M09.04|模型服務化:讓 AI 模型變成可呼叫的服務
訓練好的模型如果沒辦法被其他系統使用,它就只是一個孤立的 .pkl 檔
本講學習重點
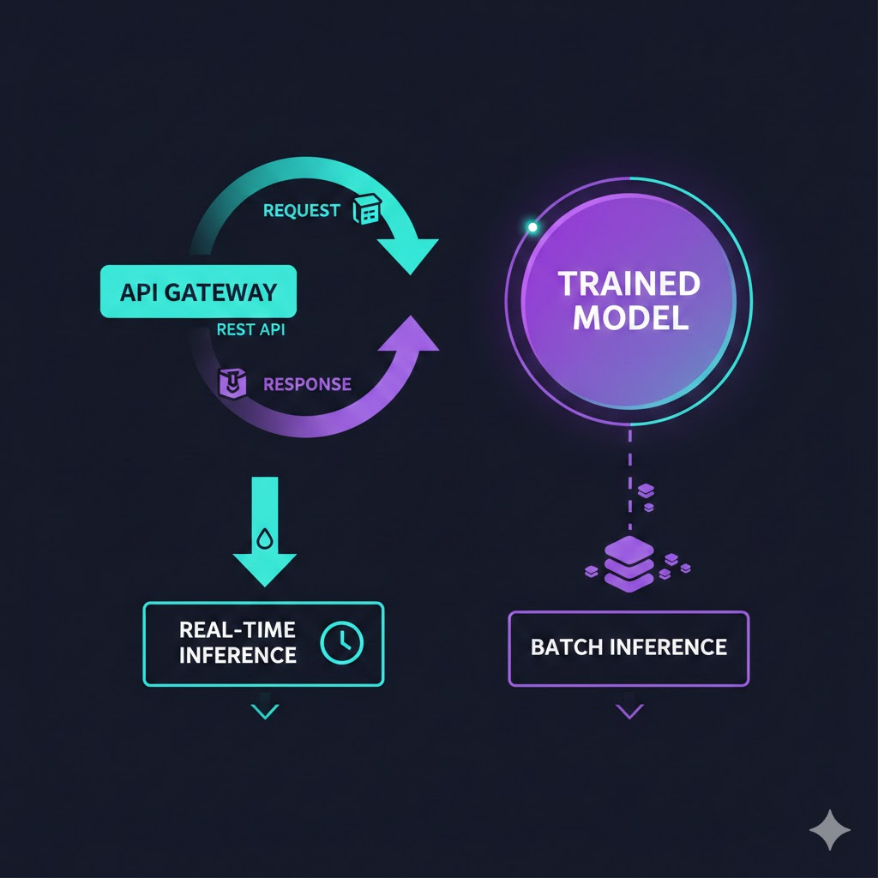
REST API = JSON over HTTP,通用但相對慢;gRPC = Protobuf,高效能但複雜
即時推論 = 收到請求立刻回應(毫秒級);批次推論 = 積累後批量處理(分鐘到小時)
效能優化:模型量化(FP32→INT8)、模型蒸餾、ONNX 加速、批次請求合併
FastAPI 適合快速原型;TF Serving/Triton 適合生產高吞吐量
SLA 常見指標:p99 延遲 < 200ms、可用性 99.9%(每月停機 < 43 分鐘)
BentoML 和 Seldon Core 是高層次抽象,簡化模型部署複雜度
模型版本 A/B 測試可以在服務層實現,不需要改動業務邏輯
🎙️ Podcast(中文)
一句話搞懂
模型服務化就是把訓練好的機器學習模型「包裝」成一個可以接受請求、回傳預測結果的服務——就像餐廳廚師(模型)和用餐客人(呼叫方)之間,需要服務生(API 服務層)來傳遞點單和上菜,讓模型能夠被外部系統以標準化的方式呼叫,而不是直接把模型原始碼複製到每個用到它的地方。
白話解說
為什麼需要「服務化」?
想像你訓練好了一個銷售預測模型,存成了一個 model.pkl 檔案。現在業務系統要使用這個預測——問題來了:
業務系統是 Java 寫的,你的模型是 Python 訓練的。Java 不能直接載入 Python 的 pickle 檔。就算語言一樣,直接把模型嵌入業務系統也是很糟糕的設計:每次模型更新都要重新部署業務系統,訓練環境的 Python 套件版本衝突問題會讓你頭痛不已,而且模型沒辦法被多個系統同時使用。
解決方案是把模型獨立包裝成一個服務(Service):這個服務運行在獨立的環境裡,對外暴露一個標準化的介面(API),任何人只要發送正確格式的請求,就能拿到預測結果。模型更新時,只需要更新這個服務,不需要動到呼叫它的所有系統。
這就是微服務架構的精神:把模型從一個靜態檔案,變成一個可以獨立擴展、獨立更新、被多方呼叫的動態服務。
REST API vs gRPC:兩種通訊語言
模型服務最常使用兩種通訊協定:
REST API(RESTful HTTP API):使用你熟悉的 HTTP 協定,資料格式是 JSON(純文字)。呼叫方式就像瀏覽網頁:發一個 POST 請求到特定 URL,附帶 JSON 格式的輸入資料,收到 JSON 格式的預測結果。
# REST API 呼叫範例
curl -X POST http://model-service/predict \
-H "Content-Type: application/json" \
-d '{"age": 35, "income": 80000, "tenure_months": 24}'
# 回傳
{"churn_probability": 0.23, "prediction": "low_risk"}
優點:所有程式語言都能呼叫,除錯容易(可以直接在瀏覽器測試),生態系成熟。 缺點:JSON 序列化/反序列化有開銷,HTTP/1.1 每次請求都有額外的 header 資料,高頻呼叫時效能相對差。
gRPC(Google Remote Procedure Call):Google 開發的高效能 RPC 框架,使用 Protobuf(Protocol Buffers)作為資料序列化格式。Protobuf 是二進位格式,比 JSON 更緊湊(同樣資料量小 3-10 倍),解析速度更快。gRPC 還支援雙向串流,可以同時傳送和接收資料流。
優點:效能顯著優於 REST(延遲更低、吞吐量更高)、支援串流傳輸、強型別定義(API schema 明確)。 缺點:設定相對複雜,需要生成客戶端代碼,在瀏覽器中使用需要額外的 proxy,debug 比 JSON 麻煩。
選擇準則:如果是面向終端用戶的 API,或者需要第三方集成,用 REST。如果是微服務之間的內部通訊,高頻呼叫(每秒超過幾千次),用 gRPC。
即時推論 vs 批次推論:根據業務需求選擇
即時推論(Online/Real-time Inference):用戶或系統發送請求,模型在幾毫秒到幾百毫秒內回傳結果。這是最直觀的模式,適合:
- 推薦系統(用戶打開 App,立刻看到個人化推薦)
- 詐騙偵測(每筆交易發生時,即時判斷是否異常)
- 客服聊天機器人(用戶輸入問題,立刻得到回應)
- 醫療輔助診斷(醫生上傳影像,幾秒內得到初步判讀)
挑戰:需要低延遲的模型(複雜模型需要優化)、服務要能應對流量波峰(需要自動擴展)、SLA 要求高(99.9% 可用性)。
批次推論(Batch Inference):積累一批請求後,一次性批量處理,結果寫入資料庫供後續使用。適合:
- 每日信用評分更新(每天凌晨批量計算所有客戶的信用分數)
- 推薦清單預計算(提前計算每個用戶的推薦清單,存入快取)
- 報表生成(每週計算銷售預測報表)
- 大量影像/文件的離線處理
優點:可以充分利用 GPU 的批次計算效率,不需要低延遲服務,成本通常更低。 缺點:結果有延遲(不是即時的),對突發的即時需求無法回應。
混合模式:很多系統同時使用兩者。例如推薦系統:預先批次計算每個用戶的基礎推薦清單存入快取(批次),當用戶真正打開 App 時,用即時推論根據當下情境微調推薦(即時)。
主流的模型服務框架
FastAPI(快速原型與中小規模):基於 Python 的現代 Web 框架,能在幾十行程式碼內把模型包裝成 REST API:
from fastapi import FastAPI
import joblib
app = FastAPI()
model = joblib.load("model.pkl")
@app.post("/predict")
def predict(data: dict):
features = [[data["age"], data["income"], data["tenure"]]]
prediction = model.predict_proba(features)[0][1]
return {"churn_probability": float(prediction)}
優點:開發速度快,Python 生態系直接使用,自動生成 API 文件(Swagger UI)。 缺點:單進程 Python 服務的吞吐量有限,不內建模型版本管理。
TensorFlow Serving / TorchServe:分別是 TensorFlow 和 PyTorch 官方的生產級服務框架。支援模型熱更新(不停機更新模型)、多版本並存、gRPC 和 REST 兩種介面、GPU 加速。適合大規模生產部署。
NVIDIA Triton Inference Server:NVIDIA 開發的高效能推論伺服器,支援幾乎所有模型格式(TensorFlow、PyTorch、ONNX、TensorRT),能自動合併多個請求進行批次處理(Dynamic Batching),最大化 GPU 使用率。
BentoML:高層次的模型服務抽象,讓你專注在模型邏輯,它幫你處理 API 框架、容器化、部署的細節。適合不想深入底層但需要生產級部署的場景。
推論效能優化:讓模型跑得更快
當模型服務成為系統瓶頸,以下是常用的優化手段:
模型量化(Quantization):把模型參數從 32 位元浮點數(FP32)轉換成 16 位元(FP16)或 8 位元整數(INT8)。這能讓模型大小縮小 2-4 倍,推論速度提升 2-4 倍,準確率只有微小損失(通常 < 1%)。是最常用的加速手段。
ONNX 轉換:ONNX(Open Neural Network Exchange)是跨框架的模型格式。把 PyTorch 或 TensorFlow 模型轉成 ONNX 格式,再用 ONNX Runtime 做推論,通常能提升 1.5-3 倍的速度,且不依賴原本的訓練框架。
動態批次(Dynamic Batching):把在短時間內到達的多個請求合併成一個批次,一起送進 GPU 計算。GPU 最擅長的就是並行計算,單個請求的 GPU 使用率可能只有 5%,合成批次後可以提升到 80% 以上。
快取(Caching):對相同或高度相似的輸入,直接返回快取的結果,不需要重跑模型。適合推薦系統、分類結果等輸出相對穩定的場景。
應用場景
| 場景 | 推論模式 | 通訊協定 | 推薦框架 | 關鍵 SLA |
|---|---|---|---|---|
| 電商即時推薦 | 即時 | REST | FastAPI / BentoML | p99 延遲 < 100ms |
| 金融詐騙偵測 | 即時 | gRPC | TensorFlow Serving | p99 延遲 < 50ms |
| 夜間批次信用評分 | 批次 | N/A(直接寫 DB) | 自訂 Python 腳本 | 在營業前完成 |
| 醫療影像分析 | 即時 | REST | Triton Inference Server | p99 延遲 < 2000ms |
| NLP 客服機器人 | 即時 | REST/WebSocket | FastAPI + GPT API | p99 延遲 < 500ms |
| 工廠影像品管 | 即時(邊緣) | gRPC | Triton(TensorRT) | p99 延遲 < 20ms |
| 廣告點擊率預測 | 即時(超高QPS) | gRPC | TorchServe + 量化 | p99 延遲 < 30ms |
常見誤區
誤區 1:「直接把模型嵌入業務程式碼就好,不需要獨立服務」
這個做法在概念驗證(PoC)階段可以接受,但一旦要進入生產環境,問題就會接踵而來。
首先是依賴衝突:ML 模型常常有特定版本的 Python 套件需求(例如 scikit-learn 1.2.3、numpy 1.24.0),這些可能和業務系統的需求衝突,導致難以解決的版本地獄。
其次是更新問題:模型需要定期更新,如果嵌入業務程式碼,每次更新模型都要重新部署整個業務系統,增加了風險和工作量。
第三是資源競爭:模型推論(尤其是深度學習模型)消耗大量 CPU 和記憶體。把它嵌入業務服務會讓業務服務的資源不可預期地被佔用,影響正常業務的穩定性。
把模型獨立成服務,才能讓模型和業務系統各自獨立擴展、各自部署、各自優化。
誤區 2:「只要模型準確率高,推論速度不重要」
推論延遲(inference latency)直接影響用戶體驗,進而影響業務指標。Google 的研究顯示,網頁載入時間每增加 100ms,轉換率下降 7%。電商推薦如果要花 2 秒才能給出結果,很多用戶早就放棄等待了。
SLA(Service Level Agreement,服務等級協議)需要根據業務場景明確定義:互動式 UI 的回應時間通常要求在 200ms 以內,後端微服務之間的呼叫可以允許稍長。「p99 延遲」(第 99 百分位延遲)是更重要的指標——它代表 99% 的請求都在這個時間內完成,那 1% 的慢請求可能讓用戶感到失望。
當模型的推論速度不夠快,需要系統性地尋找瓶頸:是模型本身太複雜(考慮量化或蒸餾)、是資料前處理太慢(考慮 C++ 實作或向量化)、是 I/O 瓶頸(考慮快取或非同步處理),而不是一味堆更多機器。
誤區 3:「批次推論比即時推論簡單,不需要特別設計」
這個誤解低估了批次推論的複雜性。一個生產級的批次推論系統需要考慮:
容錯機制:處理幾百萬筆資料的批次任務,中途可能因為任何原因中斷(機器重啟、記憶體不足、資料格式錯誤)。沒有斷點續傳機制,每次失敗都要從頭開始,浪費大量計算資源。
資源調度:批次任務通常在離峰時段(深夜)執行,但執行時間不可預測。如果批次任務沒在規定時間前完成(例如信用評分要在隔天開盤前完成),業務就會出問題。需要合理的資源規劃和超時告警。
資料一致性:批次推論通常從資料庫讀取大量資料,但資料庫在批次執行期間可能有新的寫入。要確認批次任務用的是哪個時間點的快照,避免「看了一半的資料」。
小練習
練習 1:設計模型服務 API
你的團隊訓練了一個「商品評論情感分析模型」,輸入是評論文字,輸出是情感標籤(正面/中性/負面)和信心分數。請設計這個服務的 REST API:
- 設計 POST
/analyze的請求和回應 JSON 格式 - 設計 GET
/health的健康檢查回應 - 考慮:需要支援批次請求嗎?(一次送入多筆評論)
- 定義合理的 SLA(延遲要求、可用性要求)
練習 2:選擇服務架構
以下兩個場景,請分別設計合適的服務架構:
A. 電商平台的商品圖片分類服務:賣家上傳圖片時,自動判斷商品類別(書籍、3C、衣物等),準確率要高,但每次只有一張圖,允許 2 秒的延遲。
B. 銀行的每日風險評估系統:每天凌晨需要對 500 萬筆帳戶計算風險分數,在早上 8 點前全部完成並寫入資料庫,供信貸人員查詢。