇最適合的部署策略,並說明理由:
A. 醫療輔助診斷 AI:幫助醫生篩查 X 光片中的肺炎跡象,誤判可能導致延誤治療
B. 新聞 App 的個人化推薦:根據用戶閱讀歷史推薦文章,更新模型準確度提升 3%
C. 工廠品管視覺檢測:自動偵測生產線上的瑕疵品,這是第一次從人工改為 AI